Enhancing real-time news streams using AWS Serverless AI. An automated MLOps architecture using Terraform.



Business incentive - The use case
Refinitiv Data (RD) libraries provide a powerful set of interfaces for uniform access to the Refinitiv data universe. The library provides multiple layers of abstraction providing for different styles and programming techniques suitable for all developers, from low latency real time access to batch ingestions.
In this article we present an AWS architecture that ingests our news feeds using RD libraries and enhances them using AI inference. In an effort to design a modular architecture, that could be used in most use cases, we decided to focus on the real-time space. The reason for this decision is that this is one of the most demanding use-cases and that the same architecture can also be used, with minimal tweaks, for batch AI inference. In our use case, we will implement a prototype that ingests our real-time news feed, calculates sentiment on each news headline using Artificial Intelligence and re-serves the AI enhanced feed through a publisher – subscriber architecture.
Moreover, to present a full MLOps stack we introduce the concept of Infrastructure as Code during the entire MLOps lifecycle of the prototype. By using Terraform and a single entry point configurable script, we can instantiate the entire infrastructure, in-production mode, on AWS in just a few minutes.
The benefits of Cloud computing
Cloud computing is defined as the rapid provisioning and release of information technology resources through the Internet on an on-demand basis. Access to these resources is expected to be ubiquitous, convenient and require minimal management effort. Three main models of Cloud computing exist:
- Infrastructure as a Service: IaaS provides access to all the necessary IT infrastructure; however, clients are responsible for the management of resources just as it would be if they were in-premises.
- Platform as a Service: PaaS frees the clients from having to manage the entire infrastructure allowing them to focus more on the application layer.
- Software as a Service: SaaS simplifies the PaaS experience even more as a SaaS provider will provide complete application building blocks that are fully managed.
We also segregate Cloud computing into three main areas depending on deployment strategies:
- All-in-Cloud: Design and implementation and implementation of the application fully depends on cloud resources.
- Hybrid: In this model part of the application is hosted in premises and part on the Cloud that acts as an extension of the internal structure.
- Private Cloud: This is the process of implementing an all in-premise Cloud using appropriate virtualization software and practices.
There are many advantages in using Cloud computing including:
- Faster implementations & focusing on the application layer: Building a complete solution in premises requires a full resource procurement process before starting software implementations that might be lengthy.
- Flexible capacity provision: The ability for easy and fast capacity upscaling or downscaling allows for faster convergence of computational requirements, avoiding larger margin guestimates. The computational elasticity of the cloud also allows for almost acute responses to demand surges.
- Better cost management: By benefiting from economies of scale providers can offer less costly infrastructure on demand. Using the Cloud also allows for conversion of up-front capital expenses to operational expenses.
- Global presence: Under the Cloud model moving infrastructure to different regions is a matter of a few mouse clicks rather than months of planning and provisioning.
Automated MLOps - Infrastructure as Code
In this prototype we follow a fully automated provisioning methodology in accordance with Infrastructure as Code (IaC) best practices. IaC is the process of provisioning resources programmatically using automated scripts rather than using interactive configuration tools. Resources can be both hardware and needed software. In our case we are using Terraform to accomplish the implementation of a single configurable entry point that can automatically spin-up the entire infrastructure we need, including security and access policies as well as automated monitoring. Using this single-entry point that triggers a collection of Terraform scripts, one per service or resource entity, we can fully automate the lifecycle of all or parts of the components of the architecture allowing us to implement granular control both on the DevOps as well as the MLOps side. Once Terraform is correctly installed and integrated with AWS we can replicate the majority of operations that can be done on the AWS service dashboards.
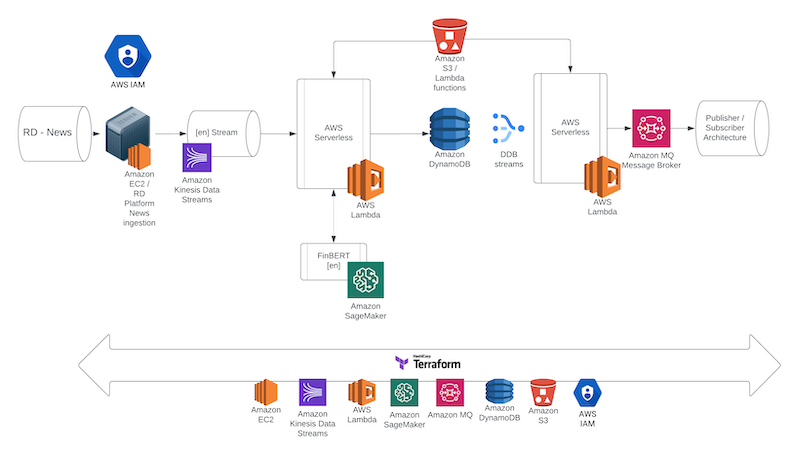
Architecture - Amazon Web Services
The architecture consists of two main stages, during the first stage the real-time feeds are ingested on an EC2 instance that is created through a 'Refinitiv Data library'-ready AMI. The instance connects to a Kinesis stream that triggers a Lambda function able to connect and send the news headlines to a SageMaker FinBERT endpoint that returns the calculated sentiment for the news item. The Lambda function will then wrap the news item with this new information and store it in a DynamoDB.
In the second stage of the architecture a DynamoDB stream will trigger a Lambda function on new item inserts which is integrated with an Amazon MQ server running RabbitMQ that re-serves the AI enhanced stream.
The decision on this two-stage engineering design, rather than the first lambda layer directly communicating with the Amazon MQ server, or implementing more functionality in the EC2 instance was made to enable exploration of more complex, less coupled AI design architectures in the future as described.
AWS Identity Access Management
Identity and Access Management allows us to define how a user, group or role can securely use AWS resources in our infrastructure. Using IAM we can control both the authentication and authorisation rules that will govern any access in our AWS resources. IAM allows for authentication of both simple and federated users. Security keys, passwords, and multi-factor authentications as well as corporate directories are supported. On the authorization side, there is a detailed level of granularity when defining what users can or cannot do with resources allowing for implementation of concepts such as least privilege or duties segregation. These privileges are defined using JSON IAM policies. To add to the security levels provided, activity on AWS is fully monitored and can be audited via AWS CloudTrail that also allows us to better ensure compliance with regulatory standards. Security however on the cloud is a topic for a complete article itself as it differs from the on-premises security practice being a shared responsibility process between AWS and their clients. In this prototype we will be using terraform scripts to create the necessary roles needed to allow for this whole infrastructure to function.
Find out more about AWS IAM security best practices in the relevant AWS Documentation section: Amazon Web Services - Identity Access Management
AWS Simple Storage Service
We can use the Simple Storage Service to store any kind of object on our Amazon cloud infrastructure. An object is really any type of file we store in an S3 container that is called the bucket. The bucket essentially serves as a folder and is a unique high-level entity that helps us organise data on S3. By default, buckets are attached to accounts for reporting and charging services and can be created on most of the available regions. Cross-region automatic replication is not supported, but can be implemented, however failsafe replication and eventual consistency is implemented across Availability Zones (AZs). Versioning is one of the features provided by S3. Encryption is supported both in transit as well as at rest. To avoid any performance bottlenecks, partitioning strategies need to be employed according to Amazon’s best practices. Bucket access can be controlled through IAM policies that allow for very granular implementations on a per role, user, and group level as well as a bucket level. There are many S3 storage classes that can be used depending on usage, performance and availability needs such as S3 Standard, S3 Standard Infrequent Access, S3 Reduced Redundancy Storage, S3 One Zone Infrequent Access, and Amazon Glacier. Integration to S3 can be implemented through a RESTful service that allows for the ingestion, creation, update, and deletion of objects and awscli can be used for all operations.
In this prototype we use AWS S3 to store two lambda function scripts in zipped format to ingest them to the appropriate lambda containers in production. The first lambda that listens to the Kinesis stream, retrieves AI inference, and stores the enhanced data items in DynamoDB. The second one, pushes newly created data items to Amazon MQ. The whole process is governed from terraform scripts which will create the appropriate buckets as well as upload the correct script files in place. The Terraform scripts are also provided in our repository.
Please visit the AWS documentation for details on the S3 service and best practices: Amazon Web Services - S3
AWS Elastic Cloud Compute
Amazon EC2 is a pay as you go service for provisioning any scale compute capabilities. Using the awscli, or dashboards it allows its users to quickly instantiate servers that can be general purpose or fully optimized for specific purposes e.g., GPU AI training. There are a lot of options with regards to configurations that allow for building any proprietary instance in terms of both hardware and software. There are also a few ways to instantiate an instance that can affect costs amongst which is on-demand, reserved and spot instantiation. On the host side both shared and dedicated instancing is supported again affecting costs. One of the powerful features that AWS EC2 provides is the storage of Amazon Machine Instances (AMIs). Using this service, we can store the current state of a server on AWS and reload it on a new hardware instance in the future. Instances can live in many states including running or terminated states and when online we can connect to an EC2 instance in either from our dashboards or using secure shell (ssh) with the appropriate security in place. In this prototype we will guide you through spinning up an EC2 instance from scratch all the way to enabling it to ingest news items streams from RD libraries. Once the process is finished, we will show you how to store the instance in an AMI to not have to replicate the process in the future. We will then guide you through the process of automatically loading the AMI on a new instance through terraform.
Find out more about Amazon Kinesis best practices and architectures in the relevant AWS Documentation section: Amazon Web Services - EC2
AWS Kinesis
In a world of continuously flowing data, increasingly we need to turn our attention from batch to real-time stream processing. Regardless of the use case we need a different set of tools to implement a real-time streaming architecture. Amazon Kinesis provides three different solutions to handle huge amounts of real-time streaming data and produce insights, Data streams, Data Firehose and Data Analytics. Amazon data streams, which is the service used in this prototype, allows for real-time parallel data processing. A Kinesis stream can be easily implemented either through the appropriate dashboard or programmatically using the appropriate Kinesis Producer Libraries. Kinesis is a very reliable process as it automatically replicates streaming data across AZ facilities and streams are kept in storage for a default of seven days. The service is fully elastic and can handle from thousand to millions of PUT records per second. It is also a fully managed serverless capability and through on-demand provisioning - structure and capacity are automatically managed. Another important characteristic of Kinesis is its integration capabilities with other AWS services which we also utilise in this prototype by connecting it with Lambda services to drive the AI inference integration. The creation and setup of the lambda service is fully managed by Terraform scripts that we also provide in our repository.
Find out more about Amazon Kinesis best practices and architectures in the relevant AWS Documentation section: Amazon Web Services - Kinesis
AWS Lambda
Lambda functions are one of Amazon’s solutions to serverless computing. They are compute services that can execute code and respond in real-time to events raised within our infrastructure. Some of the many advantages of using Lambda functions as building blocks of the backbone of our infrastructure are their scalability, built-in redundancy, and the fact that they are truly serverless, there is no infrastructure to manage nor computational capacity to account for. Everything is fully managed, and the developer can focus on writing code that can respond to its environment. Event sources can be AWS API Gateway Events, Kinesis streams, DynamoDB changes, S3, Cloudwatch and so on. In this prototype we will explore Lambda responses both to Kinesis streams and DynamoDB streams. Multiple languages are supported when writing Lambda functions including node.js, javascript and python. We will be using python through the entire prototype. We will write two Lambda functions one that will be listening to a Kinesis stream and will be retrieving and unwrapping news items. Thereafter, depending on language if will connect to an AWS SageMaker endpoint and acquire sentiment inference on the news item headline. Once that is done it will attach this new inference in the item and store the AI enhanced item in DynamoDB. The second Lambda function listens to DynamoDB streams and any new entry is forwarded to an Amazon MQ server to get in queue and allow consumers to retrieve the new enhanced stream. The creation of the Lambda container service is fully managed by Terraform scripts provided in our repository.
Please visit the AWS documentation for details on the Lambda service and best practices: Amazon Web Services - Lambda
AWS DynamoDB
DynamoDB is a fully managed NoSQL database on AWS in the sense that we simply define a table, its throughput and the rest is handled by the service. The benefits of DynamoDB is that it is fully scalable, fast and consistent. It also easily integrates with AWS Lambda functions. This allows us to implement triggering functionality. Role-based access can be implemented using AWS IAM. In this prototype, we use DynamoDB to store the newly AI enhanced news item and then by using DynamoDB streams we can push the newly inserted item to Amazon MQ. All these integrations as well as the instantiation of the DynamoDB service is managed by our Terraform scripts provided in our repository.
Find out more about Amazon DynamoDB best practices and architectures in the relevant AWS Documentation section: Amazon Web Services - DynamoDB
AWS SageMaker
Amazon SageMaker is a fully managed suite of services implementing the complete Artificial Intelligence pipeline from data ingestion to Ai training, productionisation and MLOps. Using SageMaker Data Wrangler we can ingest and explore our data and engineer new feature stores using our datasets. We can design and implement new AI cores using the Studio or quickly implement PoCs in Studio lab. Compute power is available to train from the simplest ML cores to complex Deep Learning structures using the training compiler. MLOps is facilitated by Lineage Tracking. Model Building pipelines, Monitor and Experiments and serverless productionisation is available through SageMaker Endpoints. In this prototype we follow a deploy an AI trained core approach rather than the build your own AI process. However, the methodology stays the same if you follow the full pipeline either in-premises or on AWS to train your cores. Terraform scripts configure SageMaker endpoints and launch the appropriate inference instances installing a HuggingFace FinBERT model in them and integrating it with the rest of the infrastructure.
Please find more resources in Amazon's Getting started guide that segregates the learning path into four distinct roles high and low code Data Scientists, ML Engineers and Business Analysts: Amazon Web Services - Sagemaker
Amazon MQ
Amazon MQ is a managed Broker service that allows us to build a production ready message broker. Amazon MQ supports both ActiveMQ and RabbitMQ. The usual process for provisioning and security can be followed using AWS IAM and the broker can be public or isolated within a VPC for privacy purposes. CloudWatch and CloudTrail can be used for Broker monitoring. Amazon MQ uses automated replication across Availability Zones providing high availability and durability to your message queues. In this prototype we se terraform to spin-up and configure a RabbitMQ Broker on Amazon MQ and connect it to our Lambda layers. We also provide a Consumer python script that can be used the final stage of the infrastructure when online.
Find out more about Amazon MQ best practices and architectures in the relevant AWS Documentation section: Amazon Web Services - Amazon MQ
Prototype Blueprints structure
This prototype will be presented in a series of three very detailed Blueprints following the bellow structure, in each Blueprint and for every service used you will find overviews and relevant information on its technical implementations as well as terraform scripts that allow you to automatically start, configure and integrate the service with the rest of the structure. At the end of each Blueprint you will find instructions on how to make sure that everything is working as expected up-to each stage.
Blueprint I: Real-time news ingestion using Amazon EC2 and Kinesis Data Streams
This Blueprint will discuss the initial stages of the architecture that allow us to ingest the real-time news feeds.
- Amazon EC2 preparing your instance for RD News ingestion: This section describes how to set-up an EC2 instance in a way that it enables the connection to the RD Libraries API and the real-time stream. We will show also how to save the image of the created EC2 to ensure the reusability and the scalability of the instance.
- Real-time news ingestion from Amazon EC2: This section describes both the detailed implementation of the configurations needed to enable EC2 to connect the RD libraries as well as the scripts to start the ingestion.
- Creating and launching Amazon EC2 from the AMI: -In this section, we present how to launch a new instance by simultaneously transferring ingestion files to the newly created instance, all automatically using Terraform.
- Creating a Kinesis data stream: - This section provides an overview of Kinesis and how to setup a stream on AWS.
- Connecting and pushing data to Kinesis: Once the ingestion code is working, we need to connect it and send data to Kinesis streams.
- Testing the prototype so far: Using Cloudwatch and command line tools we will verify that the prototype is working up-to this point and that we can continue to the next Blueprint.
In this second Blueprint, we focus on the main part of the architecture, the lambda function that will ingest and analyse the news item stream, attach the AI inference to it and store it for further use.
- AWS Lambda: This section describes, how to define a Terraform AWS Lambda configuration allowing it to connect to a Sagemaker endpoint.
- Amazon S3: To implement the Lambda service we need to upload the appropriate code to S3 and allow the Lambda to ingest it in its environment. This section describes how we can use terraform to accomplish that.
- Implementing the Lambda function: Step 1, Handling the Kinesis event: In this section, we will start building the lambda function. Here, we will build the kinesis response handler part only.
- Amazon SageMaker: In this prototype we use a pre-trained HuggingFace model that we store into a SageMaker endpoint. Here, we will be presenting how this can be achieved using terraform scripts and how the appropriate integrations take place to allow SageMaker endpoints and Lambda functions work together.
- Building the Lambda function: Step 2, Invoking the SageMaker endpoint: In this section, we build up our original Lambda function by adding the SageMaker block to get a sentiment enhanced news headline by invoking the SageMaker endpoint.
- Dynamo DB: Finally, once the AI inference is in the memory of the Lambda function, it re-bundles the item and sends it to a DynamoDB Table for storage. Here we discuss both the appropriate python code needed to accomplish that, as well as the necessary terraform scripts that enable these interactions.
- Building the Lambda function: Step 3, Pushing enhanced data to DynamoDB – Here, we continue building up our Lambda function by adding the last part that creates an entry in the Dynamo table.
- Testing the prototype so far – We can navigate to the DynamoDB table on the DynamoDB console to verify that our enhancements are appearing in the table.
Blueprint III: Real-time streaming using Dynamo DB streams – Lambdas and Amazon MQ
This third Blueprint finalises this prototype. It focuses on redistributing the newly created, AI enhanced data item to a Rabbit MQ server in Amazon MQ allowing consumers to connect and retrieve the new items in real-time.
- Dynamo DB streams: Once the enhanced news item is in DynamoDB we setup an event getting triggered that can then be captured from the appropriate Lambda function.
- Writing the Lambda producer: This new Lambda captures the event and acts as a producer of the RabbitMQ stream. This new lambda introduces the concept of Lambda layers as it uses python libraries to implement the producer functionality.
- Amazon MQ - Rabbit MQ - consumers: The final step of the prototype is setting up the Rabbit MQ service and implementing an example consumer that will connect to the message stream and receive the AI enhanced news items.
- Final test of the prototype: Using an end-to-end process we will verify that the prototype is fully working, from ingestion to re-serving and consuming the new AI-enhanced stream.
In the final Blueprint you will also find a detailed test vector to making sure that the entire architecture is behaving as planned.
Getting ready to implement the prototype
To start the implementation of this prototype we suggest creating a new python environment dedicated to it and install the necessary packages and tools separately from other environments you may have.To do so and activate the new environment in Anaconda use the following commands:
conda create --name rd_news_aws_terraform python=3.7
conda activate rd_news_aws_terraform
We are now ready to install the AWS Command Line Interface (CLI) toolset that will allow us to build all the necessary programmatic interactions in and between AWS services:
pip install awscli
Now that AWS CLI is installed we need to install Terraform. Haschicorp provides Terraform with a binary installer, visit the following link to download:
Once you have both tools installed ensure that they properly work using the following commands:
terraform -help
AWS - version
You are now ready to follow the detailed Blueprints on each of the three stages of the implementation. Please start with:
Real-time news ingestion using Amazon EC2 and Kinesis Data Streams
For more information and resources on this prototype you can also visit the AWS Machine Learning Blog:
Enriching real-time news streams with the Refinitiv Data Library, AWS services, and Amazon SageMaker.