Artificial Intelligence
Artificial Intelligence, the ability of a machine to demonstrate intelligence, was founded as an academic discipline in 1956. Shortly after, it has experienced waves of optimism, followed by periods of diminished funding between the 70’s and 80’s, the so-called AI winter. New research, methodologies, and approaches in the years to come re-ignited optimism. Modern AI architectures such as those within the context of deep learning continued to evolve. With time, research naturally turned to more complex problems such as those in unsupervised learning areas. Milestone methodologies such as deep reinforcement learning or the Transformer were introduced, showing great potential in mimicking cognitive capabilities and attention. Natural Language Processing as the main representative of unsupervised learning became the natural environment to evolve these algorithms into what is now known as Generative AI. These days AI and all its constituents, is one of the most promising technologies to lead business digitalization within this new era of Industry 4.0.
Regardless of the architecture, all Artificial Intelligence solutions go through a well-defined set of phases from inception and implementation to deployment and continuous improvement. It is an iterative process that can involve several cycles before the final Artificial Intelligence pipeline structure, the sequence of technical phases that will take an AI project from inception to production inference. The AI pipeline is an integral part of the wider AI project lifecycle. We separate the AI pipeline space into three main phases that follow business understanding and the overarching MLOps.
This use case landing page and its collection of sub-landing pages aim at providing a set of reusable blueprints that can be deployed in each of the various phases of an AI project lifecycle. Blueprints showcase techniques that can be used in context and apply them to example financial datasets. These blueprints are also coupled with relative, wider use case articles you will be able to use as a starting sandbox environment for experimentation depending on your business use case.
Business understanding
This initiation phase focuses on understanding the business space, objectives, and requirements and quantifiable value that the business is expecting to see from an AI. Assessment of existing processes is very important, transition plans, risk and contingencies deriving from a move to an AI solution need to be defined as part of the project scope. Available tools, technologies, new tech involved, migration or integration plans and human resources, timelines as well as a cost-benefit analysis need to be implemented.
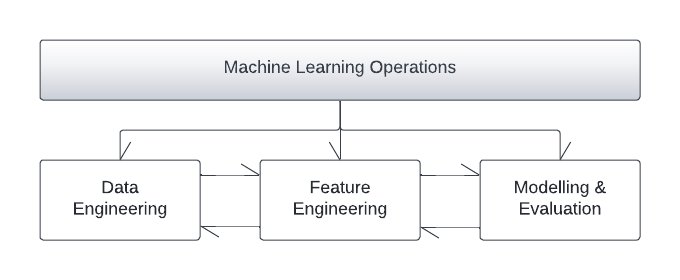
Data engineering
This first technical phase is all about identifying appropriate data scope and ingesting the raw datasets. Entering this phase, the team has a clear view of the business case digital twin and the problem at hand. Ingestion strategies, homogenisation and synchronisation from disparate sources are implemented. An initial exploration of the data will reveal, if they exist, first inconsistencies to be addressed. The phase output is a centralilsed data lake that is free of inconsistencies and has all the data needed to move forward to the feature engineering phase.
Feature engineering
One of the fundamental stages of a successful Artificial Intelligence solution is feature engineering. It is the process of transforming raw data into a feature set that can be used for AI training. Feature engineering can be a very computational-intensive process and requires a lot of creativity and domain knowledge. The end goal is the maximisation of the AI predictive power through highly informative, well-designed feature sets.
Modelling and evaluation
With the AI ready dataset at hand, the AI cores that can analyse the problem space can be defined. Some of the most prominent AI learning genres from which AI cores can be chosen include:
- Supervised & Unsupervised ML: These are the two typical scenarios of inference mapping. Supervised Learning means that the AI cores, learn from an existing pre-labelled dataset. Unsupervised Learning involves analysis and discovery of patterns in raw datasets to surface new insight.
- Deep Learning: A new generation of AI algorithms, mainly consisting of different architectures of deep stacked Neural Networks. These AI structures have shown superior performance in solving complex problems and are capable of surfacing better insight from even the most complex datasets.
- Reinforcement Learning: This approach tries to imitate the way we humans learn by experience. An AI agent is allowed to explore the digital twin of an environment. As the agent takes decisions it is introduced with the appropriate rewards. The agent learns to navigate the problem space in a way that it will maximise its rewards. Any problem can be tackled using the methodology provided sufficient environment modelling.
- Generative Learning: This approach imitates human behaviour and creativity showing significant cognitive capabilities. Generative AI combines methodologies such as reinforcement learning and modern deep layer structures such as transformers. GenAI after exploring and learning the digital twin of an environment can combine and generate new content in context. With sufficient environment modelling and training, very complex problems can be tackled. Recent GenAI developments in Large Language Models have resulted in extraordinary natural language interaction environments.
Complex AI cores are oftentimes very computationally intensive and costly to train and maintain. It is therefore important to be able to determine the performance increase delivered compared to benchmark models to justify the decision of AI solutions. Training, testing, and evaluation environments are deliverables within the phase.
Machine learning operations
One of the most important steps of the AI pipeline, closer to software engineering, is delivering the final product in a way that elevates User eXperience. Model deployments, tech stacks used, and presentation layers are parts of this productionisation phase. However, even after productionisation, the phase is far from over. In fact, MLOps is a process that governs the AI pipeline from start to finish. Moreover, in AI there is a concept that is described as CACE, Changing Anything, Changes Everything! A small change at any step in the pipeline can cascade in such a way that can affect the entire pipeline. An automated governing lineage process able to redeploy the entire pipeline without breaking continuity is therefore essential.
Measuring business value
While this is not per se a separate step of the AI pipeline, it is indeed one of the very important deliverables that follows the pipeline. Business value is very different than the quantitative evaluation of the AI cores on historical data e.g., or a back-test of a trading AI which we know that can contain quite a bit of bias before deployment. The concept is that as we are trying to enhance an existing process using AI, we should therefore be able to answer if we have succeeded at delivering enough value to justify its use. Key performance indicators that pre-exist the AI are compared in A-B testing to prove that it has delivered an increase in business value.
Related Articles
-
Idiosyncratic risk ranking using eXplainable AI
-
Microsoft Quantum – Implementing Quantum Discrete Fourier Transform Neural Networks in Q# and Tensorflow
-
Using AI modeling to interpret 10-Q Filings
-
Predicting M&A Targets Using ML: Unlocking the potential of NLP based variables
-
TensorFlow Variational Quantum Neural Networks in Finance
-
Predicting M&A Targets Using Machine Learning Techniques
-
Using Economic Indicators with Eikon Data API - A Machine Learning Example
Request Free Trial
Call your local sales team
Americas
All countries (toll free): +1 800 427 7570
Brazil: +55 11 47009629
Argentina: +54 11 53546700
Chile: +56 2 24838932
Mexico: +52 55 80005740
Colombia: +57 1 4419404
Europe, Middle East, Africa
Europe: +442045302020
Africa: +27 11 775 3188
Middle East & North Africa: 800035704182
Asia Pacific (Sub-Regional)
Australia & Pacific Islands: +612 8066 2494
China mainland: +86 10 6627 1095
Hong Kong & Macau: +852 3077 5499
India, Bangladesh, Nepal, Maldives & Sri Lanka:
+91 22 6180 7525
Indonesia: +622150960350
Japan: +813 6743 6515
Korea: +822 3478 4303
Malaysia & Brunei: +603 7 724 0502
New Zealand: +64 9913 6203
Philippines: 180 089 094 050 (Globe) or
180 014 410 639 (PLDT)
Singapore and all non-listed ASEAN Countries:
+65 6415 5484
Taiwan: +886 2 7734 4677
Thailand & Laos: +662 844 9576