



Abstract
No investment is free of all possible market risks, even the safest investments can be subject to underline risk constituents that can affect their performance. Quantifying risk is a key process within the modern financial investing ecosystem as it allows managers to hedge part of it using various diversification strategies.
Risk is defined as the deviation of an instrument’s returns compared to its expected returns. Traditionally in finance, risk is researched closely with financial returns, and it is a common conception that the higher the risk, the highest the possible returns as well as possible loss of an investment. Quantitatively risk is measured using instrument historical behaviour and returns. There exist several approaches to measure risk including standard deviation of returns, betas, Value at Risk (VaR), the Capital Asset Pricing Model (CAPM) and more.
The two main constituents of a stock’s risk are market or systematic risk and idiosyncratic risk. The first is a result of the company’s exposure to the market landscape and adheres to all companies within a sector. The second is related to the company’s profile, strategy, and closely related events such as business deals, M&As and legal proceedings. Other types of risk and their effects are also being investigated in the modern financial ecosystem.
Risk in financial markets – Idiosyncratic risk
Financial risk is associated with the probability of an investment losing money. Risk can materialize in many forms and can spread from one business to another, affecting a sector. If the spread continues across sectors global markets can be affected. Risk factors can be grouped together in the following major categories:
- Market risk: The risk that changes in financial instruments prices will negatively affect a portfolio. Market risk and credit risk are referred to as financial risk. Systematic or market risk is dependent on the performance of the entire market and is therefore dependent on macro-economic factors that can affect it such as inflation, interest rates, fiscal deficits, and geo-political factors. Market risk is divided into four major types:
- Interest rate risk: The risk that an interest rate sensitive instrument’s value will decrease because of changes in interest rates.
- Commodity risk: Risk originating from the price fluctuations of necessities an economy needs to function.
- Currency risk (Foreign exchange rate risk): Risk that open positions in currencies may incur. Such risk can also originate from cross-border business activities.
- Equity price risk: The risk related to volatility in stock prices.
- Credit risk: The risk of economic loss from a counterparty failing to fulfil contractual obligations. Credit risk further decomposes in four types of risks:
- Default risk: Debtors incapacity to meet obligations.
- Bankruptcy risk: Risk of collateralised or escrowed asset retrieval.
- Downgrade risk: Risk originating from deteriorating credit worthiness.
- Settlement risk: Risk originating from the exchange of cashflows during as a transaction is settled.
- Liquidity risk: This type of risk decomposes into two main categories:
- Funding liquidity risk: The ability of a firm to raise the necessary cash for debt, margin, and collateral operational requirements.
- Trading liquidity risk: The risk of a trade not being able to materialise because of loss of market appetite for the instrument.
- Operational risk: Potential losses originating from a range of operational weaknesses, human errors, catastrophes.
- Legal and regulatory risk: Closely related to operational and reputational risk and originates from lawsuits that may be triggered between counterparties.
- Business risk: The expected risk in the world pf business often originating from uncertainty e.g. in the prices of products because of supply and demand.
- Strategic risk: Risk of significant investments with high uncertainty on success and profitability.
- Reputation risk: Risk of degrading trust in enterprises their promises to counterparties as well as loss of trust in fair dealing.
Idiosyncratic risk
Idiosyncratic risk is endemic to an individual asset and refers to the inherent factors that can negatively affect individual securities or groups of assets. Idiosyncratic risk can be generally mitigated through diversification. Idiosyncratic risk is expected to be uncorrelated with market risk.
- Corporate culture
- Operating strategy
- Financial policies
- Investment strategy
In this prototype we use the Single Index Model and specifically the excess return on the market expected returns to generate a target variable mimicking idiosyncratic risk. The concept of SIM is based on the following equation:
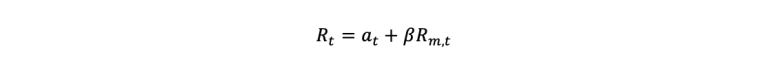
Where R(t) is the return on the stock of the company we are analysing and R(m,t) the return on the market index in period t. Component a(t) is the return on the company stock independent of the market. While a(t) can also be analysed in a fixed and stochastic component, for the purposes of this prototype we keep things simple and use a(t) as a fixed component mimicking returns accounted to company idiosyncratic behaviour and risk. We calculate and solve a linear regression for the SIM for all constituents of the S&P100 index and keep the residuals for each regression as endemic risk. Thereafter, to turn this into a ranking problem we sort the idiosyncratic risk residuals and generate a ranking score for each company. These ranks are used as the target variable for our idiosyncratic risk eXplainable AI.
Responsible, trust based AI
With recent developments in the AI space and the promise the technology delivers, the need for regulatory frameworks is increasingly becoming apparent to address any risks that might arise with its use. AI is an autonomous product or service that can adapt itself by training and learning on underlying patterns that can exist in data. It is this adaptability and autonomy that makes AI a difficult landscape to navigate, regulatory-wise, as traceability of decisions and responsibility assignment can become a difficult task.
To date many countries are working on delivering their frameworks and all regulations that are starting to formulate, despite the different approaches proposed, show many common traits. They all promote responsible AI and the need to increase trust in its use and application. Two main categories of regulations are starting to emerge globally, the context first based approach and the sector first based approach. In the former, AI regulations apply on a per application basis while in the latter on a per industry sector basis.
Context specific regulation focuses on outcomes rather than applying constraints on specific sectors or technologies. This type of regulation focuses on specific use cases and their results. Context specific regulation is closely related to the degree of risk an AI system may introduce in a use case. This approach weighs the risk against the opportunity loss from forgoing AI usage on specific applications.
Sector first regulatory approaches include an enumeration of high-risk AI systems within sectors and such lists can be adapted by relevant authorities to produce the correspondent governing regulations.
Main regulatory principles
Regardless of approach many common principles are discussed within all emerging frameworks, and they include:
- Privacy, safety, security, and effectiveness
- Appropriate transparency and explainability
- Fairness, discrimination protection
- Accountability and governance
- Contestability and redress
In this prototype we propose a solution for the principle of appropriate transparency and explainability. We suggest a new approach that rather than building the appropriate tools around the AI system integrates them within it by introducing a new XAI class that looks after the critical parts of the pipeline. This new structure can spin-up deep-learning AI cores with built-in explainability and transparency in all the important parts of the architecture. The XAI class can shed light to which features affect the decisions of the AI allowing engineers to optimise the feature engineering phase, displays detailed information about the training process allowing them to better understand how the AI reaches its convergence structure and the paths it follows to reach that. Finally, it builds surrogate models that can explain how the deep learning AI core reaches each decision when new data flows through it, looking into every feature and how that affects its final output.
The prototype
In this prototype, we run a 15 months analysis, however, in a production pipeline it is suggested to use a much longer timeframe. A 90-day beta window is used to estimate the residuals proxy for idiosyncratic risk. We are also using the constituents of the S&P 100 index. The whole prototype is divided into three modules responsible for data engineering, feature engineering and the explainable modeling and evaluation phases.
Getting ready to implement the idiosyncratic risk ranking prototype
In order to build the prototype, we have created a virtual environment running with Python 3.9 which allows us to isolate project's dependencies and avoid conflicts with other Python projects on the system. To obtain the data for the analysis we have used Refinitiv Data Libraries for Python with a Desktop session. More about the library, required configuration and type of the sessions can be found here.
Below we present the prerequisite packages used for building the prototype:
import refinitiv.data as rd
import pandas as pd
import numpy as np
import datetime
import torch
import tensorflow as tf
import keras_tuner as kt
import shap
import matplotlib.pyplot as plt
from refinitiv.data.content import news
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
from sklearn.preprocessing import MinMaxScaler, OneHotEncoder
from tqdm import tqdm
from functools import reduce
from datetime import datetime, date
from dateutil.relativedelta import relativedelta
from sklearn.model_selection import train_test_split
from dataclasses import dataclass
In the following sections, we will go through all the stages of the AI pipeline present and explain part of the codebase. For the complete code, please check the prototype's GitHub repo.
Data engineering – Ingesting the data
Following our usual AI pipeline, we start from the data engineering phase during which we will be ingesting all the data we need using RD libraries for us to experiment on writing this PoC. A main DataEngineering object was built that collates all ingestion endpoints under a single function run() that is responsible for ingesting the data using the get_data function from Refinitiv Data Libraries and generating a dictionary holding the final artifacts of the phase. We save two different types of dataframe artifacts, the first one prices we will use during the feature engineering phase to build the target data for our AI system and the second one raw_data we will use for building the final n features used during the modeling and evaluation phase. As we mentioned the run() function is the main entry point of the DataEngineering phase:
def run(self):
stocks_prices = self.get_prices(self.assets).dropna()
benchmark_prices = self.get_prices('.SPX').dropna()
industry = self.get_industry()
ratios = self.get_daily_ratios()
financials = self.get_financials()
ranking = self.get_ranking_estimates()
trading_activity = self.get_trading_activity()
num_analyst = self.get_analyst_coverage()
news = self.get_news()
return {'prices': {'stocks_prices': stocks_prices, 'benchmark_prices': benchmark_prices},
'raw_data': {'industry': industry, 'ratios': ratios, 'financials': financials, 'ranking': ranking,
'trading_activity': trading_activity, 'num_analyst': num_analyst, 'news': news}}
The instantiation of the DataEngineering object provides all the parameters that the object needs to execute the run function:
end = date.today()
start = pd.to_datetime(end - relativedelta(months=15))
beta_window = 90
study_scope = 'stock'
assets = rd.get_data('.OEXA', 'TR.IndexConstituentRIC')[
'Constituent RIC'].to_list()
de = DataEngineering(assets, start, end, beta_window).run()
label_dfs = de['prices']
features_dfs = de['raw_data']
We can see that we are ingesting data for the 100 stocks included S&P 100 index for a period of the last 15 months using RD Libraries. Calculations on stock betas are based on the beta_window and are set for 90 days. What the run() function does is essentially calling all the corresponding endpoints from RD libraries to gather the appropriate data on:
- Stock prices
- Benchmark SPX prices
- Industry sector data for companies
- Fundamentals
- Industry rankings data
- Trading activity on the companies’ stocks
- News data for the corresponding period
- Analysts covering companies.
Feature engineering – Preparing the final feature set for the AI models
During the feature engineering phase, we will trigger all processing needed for the raw data to become predictive features that can be used as input in our idiosyncratic risk ranking AI.
The artifacts produced during the data engineering phase can be saved to be processed at a later stage during the feature engineering phase or directly passed in memory to continue executing the pipeline. The next lines of code are responsible for triggering the feature engineering phase.
fe = FeatureEngineering(start, end, beta_window, study_scope)
studies = fe.run(label_dfs, features_dfs)
Again, the FeatureEngineering class accepts the appropriate parameters that will initialise its behaviour and the run function is called using the prices and raw data dataframes.
There are several processes that we need to trigger during this phase. Let’s start with sentiment calculations on the news headlines we have ingested in the previous phase. The entry point for all sentiment calculations is the function get_sentiment() which accepts the news dataframe as a parameter.
To calculate sentiment, get_sentiment() will call get_sentiment_bart() where we use the Facebook BART model and its zero-shot classification pipeline loaded within a pytorch environment. The following function will parse all available data and generate three float scores for its headline regarding positive, negative, and neutral sentiment of the headline.
def get_sentiment_bart(self, newsdf):
classifier = pipeline("zero-shot-classification",
model="facebook/bart-large-mnli", device=torch.device("mps"))
labels = ['positive', 'negative', 'neutral']
sentiments = {'versionCreated': [], 'headline': [],
'positive': [], 'negative': [], 'neutral': []}
for index, news_item in tqdm(newsdf.iterrows(), total=newsdf.shape[0]):
sent = classifier(news_item['headline'], labels)
pred_labels = sent["labels"]
scores = sent["scores"]
for label, score in zip(pred_labels, scores):
sentiments[label].append(score)
sentiments['headline'].append(news_item['headline'])
sentiments['versionCreated'].append(news_item['versionCreated'])
return pd.DataFrame(sentiments)
To augment the predictive value of news we also calculate two more features the cumulative sum of positive and negative sentiment and the total number of news count. The cumulative sum of sentiment is an integer that increases by one if a positive sentiment news headline flows through the system or decreases by one if a negative news headline flows through the system. This is done using the function build_features_on_sentiment(). After the sentiment calculations the final synchronised feature set is built through the build_dataset(). An important step in the process is building the target labels for model training. As we have mentioned we are using an idiosyncratic risk ranking system. LabelBuilder is looking after the entire process through its functions get_ranked_residuals(), calculate_residuals() and rank_stock_by_risk().
Finally, preprocess_data() will quantise industry features into an integer sequence as well as scale the data in order to prepare them for the final deep neural network training.
Modeling and evaluation – Building an eXplainable AI model
In this section, we implement an eXplainable AI Deep Learning model trained on the features presented in the previous section. The objective of this model is to predict company idiosyncratic risk-based rankings. Additionally, we utilise a SHAP DeepExplainer object generating all the necessary explanation artifacts for the AI model behaviour, enhancing the interpretability of, and increasing trust in the model.
Architecture
At the core of the architecture lies the DeepNeuralNetwork object based on the tf.keras.Model base class which defines the architectural template of our model. This class constructs a deep neural network using a flexible parametererised structure allowing to dynamically instantiate the layers and model parameters. Furthermore, the object ensures the optimization of the structure using hyperparameter tuning.
class DeepNeuralNetwork(tf.keras.Model):
def __init__(self, structure):
super(DeepNeuralNetwork, self).__init__(name='DNN')
self.structure = structure
self.model = None
def model_builder(self, hp):
_model = tf.keras.Sequential()
hp_neurons = hp.Int('units', min_value=5, max_value=20, step=1)
hp_dropout_rate = hp.Choice('dropout_rate', values=[0.05, 0.1, 0.2])
hp_learning_rate = hp.Choice('learning_rate', values=[1e-2, 1e-3, 1e-4])
for ix, layer in enumerate(self.structure['core']):
if layer['id'] == 'input':
_model.add(tf.keras.layers.Flatten(
input_shape=(layer['neurons'], )))
exec(f"_model.add(tf.keras.layers.{layer['type']}({layer['neurons']}, trainable=True))")
_model.add(tf.keras.layers.Dropout(hp_dropout_rate))
elif layer['id'] == 'hidden':
exec(f"_model.add(tf.keras.layers.{layer['type']}(hp_neurons, activation='elu', trainable=True))")
_model.add(tf.keras.layers.Dropout(hp_dropout_rate))
else:
exec("_model.add(tf.keras.layers.{layer['type']}({layer['neurons']}, trainable=True))")
_model.compile(optimizer=tf.keras.optimizers.legacy.Adam(learning_rate=hp_learning_rate, epsilon=1e-07), loss=tf.keras.losses.MeanSquaredError(), metrics=["mean_squared_error"])
return _model
The internal structure of the neural network is defined by a dictionary which is initialised via the __init__ method of the object. Here is an example of a basic neural network structure used for default initialisation in our prototype:
{'core': [{'id': 'input', 'type': 'Dense', 'neurons': 3},
{'id': 'hidden', 'type': 'Dense','neurons': 10},
{'id': 'output', 'type': 'Dense', 'neurons': 1}],
'hp': {'dropout_rate': 0.1, 'learning_rate': 0.01}}
This example dictionary defines a structure consisting of 3 Dense layers: an input layer with 3 neurons, a Hidden with 10 neurons and an Output layer with a single neuron responsible for the ranking prediction. Additionally, it provides default hyperparameter values for dropout and learning rates. Going back to our architecture let’s present the model_builder method of DeepNeuralNetwork object.
The purpose of model_builder method is to construct a deep neural network based on the structure and hyperparameter values. The method accepts a hyperparameter instance from Keras Tuner as an input which defines the parameter space to be optimised during the hyperparameter tuning. The hyperparameter space that we choose to optimise on in this pipeline is intentionally kept simple providing an overview of the process, rather than triggering a production based optimization process. In production workflows, it is recommended to target many more hyperparameters for optimisation, such as batch size, activation functions, number of layers, and more.
Layer instantiation is looked after a flexible for based on the layer's type and neuron attributes. We present the use of an exec() function that turns string objects to code for the interpreter. This makes layer instantiation extremely dynamic, however, such a function should be used with caution even on a local execution basis and its use should be avoided in production pipelines where the layer structure can be fixed.
The use of the Flatten() layer converts our multidimensional feature array into a single-dimensional one which allows us to feed the data into the neural network in a format that can be easily processed by the subsequent layers. The Dropout() layer with tunable rate parameter allows for random cuts of connections during training preventing overfitting.
After all the layers are added the model_builder method compiles the model using the Adam optimiser, mean_squared_error loss and a tunable learning rate parameter.
Implementation the eXplainable AI class
With the core architecture of our deep learning model in place, we can now move forward with implementing an eXplainable AI wrapper class. This class will handle the initialisation of features, model fitting to the data, and building of Shapley values for interpreting the model outputs. The wrapper class will consist of 4 methods: __init__, fit, explanations and visualisations.
The __init__ method of the wrapper class will initialize the model name, model structure, feature names as well as the features and target variables as shown below:
def __init__(self, model_name, x, y,
structure={'core': [{'id': 'input', 'type': 'Dense', 'neurons': 3},
{'id': 'hidden', 'type': 'Dense', 'neurons': 10},
{'id': 'output', 'type': 'Dense', 'neurons': 1}],
'hp': {'dropout_rate': 0.1, 'learning_rate': 0.01}}):
self.structure = structure
self.feature_names = x.columns.values
self.model_name = model_name
self.x = x
self.y = y
Within the __init__ method we also split our dataset into training and testing datasets.
self.num_of_features = self.x.shape[1]
for ix, layer in enumerate(structure['core']):
if layer['id'] == 'input':
structure['core'][ix]['neurons'] = self.num_of_features
self.dnn = DeepNeuralNetwork(structure=self.structure)
Finally, we initialise a directory path where the tensorflow logs will be stored. To ensure that the logs from different experiments are not overwritten we provide dynamic names to the directories constructed from the corresponding model names.
self.log_dir = "./logs/" + model_name + \
datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
The fit method of the wrapper is used to train the deep learning model, initialized earlier on the data. This method accepts the number of epochs and produce_tensorboard, explainable flags as parameters. The method first task is to define the callbacks triggered during model training:
def fit(self, max_epochs=150, produce_tensorboard=True, visualisations=True):
_callbacks = []
stop_early = tf.keras.callbacks.EarlyStopping(
monitor='val_loss', patience=7, start_from_epoch=70)
_callbacks.append(stop_early)
In the code snippet above, we define an EarlyStopping callback from Keras. This callback monitors the validation loss starting from Epoch 70 and stops the training if the validation loss does not improve for 7 consecutive epochs. The TensorFlow documentation provides various parameters for building more customized functions, and the library also offers an Abstract Callback class for creating new custom callbacks.
Next,if the produce_tensorboard flag is set to True, we conditionally create a folder to store tensorflow logs and define the tensorboard callback with the specified logs path and append it to the _callbacks array. The Tensorflow callback will store all needed artifacts to enable visualisations for the Tensorboard. We set the histogram frequency parameter to 1 which will compute weight datapoints for model training visualisations at each epoch.
if produce_tensorboard:
if not os.path.exists(self.log_dir):
os.makedirs(self.log_dir)
tensorboard_callback = tf.keras.callbacks.TensorBoard(
log_dir=self.log_dir, histogram_freq=1)
_callbacks.append(tensorboard_callback)
Next, we define the tuner for hyperparameter search using Keras Tuner in Tensorflow.We set up a Hyperband tuner which uses a combination of random search and early stopping to efficiently traverse the hyperparameter space. The key principle behind the hyperband tuner is that it randomly samples a set of hyperparameters, trains for a fixed number of epochs and discards the poor performing models by evaluating their early performance. This approach of early stopping poor performing models, is the main advantage of the Hyperband tuner as it allows for testing of a larger number of hyperparameters in shorter time. Apart from the Hyperband, Keras offers 3 more hyperparameter optimization algorithms:
- RandomSearch: Finds the best model structure by randomly sampling hyperparameters from a defined search space and trains a model for each combination of hyperparameters.
- BayesianOptimization: This tuner uses Bayesian optimisation to search the hyperparameter space. It models the performance of the model as a function of the hyperparameters and uses this model to iteratively find the best set of hyperparameters.
- Sklearn: This tuner uses scikit-learn's GridSearchCV or RandomizedSearchCV to search the hyperparameter space.
Below we initialise the Hyperband tuner object. We provide several parameters, including the model builder function that we introduced above, the objective, which is set to mean_squared_error, the maximum number of epochs to train for, a factor to determine the number of models to train in each round, and a directory and project name to save the results.
hp_tuner = kt.Hyperband(self.dnn.model_builder, objective='mean_squared_error', max_epochs=max_epochs, factor=5, directory='./hp/', project_name='kt_hb_' + self.model_name)
Next, we start the hyperparameter optimisation by passing the training data, maximum number of epochs to train the model, validation set for evaluation purposes and the tensorboard callback.
hp_tuner.search(self.x_train, self.y_train, epochs=max_epochs, validation_split=0.1, callbacks=[.keras.callbacks.TensorBoard('./hp/tb_logs/')])
best_hpm = hp_tuner.get_best_hyperparameters(num_trials=1)[0]
After finding the best hyperparameters we search for the optimal number of epochs to train the model. To do that we create a model instance using the best hyperparameters of the previous search and fit our model to the data. After the model is trained, we extract the epoch with the lowest training loss.
self.dnn.model = hp_tuner.hypermodel.build(best_hpm)
train_history = self.dnn.model.fit(self.x_train, self.y_train, epochs=max_epochs, validation_data=(self.x_test, self.y_test), =[stop_early])
train_loss_epoch = train_history.history['loss']
best_epoch_num = train_loss_epoch.index(min(train_loss_epoch))
With the best hyperparameters and the optimal number of epochs in place, we re-instantiate the hypermodel and perform a final training pass.
self.dnn.model = hp_tuner.hypermodel.build(best_hpm)
self.dnn.model.fit(self.x_train, self.y_train, validation_data=(self.x_test, self.y_test), epochs=best_epoch_num, callbacks=_callbacks)
Finally, to produce explainability artifacts we can call the get_explanations method of our wrapper class by providing the appropriate model, background_data (training data), input data (test data) and visualisations flag parameters.
if explainable:
self.get_explanations(self.dnn.model, self.x_train.to_numpy(), self.x_test.to_numpy(), visualisations=True)
SHAP explainers
Our eXplainable AI (XAI) framework is designed to provide a single-entry point to a self-interpretable Deep Learning model. Deep learning models’ “black box” nature is the main challenge of result adaptation leading to low trust. By implementing this approach, we aim to increase decision makers’ trust in our AI models by providing all the necessary explanation artifacts of the behaviour of the model during training and inference. There are multiple techniques to implement an explainable AI framework, including:
- Surrogate models that approximate the trained model. The surrogate models have a more explainable architecture than the original model, such as linear or tree based. The purpose of surrogate models is to approximate the predictions of the underlying model as accurately as possible while remaining highly interpretable at the same time.
- Explainer techniques, such as LIME and SHAP, that generate local or global explanations for individual predictions made by an AI learning model. These techniques provide insights into how the model arrived at a particular prediction by highlighting the most important features that influenced the prediction.
In our prototype, we have implemented the SHAP explainer which is a widely adopted explanation method. SHAP is a game theory approach based on the concept of Shapley values, which is a method for assigning credit to individual players in a cooperative game. SHAP applies this concept to the input features of a neural network by computing the average contribution of each feature to the model's output across all possible combinations of features. SHAP offers multiple explainers, such as TreeExplainer() to interpret tree-based ML models, DeepExplainer() for deep learning models and a fully customizable KernelExplainer() for the rest of the models.
Below we define get_explanations method which is part of the XAI implementation wrapper class:
def get_explanations(self, model, background_data, input_data, visualisations=True):
self.explainer = shap.DeepExplainer(model, background_data)
self.shap_values = self.explainer.shap_values(input_data)
if visualisations == True:
self.get_visualisations(self.shap_values, self.explainer)
The function accepts the deep learning model, the background dataset, input dataset and visualisations flag as parameters. It first creates the explainer instance using the DeepExplainer object of the SHAP framework. The background dataset can be the entire or part of the training dataset with an optimal length of 1000 samples. Next, we get the Shapley values by calling shap_values method on the explainer object and passing the input data from the test dataset. Finally, if visualisations are required, we call the get_visualisations method of our wrapper class by passing the explainer and the shap_values:
def get_visualisations(self, shap_values, explainer,
decision_plot=True,
force_plot=True,
waterfall_plot=True,
summary_plot=True):
if summary_plot:
shap.summary_plot(shap_values[0], feature_names=self.feature_names, plot_type='bar', show=False)
plt.savefig(xai_logs_path + self.model_name + '_summary_plot.png', bbox_inches='tight', dpi=600)
plt.close()
if force_plot:
shap.force_plot(explainer.expected_value[0].numpy(),shap_values[0][0], features=self.feature_names, matplotlib=True, show=False)
plt.savefig(xai_logs_path + self.model_name + '_force_plot.png', bbox_inches='tight', dpi=600)
plt.close()
The SHAP framework offers many visualisation techniques, which can provide both global and local interpretability of our model.
- The summary plot provides an overview of which features are most important for a model. It sorts features by the sum of SHAP value magnitudes over all samples and uses those to show the distribution of the impacts each feature has on the model output.
- The force_plot generates inference feature importance by explaining why a case receives its prediction and the contributions of the predictors. This greatly increases the transparency compared to the traditional variable importance algorithms which only show the results across the entire population but not in each case.
There are several other plots, such as the waterfall plot, decision plot and dependency plot that have been used in our use case. The generated plots in a local folder following a unique and dynamic naming convention for easy retrieval.
More on the parameters space of the plots can be found in the official documentation.
Modeling and evaluation results
In this final stage and with the processed feature set in place we are ready to trigger the modeling and evaluation phase of our self-explainable deep Learning model. We conduct the evaluation in 3 different levels:
- Across all assets and all industries: During this run, we execute our analysis on the entire dataset and provide global feature importance.
- Across all assets per industry: In this case, we execute several runs, per industry, to trigger the evaluation on all assets and provide feature importance for each industry.
- Per asset: This is the lowest granularity level of execution where we evaluate the model on a per asset basis and provide individualised feature importances.
The below one-liner accepts the study name and level, study features and the appropriate labels and triggers the entire modeling and evaluation of our self-explainable deep Learning AI model.
XAI(study_name, study_feature_set['df_x'], study_feature_set['df_y']).fit()
We'll start by presenting the analysis results across all assets from all industries and across all assets per industry. As we have mentioned, all these results are generated from the XAI class and enabled through flags in initialisation. Results are saved in appropriate folders using dynamic naming conventions, so that they can be retrieved on a need-to-know basis. Below we present model performance during training measured by the mean squared error for all industries, Banking and Software & IT industry levels.
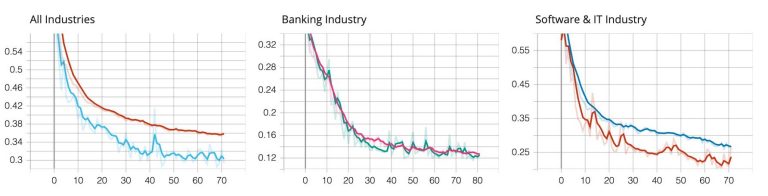
The tensorboard plots above showcase how the models behaves during training, as expected in a well-behaved learning session, we see the loss decreasing throughout the epochs. As we implemented the early stopping, we also see various models stopping at different epochs. An interesting finding in the graphs is that the validation loss is consistently lower than the training loss for most of the models. Although there might be multiple reasons for this, the main reason is that the Keras framework doesn’t trigger the dropout layers during validation leading to an artificial improvement in performance.
Now let’s look into the summary plots from SHAP analysis showing the global feature importances for the respective models.

The graph above shows the most significant variables impacting each of the models in descending order. The top variables contribute more to the model decisions and therefore have higher predictive power. We can conclude from the plots above, that financial ratios strongly contribute to the predictions of the models alongside with the ranking estimates. Furthermore, the trading activity metrics have relatively strong contribution, whereas the news sentiment has a modest contribution across all models.
Moving to the per stock analysis let’s present the training process for Bank of America and Microsoft.
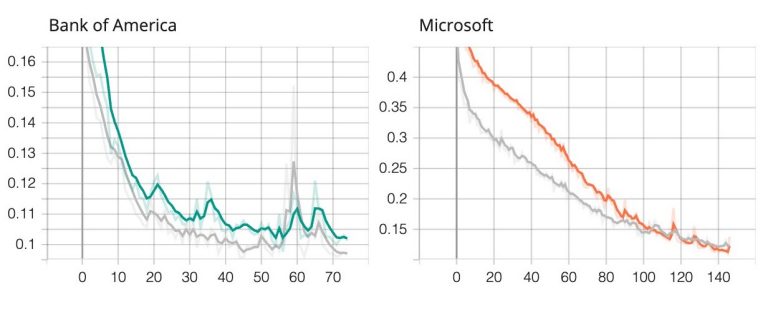
From the plots above we see a similar again expected training behaviour to the losses for all and industry level scenarios.
Finally, let’s look into the company specific feature importance and explore how each feature contributes to the prediction. Starting the analysis from the Bank of America, we present the summary plot to show global feature importance within all samples from the company as well as waterfall, and force plots to measure feature contribution to individualised predictions.
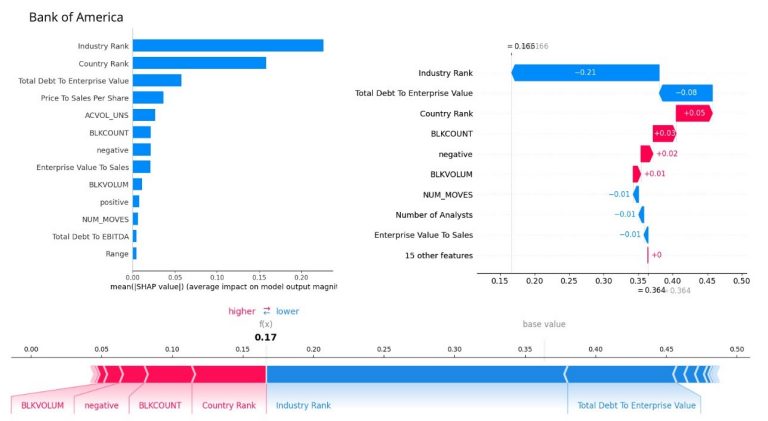
The summary plot above suggests that ranking estimates have the most impact to predictions followed by financial ratios and trading activity metrics. This is largely inline with what we have observed in the industry level analysis. One interesting finding is that the negative news score appears in the top 10 significant factors in contrast with the industry level model analysis.
Furthermore, the waterfall plot, on the right indicates that the value of prediction increases with negative news. Other factors that drive the prediction values higher, increasing the idiosyncratic risk of companies, include block trading volume and trading counts, as well as the company's estimated country rank. Conversely, the company's industry rank and Total Debt to Enterprise value are the primary factors that drive the prediction value downwards for this specific sample item. It is worth noting the contrasting contribution direction of industry and country ranks. To understand why this occurs, a more in-depth analysis of the data, including comparing the metric value of this single observation with the sample mean value can be undertaken.
Finally, we have included graphs that showcase the global and local feature contributions for Microsoft, as a constituent from the Software & IT industry. Here, instead of the waterwall plot we display a decision plot, an alternative for analysing the contribution of a feature on a single inference observation.
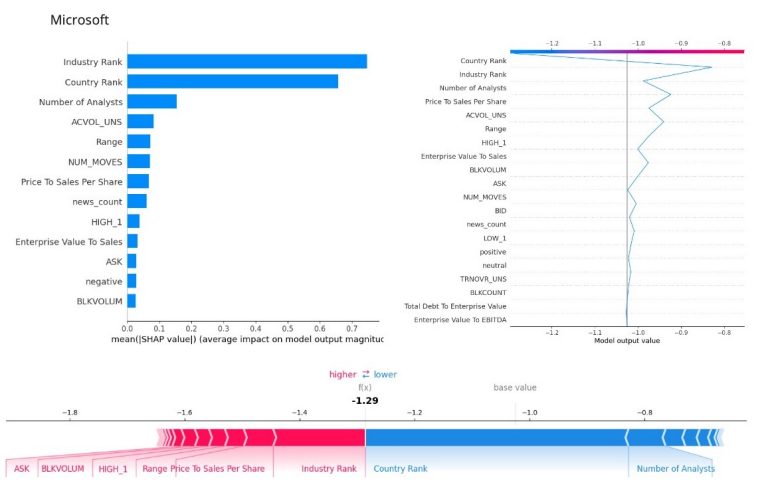
The summary plot suggests that the ranking estimates, number of analysts reviewing the company and trading activity, are the most significant features, whereas financial ratios, such as the Price to Sales are of lower importance despite being the most significant indicators in the industry level analysis. Regarding the decision plot in the left, we observe an increase in the predictive values contributed by industry rank, Price to Sales ratio and the trading activity metrics. On the other hand Country rank, Number of Analysts and the EV to sales are lowering the predictive values
Once again, such contradiction surfaced from our explainability process calls for further in-depth analysis.
Conclusions and Future work
In this article we presented a prototype implementing an idiosyncratic risk ranking Artificial Intelligence system. We used RD libraries to ingest a variety of data including fundamentals, market data and news sentiment to generate the features used during our predictive analysis. The Single Index Model was used to calculate endemic risk and rank it, turning it into the predictive target of our AI. Furthermore, we presented an eXplainable AI framework that can be used as a single-entry point wrapper, providing all necessary artifacts during feature engineering, training, evaluation, and inference of the AI pipeline to gain deeper understanding of the behaviour of the system throughout the process.
Our eXplainability framework combines Tensorboard logging artifacts with DeepExplainer SHAP values artifacts. This enables us to provide a very detailed review of the behaviour of our deep learning models during training and evaluation through the Tensorboard dashboards as well as individualised, on a per execution basis, visualisations on feature importance, and feature effects during the AI inference cycles. These visualisations can be combined to build a very detailed dashboard that can monitor the system throughout its lifecycle. The provided agile architecture allows for the XAI wrappers to be further enhanced to support more AI scenarios and different AI cores.
If you would like to reach out with any questions regarding this article, we would be happy to address those in our Developer Community Q&A Forum.
- Register or Log in to applaud this article
- Let the author know how much this article helped you
Related Articles
-
Market regime detection using Statistical and ML based approaches
-
Detecting flash crash events using deep reinforcement learning agents
-
Microsoft Quantum – Implementing Quantum Discrete Fourier Transform Neural Networks in Q# and Tensorflow
-
Modeling and Evaluation – Proprietary models using Tensorflow & Keras – Part I
-
Modeling and Evaluation – Proprietary models using Tensorflow & Keras – Part II
-
Prediction of M&A targets to generate portfolio returns
-
Enhancing real-time news streams using AWS serverless AI. An automated MLOps architecture using Terraform.