Authors:

In this article, we will investigate Public Companies' Climate targets and whether they are on track to meet them. The data needed for such an investigation is not onboarded on LSEG's Data Platform yet; but, thankfully, it is on both (i) on LSEG's Sustainable Finance Investing (SFI) Snowflake and (ii) on Workspace. Thanks to the latter, we can call for this data on CodeBook. For more information on the Climate data we are collecting and the methodology, please refer to the article "LSEG's SFI Snowflake Datawarehouse: A use-case evaluating public companies' Climate track record using Python and SQL".
LSEG usually collects data from a number of vendors, but when it comes to climate data, we rely on our analysts to retrieve the information directly from companies disclosures. The most exciting data onboarded has, recently, related to ESG and Climate topics. In this article, we will directly source the data we are after using the Data Item Browser and CodeBook.
Importing libraries and Authentifying ourselves to LSEG's services
import re # We'll use the `re` library to seperate numbers from words in strings.
import pandas as pd # this library is great for dataframe manipulations.
import plotly.graph_objects as go # `plotly` and its modules are useful for us to plot graphs.
import numpy as np # `numpy` in this case will be useful for us to plot graphs.
import lseg.data as ld
ld.open_session()
Calling and tidying our data
For more information on the reason why we are collecting this data, please refer to the article "LSEG's SFI Snowflake Datawarehouse: A use-case evaluating public companies' Climate track record using Python and SQL". With that said, it will be evident, during the article, why we collected this data.
First, let's put in place the primary parameters:
RIC = "MSFT.O" # SHEL.L, AAPL.O
scopeOfInterest = "1" # choice between "1", "2", "3", "1 and 2" or "1, 2 and 3"
setOfInterest = 1 # choice from 1 to 5
termOfInterest = "LT" # choice between "ST" and "LT"
sourceOfInterest = "LSEG" # choice between "LSEG" and "CDP"
We need extra parameters for the logic we'll create below, I define them here:
scopeOfInterestFirstNumber = int(re.search(r'\d+', scopeOfInterest).group())
if termOfInterest == "ST":
termNotOfInterest = "LT"
else:
termNotOfInterest = "ST"
if sourceOfInterest == "LSEG":
_sourceOfInterest = ""
elif sourceOfInterest == "CDP":
_sourceOfInterest = sourceOfInterest
Now, we can create the list of fields we're after from LSEG's services:
lstOfFlds = ["TR.CO2EquivalentEmissionsTotalMarketbased", "TR.CO2EmissionTotal"]
for i in range(1,4):
lstOfFlds.append(f"TR.{_sourceOfInterest}CO2DirectScope{i}")
lstOfFlds.append(f"TR.{_sourceOfInterest}CO2IndirectScope{i}")
lstOfFlds.append(f"TR.{_sourceOfInterest}CO2EmissionTotal")
lstOfFlds.append(f"TR.{_sourceOfInterest}TotalCO2EquivalentEmissionsScope1and2and3")
lstOfFlds.append(f"TR.{_sourceOfInterest}TotalCO2EquivalentEmissionScope1and2and3Marketbased")
lstOfFlds.append(f"TR.{_sourceOfInterest}{termOfInterest}GHGEmissionPercentageReductionTargetedSet{setOfInterest}")
lstOfFlds.append(f"TR.{_sourceOfInterest}{termOfInterest}PercentageofGHGEmissionCoveredbyTargetSet{setOfInterest}")
lstOfFlds.append(f"TR.{_sourceOfInterest}{termOfInterest}GHGEmissionScopeSet{setOfInterest}")
lstOfFlds.append(f"TR.{_sourceOfInterest}{termOfInterest}GHGEmissionBaseYearSet{setOfInterest}")
lstOfFlds.append(f"TR.{_sourceOfInterest}{termOfInterest}GHGEmissionTargetYearSet{setOfInterest}")
print(lstOfFlds)
['TR.CO2EquivalentEmissionsTotalMarketbased', 'TR.CO2EmissionTotal', 'TR.CO2DirectScope1', 'TR.CO2IndirectScope1', 'TR.CO2DirectScope2', 'TR.CO2IndirectScope2', 'TR.CO2DirectScope3', 'TR.CO2IndirectScope3', 'TR.CO2EmissionTotal', 'TR.TotalCO2EquivalentEmissionsScope1and2and3', 'TR.TotalCO2EquivalentEmissionScope1and2and3Marketbased', 'TR.LTGHGEmissionPercentageReductionTargetedSet1', 'TR.LTPercentageofGHGEmissionCoveredbyTargetSet1', 'TR.LTGHGEmissionScopeSet1', 'TR.LTGHGEmissionBaseYearSet1', 'TR.LTGHGEmissionTargetYearSet1']
len(lstOfFlds)
16
Now we're cooking:
df0 = ld.get_history(
universe=[RIC],
fields=lstOfFlds,
start="1990-01-01",
end="2025-01-01",
header_type=ld.HeaderType.NAME_AND_TITLE,
).dropna(how='all')
df0.tail(3)
| MSFT.O | TR.CO2EQUIVALENTEMISSIONSTOTALMARKETBASED|CO2 Equivalent Emissions Total Market-based | TR.CO2EMISSIONTOTAL|CO2 Equivalent Emissions Total | TR.CO2DIRECTSCOPE1|CO2 Equivalent Emissions Direct, Scope 1 | TR.CO2INDIRECTSCOPE2|CO2 Equivalent Emissions Indirect, Scope 2 | TR.CO2INDIRECTSCOPE3|CO2 Equivalent Emissions Indirect, Scope 3 | TR.TOTALCO2EQUIVALENTEMISSIONSSCOPE1AND2AND3|Total CO2 Equivalent Emissions Scope 1, 2 and 3 | TR.TOTALCO2EQUIVALENTEMISSIONSCOPE1AND2AND3MARKETBASED|Total CO2 Equivalent Emission Scope 1, 2 and 3 Market-based | TR.LTGHGEMISSIONPERCENTAGEREDUCTIONTARGETEDSET1|LT GHG Emission Percentage Reduction Targeted Set1 | TR.LTPERCENTAGEOFGHGEMISSIONCOVEREDBYTARGETSET1|LT Percentage of GHG Emission Covered by Target Set1 | TR.LTGHGEMISSIONSCOPESET1|LT GHG Emission Scope Set1 | TR.LTGHGEMISSIONBASEYEARSET1|LT GHG Emission Base Year Set1 | TR.LTGHGEMISSIONTARGETYEARSET1|LT GHG Emission Target Year Set1 |
| Date | ||||||||||||
| 30/06/2020 | 574219 | <NA> | <NA> | <NA> | <NA> | <NA> | 12227000 | <NA> | <NA> | <NA> | <NA> | |
| 30/06/2021 | 553109 | 5134371 | 123704 | 5010667 | 13839000 | 18973371 | 14392000 | 75 | 100 | Scope 1 and 2 | 2013 | 2045 |
| 30/06/2022 | 427442 | 6520663 | 139413 | 6381250 | 16111000 | 22631663 | 16538000 | 75 | 100 | Scope 1 and 2 | 2013 | 2045 |
As it happens, "CO2 Equivalent Emissions Total" is "CO2 Equivalent Emissions Direct, Scope 1"; I don't want to overwright the column names, so let's just add a new one:
if scopeOfInterest == "1 and 2":
df0[f"TR.{sourceOfInterest}CO2EQUIVALENTEMISSIONTOTAL|CO2 Equivalent Emissions Direct, Scope 1 and 2"] = df0[f"TR.{sourceOfInterest}CO2EQUIVALENTEMISSIONTOTAL|CO2 Equivalent Emissions Total"]
print(list(df0.columns))
['TR.CO2EQUIVALENTEMISSIONSTOTALMARKETBASED|CO2 Equivalent Emissions Total Market-based', 'TR.CO2EMISSIONTOTAL|CO2 Equivalent Emissions Total', 'TR.CO2DIRECTSCOPE1|CO2 Equivalent Emissions Direct, Scope 1', 'TR.CO2INDIRECTSCOPE2|CO2 Equivalent Emissions Indirect, Scope 2', 'TR.CO2INDIRECTSCOPE3|CO2 Equivalent Emissions Indirect, Scope 3', 'TR.TOTALCO2EQUIVALENTEMISSIONSSCOPE1AND2AND3|Total CO2 Equivalent Emissions Scope 1, 2 and 3', 'TR.TOTALCO2EQUIVALENTEMISSIONSCOPE1AND2AND3MARKETBASED|Total CO2 Equivalent Emission Scope 1, 2 and 3 Market-based', 'TR.LTGHGEMISSIONPERCENTAGEREDUCTIONTARGETEDSET1|LT GHG Emission Percentage Reduction Targeted Set1', 'TR.LTPERCENTAGEOFGHGEMISSIONCOVEREDBYTARGETSET1|LT Percentage of GHG Emission Covered by Target Set1', 'TR.LTGHGEMISSIONSCOPESET1|LT GHG Emission Scope Set1', 'TR.LTGHGEMISSIONBASEYEARSET1|LT GHG Emission Base Year Set1', 'TR.LTGHGEMISSIONTARGETYEARSET1|LT GHG Emission Target Year Set1']
As you see, there are several Scopes and Sets we may be interested in. Scope can be "1", "2", "1+2", "3" or "1+2+3". Scope can be anything from 1 to 5 (inclusive).
if sourceOfInterest == "LSEG":
cols = [
col for col in df0.columns
if 'CO2EQUIVALENTEMISSIONSTOTALMARKETBASED' in col
or "CO2EMISSIONTOTAL" in col
or (
'CDP' not in col # not in
and f'Scope {scopeOfInterest}, ' not in col
and f'Scope {scopeOfInterest} and ' not in col
and f'Scope {scopeOfInterestFirstNumber+1}' not in col
and f'Scope {scopeOfInterestFirstNumber+2}' not in col
and f'Scope {scopeOfInterestFirstNumber-1}' not in col
and f'Scope {scopeOfInterestFirstNumber-2}' not in col
and f'{termNotOfInterest}GHGEMISSION' not in col
and f'{termNotOfInterest}PERCENTAGE' not in col
and (
f'Scope {scopeOfInterest}' in col
or f'Set{setOfInterest}' in col))]
if sourceOfInterest == "CDP": # choice of "LSEG or "CDP"
cols = [
col for col in df0.columns
if 'CO2EQUIVALENTEMISSIONSTOTALMARKETBASED' in col
or "CO2EMISSIONTOTAL" in col
or (
'CDP' in col # in
and f'Scope {scopeOfInterest}, ' not in col
and f'Scope {scopeOfInterest} and ' not in col
and f'Scope {scopeOfInterestFirstNumber+1}' not in col
and f'Scope {scopeOfInterestFirstNumber+2}' not in col
and f'Scope {scopeOfInterestFirstNumber-1}' not in col
and f'Scope {scopeOfInterestFirstNumber-2}' not in col
and f'{termNotOfInterest}GHGEMISSION' not in col
and f'{termNotOfInterest}PERCENTAGE' not in col
and (
f'Scope {scopeOfInterest}' in col
or f'Set{setOfInterest}' in col))]
print(len(cols))
cols
8
['TR.CO2EQUIVALENTEMISSIONSTOTALMARKETBASED|CO2 Equivalent Emissions Total Market-based',
'TR.CO2EMISSIONTOTAL|CO2 Equivalent Emissions Total',
'TR.CO2DIRECTSCOPE1|CO2 Equivalent Emissions Direct, Scope 1',
'TR.LTGHGEMISSIONPERCENTAGEREDUCTIONTARGETEDSET1|LT GHG Emission Percentage Reduction Targeted Set1',
'TR.LTPERCENTAGEOFGHGEMISSIONCOVEREDBYTARGETSET1|LT Percentage of GHG Emission Covered by Target Set1',
'TR.LTGHGEMISSIONSCOPESET1|LT GHG Emission Scope Set1',
'TR.LTGHGEMISSIONBASEYEARSET1|LT GHG Emission Base Year Set1',
'TR.LTGHGEMISSIONTARGETYEARSET1|LT GHG Emission Target Year Set1']
df1 = df0[cols]
df1.tail(5)
| MSFT.O | TR.CO2EQUIVALENTEMISSIONSTOTALMARKETBASED|CO2 Equivalent Emissions Total Market-based | TR.CO2EMISSIONTOTAL|CO2 Equivalent Emissions Total | TR.CO2DIRECTSCOPE1|CO2 Equivalent Emissions Direct, Scope 1 | TR.LTGHGEMISSIONPERCENTAGEREDUCTIONTARGETEDSET1|LT GHG Emission Percentage Reduction Targeted Set1 | TR.LTPERCENTAGEOFGHGEMISSIONCOVEREDBYTARGETSET1|LT Percentage of GHG Emission Covered by Target Set1 | TR.LTGHGEMISSIONSCOPESET1|LT GHG Emission Scope Set1 | TR.LTGHGEMISSIONBASEYEARSET1|LT GHG Emission Base Year Set1 | TR.LTGHGEMISSIONTARGETYEARSET1|LT GHG Emission Target Year Set1 |
| Date | ||||||||
| 30/06/2019 | <NA> | <NA> | <NA> | 75 | 100 | Scope 1 and 2 | 2013 | 2045 |
| 30/06/2020 | <NA> | 4447016 | 118100 | 75 | 100 | Scope 1 and 2 | 2013 | 2045 |
| 30/06/2020 | 574219 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | |
| 30/06/2021 | 553109 | 5134371 | 123704 | 75 | 100 | Scope 1 and 2 | 2013 | 2045 |
| 30/06/2022 | 427442 | 6520663 | 139413 | 75 | 100 | Scope 1 and 2 | 2013 | 2045 |
df2 = df1.replace('', pd._libs.missing.NA)
df3 = df2.dropna(how='all')
df3.tail(3)
| MSFT.O | TR.CO2EQUIVALENTEMISSIONSTOTALMARKETBASED|CO2 Equivalent Emissions Total Market-based | TR.CO2EMISSIONTOTAL|CO2 Equivalent Emissions Total | TR.CO2DIRECTSCOPE1|CO2 Equivalent Emissions Direct, Scope 1 | TR.LTGHGEMISSIONPERCENTAGEREDUCTIONTARGETEDSET1|LT GHG Emission Percentage Reduction Targeted Set1 | TR.LTPERCENTAGEOFGHGEMISSIONCOVEREDBYTARGETSET1|LT Percentage of GHG Emission Covered by Target Set1 | TR.LTGHGEMISSIONSCOPESET1|LT GHG Emission Scope Set1 | TR.LTGHGEMISSIONBASEYEARSET1|LT GHG Emission Base Year Set1 | TR.LTGHGEMISSIONTARGETYEARSET1|LT GHG Emission Target Year Set1 |
| Date | ||||||||
| 30/06/2020 | 574219 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
| 30/06/2021 | 553109 | 5134371 | 123704 | 75 | 100 | Scope 1 and 2 | 2013 | 2045 |
| 30/06/2022 | 427442 | 6520663 | 139413 | 75 | 100 | Scope 1 and 2 | 2013 | 2045 |
df4 = df3.filter(like='PERCENTAGEOFGHGEMISSIONCOVEREDBYTARGETSET')
if df4.apply(pd.to_numeric, errors='coerce').dropna().gt(80).all().all():
print("'GHGEmissionCoveredbyTarget' figures are above 80%. The higher this figure, the more reliable the results.")
print("In this case, we consider them to be high enough to be reliable.")
else:
print("Be weary of the fact that 'GHGEmissionCoveredbyTarget' is below 80%. The lower this figure, the less reliable the results.")
'GHGEmissionCoveredbyTarget' figures are above 80%. The higher this figure, the more reliable the results.
In this case, we consider them to be high enough to be reliable.
Plotting the results
df5 = df3.copy()
df5.index = [np.int64(z) for z in pd.to_datetime(df5.index, errors='coerce').year.astype(object)] # keep only the years
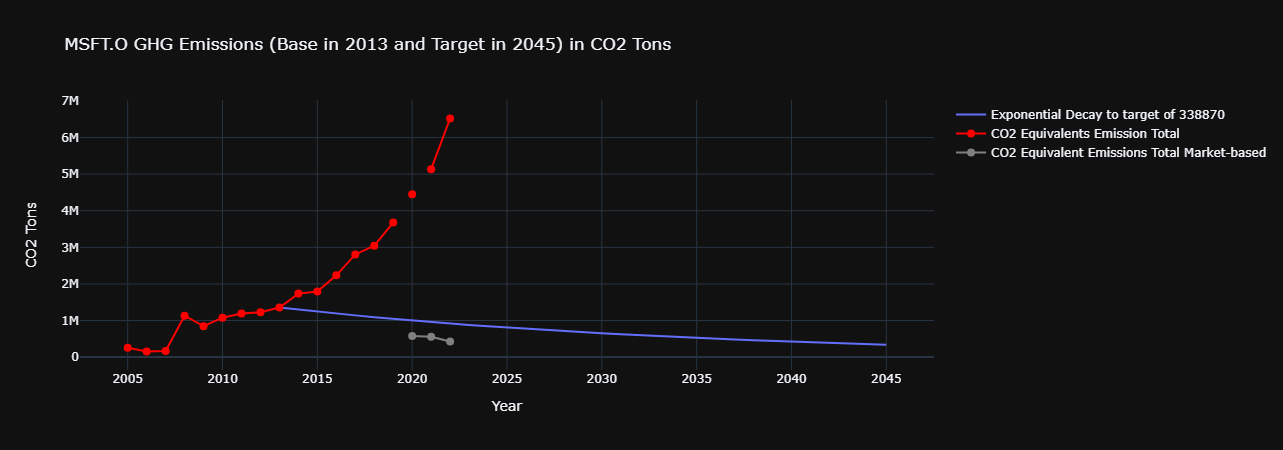
baseEmissionYear = int(df3.filter(like='GHGEMISSIONBASEYEARSET').iloc[-1].values[0])
targetEmissionReductionYear = int(df3.filter(like='GHGEMISSIONTARGETYEARSET').iloc[-1].values[0])
baseEmission = df3[df3.index.year == baseEmissionYear].filter(like='CO2EMISSIONTOTAL').values[0][0]
targetReductionEmission = baseEmission * ((df3.filter(like='GHGEMISSIONPERCENTAGEREDUCTIONTARGETED').dropna().iloc[-1] / 100).iloc[0] * (df3.filter(like='PERCENTAGEOFGHGEMISSIONCOVEREDBYTARGET').dropna().iloc[-1] / 100).iloc[0])
targetEmission = baseEmission - targetReductionEmission
print(f"baseEmissionYear = {baseEmissionYear} & targetEmissionReductionYear = {targetEmissionReductionYear}")
print(f"baseEmission = {baseEmission} & targetReductionEmission = {targetReductionEmission} & targetEmission = {targetEmission}")
baseEmissionYear = 2013 & targetEmissionReductionYear = 2045
baseEmission = 1355480 & targetReductionEmission = 1016610.0 & targetEmission = 338870.0
start_year = df3.T.filter(like=str(baseEmissionYear)).columns.values[0]
end_year = np.datetime64(
f"{targetEmissionReductionYear}-{str(start_year)[5:7]}-{str(start_year)[8:10]}")
start_year = np.datetime64(start_year, 'ns')
end_year = np.datetime64(end_year, 'ns')
start_value = baseEmission
end_value = targetEmission
# Calculate the decay constant 'k' for exponential decay
# We use the formula for exponential decay: y(t) = y0 * exp(-k * (t - t0))
# Solve for 'k' using y(t) at the end point
# time_difference_years = (end_year - start_year).astype('timedelta64[Y]').astype(float)
# k = -np.log(end_value / start_value) / time_difference_years
if end_value / start_value == 0:
k = -np.log(0.01) / (int(str(end_year)[:4]) - int(str(start_year)[:4])) # Use a small value instead of zero to avoid log(0) issue
else:
k = -np.log(end_value / start_value) / ((end_year - start_year).astype('timedelta64[Y]').astype(float))
# Generate years and corresponding values using exponential decay
years = np.arange(
start_year.astype('datetime64[Y]').astype(int) + 1970,
end_year.astype('datetime64[Y]').astype(int) + 1971)
values = start_value * np.exp(
-k * (years - (start_year.astype('datetime64[Y]').astype(int) + 1970)))
decayDf = pd.DataFrame(data=values, index=years, columns=[f'Exponential Decay to target of {int(targetEmission)}'])
df6 = pd.concat([df5, decayDf])
# Create the plot
fig = go.Figure()
# Add the exponential decay line trace
fig.add_trace(
go.Scatter(
x=df6.index, y=df6[f'Exponential Decay to target of {int(targetEmission)}'], mode='lines',
name=f'Exponential Decay to target of {int(targetEmission)}'))
# Set plot title and labels
fig.update_layout(
title=f"{RIC} GHG Emissions (Base in {baseEmissionYear} and Target in {targetEmissionReductionYear}) in CO2 Tons",
xaxis_title="Year",
yaxis_title="CO2 Tons",
template="plotly_dark" # Optional: You can use different templates, such as 'plotly', 'ggplot2', etc.
)
# Add the dots representing the actual CO2 data from df3
fig.add_trace(go.Scatter(
x=df6.index,
y=df6[df6.filter(like="CO2EMISSIONTOTAL").columns[0]],
mode='lines+markers',
name='CO2 Equivalents Emission Total',
marker=dict(color='red', size=8) # Customize the dot color and size
))
fig.add_trace(go.Scatter(
x=df6.index,
y=df6[df6.filter(like="TR.CO2EQUIVALENTEMISSIONSTOTALMARKETBASED").columns[0]],
mode='lines+markers',
name='CO2 Equivalent Emissions Total Market-based',
marker=dict(color='grey', size=8) # Customize the dot color and size
))
# Show the plot
fig.show()
ld.close_session()
All together now
You can find the code for this function in the GitHub repo linked a the top right of this article.
ld.open_session()
df = GHGEmissionsBaseVsTargetUsingLSEGWorkspace(
RIC="SHEL.L", # MSFT.O, AAPL.O, SHEL.L, LVMH.PA
scope="1", # choice between "1", "2", "3", "1 and 2" or "1, 2 and 3"
set=1, # choice from 1 to 5
term="ST", # choice between "ST" and "LT"
source="LSEG") # choice between "LSEG" and "CDP"
ld.close_session()
'GHGEmissionCoveredbyTarget' figures are above 80%. The higher this figure, the more reliable the results.
In this case, we consider them to be high enough to be reliable.
baseEmissionYear = 2016 & targetEmissionReductionYear = 2025
baseEmission = 72000000 & targetReductionEmission = 6480000.0 & targetEmission = 65520000.0

Conclusion
As you can see, it is rather simple to make a target vs. actual emissions graph using both Snowflake and, in this case, Workspace/CodeBook!
Please note that this is not production code and is not to be used in production for investment tools, or used in investment decisions. It is only shown/published for educational purposes.