
Authors:

Dr. Haykaz Aramyan
Developer Advocate
Developer Advocate

Gurpreet Bal
Platform Application Developer
Platform Application Developer

Dr. Marios Skevofylakas
Data Scientist
Data Scientist
Introduction
The cornerstone of effective and accurate TCA is the use of noise free market data enhanced with prevailing market conditions. In our previous article, we introduced the concept of TCA and its constituents and our workflow of simulating trades for the analysis. Building on this foundation, we now focus on trade enrichment using the Tick History data. To optimize the performance and speed of data processing, we implement the data ingestion asynchronously. More about LSEG Tick History, including the QuickStart guide with examples and detailed documentation can be found here.
Authorization
Access to the Tick History data requires an authentication process. This involves obtaining an access token using valid Datascope Select credentials. A POST request is sent with the necessary credentials, and upon verification, an access token is granted. Below, we define the request URL, headers to specify the content response with preference and the body with the credentials.
request_url = "https://selectapi.datascope.lseg.com/RestApi/v1/Authentication/RequestToken"
request_headers = {
"Prefer": "respond-async",
"Content-Type": "application/json"
}
request_body = {
"Credentials": {
"Username": username,
"Password": password
}
}
In our prototype, the authentication functionality is encapsulated within an Authorization Python object to maintain clean code and reusability. The detailed implementation can be seen in our source code here.
Tick Data Extraction and Preparation for TCA
Setting the stage for data extraction
Before we initiate the data extraction process, it is important to define the timeframe within which we want to analyze our trades. This is achieved through a function specifying how much historical data we want to consider before and after the trade occurs:
The add_extraction_timeline function is designed to define the period of market data relevant to each trade. It modifies the input DataFrame, which contains trade details, by first ensuring that times are in the correct datetime format and then keeping the last order for the reference. The function then calculates the appropriate time window for analysis by extending the period before the trade's signal time and after the trade execution time by user-specified milliseconds. These new start and end times are converted into a consistent string format in subsequent data requests. By establishing this extraction timeline, the function equips us with a targeted dataset for an efficient data extraction with LSEG Tick History.
Building extraction pipeline
The entire process of tick data extraction, storage, and annotation is wrapped in the DataExtraction object available in the source code of the prototype. The class methods leverage asynchronous programming allowing for simultaneous data requests and processing.
The extract_tick_data function below serves as the gateway for obtaining tick-level market data. It is an asynchronous function, allowing multiple data requests to be handled efficiently within the execution flow.
async def extract_tick_data(self, ric, start, end, signal_time):
async with self.semaphore:
request_url, request_headers, request_body = self.get_request_details(self.token, ric, start, end)
job_id = await self.get_extraction_output(request_url, request_headers, request_body)
await self.save_extraction_results(job_id, self.token, ric, signal_time)
Upon invocation, the function uses a semaphore to manage concurrent data extraction, preserving system stability by limiting the number of simultaneous requests. In the function get_request_details, we define the necessary details for the data request. First, the appropriate URL and request headers are defined:
request_url = "https://selectapi.datascope.lseg.com/RestApi/v1/Extractions/ExtractRaw"
request_headers = {
"Prefer": "respond-async",
"Content-Type": "application/json",
"Authorization": "token " + token
}
Next, we formulate the main request body and send the request:
request_body = {
"ExtractionRequest": {
"@odata.type": data_type,
"ContentFieldNames": content_fields,
"IdentifierList": {
"@odata.type": "#DataScope.Select.Api.Extractions.ExtractionRequests.InstrumentIdentifierList",
"InstrumentIdentifiers": [
{"Identifier": ric, "IdentifierType": "Ric"}
]
},
"Condition": request_conditions
}
}
This function can be used to both handle market depth and tick history requests through data_type, content_fields and conditions variables, defined in the rth_config and below:
- Historical tick data request - We have used historical tick data to enrich our trades with market trades/quotes preceding and following each of our trades. For that, we used time and sales data, with an On Demand extraction request from LSEG tick history. More on available fields and conditions can be found in the Tutorial page of the API.
"tick_history": {
"data_type": "#DataScope.Select.Api.Extractions.ExtractionRequests.TickHistoryTimeAndSalesExtractionRequest",
"content_fields": [
"Trade - Exchange Time",
"Trade - Ask Price",
"Trade - Ask Size",
"Trade - Bid Price",
"Trade - Bid Size",
"Trade - Volume",
"Trade - Price",
"Trade - Low",
"Trade - High",
"Trade - Market VWAP"
],
"conditions": {
"MessageTimeStampIn": "LocalExchangeTime",
"DateRangeTimeZone": "Local Exchange Time Zone",
"ReportDateRangeType": "Range"
}
}
- Market depth data request - Market depth is a representation of the order book, which we have used for trade simulation and to analyze market depth and available trading volumes across 10 levels of orderbook depth. For that, we have used Tick History Market Depth Extraction request from LSEG Tick History API. More on available fields and conditions can be found in the Tutorial page of the API.
"market_depth": {
"data_type": "#DataScope.Select.Api.Extractions.ExtractionRequests.TickHistoryMarketDepthExtractionRequest",
"content_fields": [
"Ask Price",
"Ask Size",
"Bid Price",
"Bid Size",
"Instrument ID",
"Exchange Time"
],
"conditions": {
"View": "NormalizedLL2",
"NumberOfLevels": 10,
"MessageTimeStampIn": "LocalExchangeTime",
"DateRangeTimeZone": "Local Exchange Time Zone",
"ReportDateRangeType": "Range"
}
}
We can now use the get_extraction_output function which asynchronously initiates the extraction process. It does that by first submitting the data request and then by obtaining a job ID - a unique identifier that tracks the status of the data extraction request.
async def get_extraction_output(self, request_url, request_headers, request_body):
async with self.session.post(request_url, json=request_body, headers=request_headers, timeout = 600) as response:
status_code = response.status
if status_code == 200:
response_json = await response.json()
job_id = response_json["JobId"]
return job_id
if status_code == 202:
request_url = response.headers["location"]
job_id = await self.wait_for_completion(status_code, request_url, request_headers)
return job_id
This function initiates the process by sending an asynchronous POST request to the API endpoint. It expects either a successful response (HTTP 200), indicating the job is completed, or an indication (HTTP 202) that the job is accepted but not yet finished. If the earlier is true, it parses the JSON response to extract the JobId, used for tracking the extraction job. If the job is not completed, the function captures the location URL from the response headers. This URL is then used to periodically check the status of the job until completion via wait_for_completion function.
Once the data is ready, we save the results to an appropriate storage in gzip format.
async def save_extraction_results(self, job_id, token, ric, signal_time):
request_url = "https://selectapi.datascope.lseg.com/RestApi/v1/Extractions/RawExtractionResults" + "('" + job_id + "')" + "/$value"
request_headers = {
"Prefer": "respond-async",
"Content-Type": "text/plain",
"Accept-Encoding": "gzip",
"Authorization": "token " + token
}
async with self.session.get(request_url, headers=request_headers) as response:
await self.write_output_to_gzip(response, ric, signal_time)
Function save_extraction_results, retrieves the extraction results using the job ID obtained from the data extraction process, sets up the request header and sends a GET request to fetch the raw extraction results. Upon receiving the response, it proceeds to save the data in a compressed gzip format.
Triggering the asynchronous extraction pipeline
In this final stage, we initiate the tick data extraction process through the extract function, which orchestrates the setup and execution of data ingestion tasks based on the provided trade data. The function begins by adding an extraction timeline for tick history requests. Then, using a configuration file it initiates the necessary settings and authentication details. It then goes through the authorization process. The core of the asynchronous execution is managed by Python's asyncio event loop. The function extract_tick_data_async is called within this loop to process each trade. Within this function, a nested asynchronous function is defined to isolate the extraction process for each trade dispatching asynchronous tasks. By using asyncio.gather, all these tasks run concurrently, ensuring parallel execution of the extraction process, significantly enhancing the overall efficiency and speed of the data retrieval process.
def extract(df, request_type, file_path):
if request_type == 'tick_history':
df = add_extraction_timeline(df, 120000, 120000)
config_path = 'configuration/rth_config.json'
token = Authorization(config_path).get_token()
de = DataExtraction(file_path,config_path, token, request_type)
loop = asyncio.get_event_loop()
loop.run_until_complete(extract_tick_data_async(de, df))
asyncio.run(de.close_session())
Data model and Exploration
Upon completion of the ingestion process, each order, for every asset, is encapsulated in its own gzip-compressed file. An extract of a file with tick data captured 2 minutes before and after a specific trade on BARC.L, is shown below.
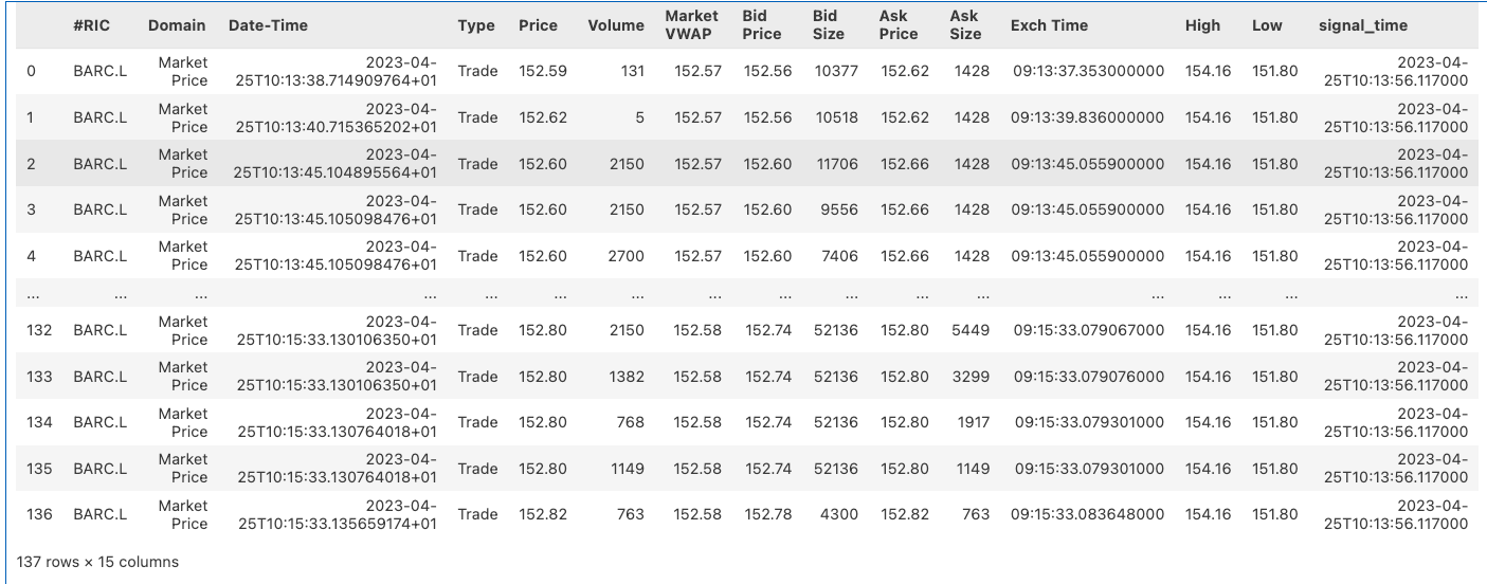
This example file consists of 137 data points, each providing insights into the trade time, prices, and volumes. It includes market metrics such as bid and ask prices, and VWAP, amongst others. Additionally, each file is augmented with signaling times, a key piece of information that links the extracted tick data back to the corresponding orders, ensuring a traceable dataset for analysis.
Further analysis is conducted by merging the tick outputs with simulated trades, providing a layered aggregation that maps tick data against the trades.

The DataFrame above provides a snapshot of trading flows by asset. Metrics include the number of brokers and traders involved, the volume of buy and sell orders placed and the respective numbers of executions fulfilling the order amount. Additionally, the count of tick data points collected both before and after trades are stored, offering a granular view into market conditions surrounding each transaction.
Conclusion
This article covered asynchronous tick data extraction using LSEG Tick History for the efficient handling of large volumes of data. Additionally, we have provided an example of the outputs and an aggregated data model with enhanced trades which will be used for the main analysis and visualization in our last article in the series.
- Register or Log in to applaud this article
- Let the author know how much this article helped you
If you require assistance, please
contact us here
Get In Touch
RELATED ARTICLES
Related Videos
Source Code
Related APIs
Request Free Trial
Call your local sales team
Americas
All countries (toll free): +1 800 427 7570
Brazil: +55 11 47009629
Argentina: +54 11 53546700
Chile: +56 2 24838932
Mexico: +52 55 80005740
Colombia: +57 1 4419404
Europe, Middle East, Africa
Europe: +442045302020
Africa: +27 11 775 3188
Middle East & North Africa: 800035704182
Asia Pacific (Sub-Regional)
Australia & Pacific Islands: +612 8066 2494
China mainland: +86 10 6627 1095
Hong Kong & Macau: +852 3077 5499
India, Bangladesh, Nepal, Maldives & Sri Lanka:
+91 22 6180 7525
Indonesia: +622150960350
Japan: +813 6743 6515
Korea: +822 3478 4303
Malaysia & Brunei: +603 7 724 0502
New Zealand: +64 9913 6203
Philippines: 180 089 094 050 (Globe) or
180 014 410 639 (PLDT)
Singapore and all non-listed ASEAN Countries:
+65 6415 5484
Taiwan: +886 2 7734 4677
Thailand & Laos: +662 844 9576