

Business Incentive
This article focuses on the ingestion phase of an AI pipeline analysing corporate events. Corporate events, such as M&A or bankruptcy announcements, can result in substantial stock price changes. Academic research has shown evidence of significant abnormal returns for target company stocks, making target identification a perfect use case for AI.
The final AI model, which full implementation process can be found in my detailed article is a binary classifier between target and non-target companies. The feature space will therefore include the list of target and non-target companies along with a wide range of financial ratios such as profitability, liquidity, leverage of the businesses.
Data Ingestion through Refinitiv M&A advanced search
Note: The datasets in this guide are created for the purpose of presenting the Data Ingestion phase methodologies of an AI pipeline.
One of the most direct ways to retrieve a dataset on M&A target companies is the M&A Advanced Search section of Refinitiv Workspace. This allows us to specify the search criteria and retrieve an excel file containing the Target company RIC, name, and other specified features of the M&A deals. The screen shot below shows the filters used to request the required data:
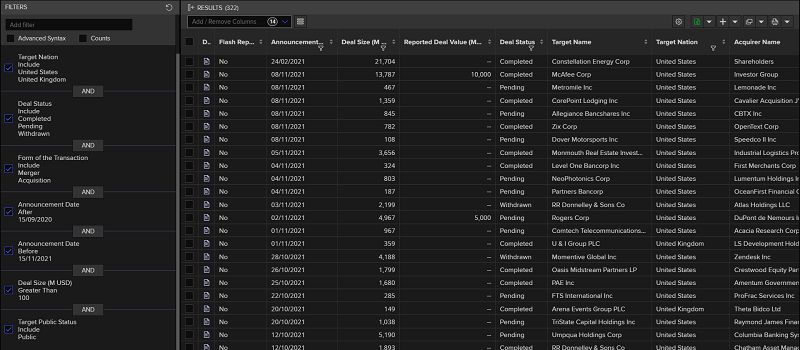
After clicking on the Excel icon on the top right of the interface, an excel file containing the requested data will be downloaded.
While this is a great first step of getting data on M&A using Refinitiv, it is perhaps not the most scaleable approach of data retrieval for AI pipelines. We would want to access the data programmatically and integrate it in the pipeline. One of the underlying reasons is that we want to be able to automaticaly replay the pipeline at any given time. This is perfectly possible by accessing data through APIs, for instance using Data Libraries for Python.
import refinitiv.data as rd
import pandas as pd
import datetime
import time
from refinitiv.data.discovery import Peers
rd.open_session()
The code below requests M&A data using the filters shown in the screenshot above and orders the data by the announcement date in descending order. More on how you can use search, including guidance, examples, and tips to determine the possible approaches, from simple discovery through experimentation to more advanced techniques, are presented in this article.
For the purposes of presenting a Data Ingestion phase workflow, we request data for a short time period (January-April 2022).
deals_search = rd.discovery.search(
view = rd.discovery.Views.DEALS_MERGERS_AND_ACQUISITIONS,
#specify filtering properties
filter = "((AcquirerCompanyName ne 'Creditors' and AcquirerCompanyName ne 'Shareholder') and (TargetCountry eq 'US' or TargetCountry eq 'UK')"
+ "and TransactionValueIncludingNetDebtOfTarget ge 100 and TargetPublicStatus eq 'Public')"
+ "and (TransactionStatus eq 'Completed' or TransactionStatus eq 'Pending' or TransactionStatus eq 'Withdrawn')"
+ "and (FormOfTransactionName xeq 'Merger' or FormOfTransactionName xeq 'Acquisition') and (TransactionAnnouncementDate le 2022-04-14 and TransactionAnnouncementDate ge 2022-01-01)",
#select only the required fields and order them based on announcement date
#then specify number of items to be 10000, default value is 100
select = 'TransactionAnnouncementDate, TargetCompanyName, TargetRIC',
order_by = 'TransactionAnnouncementDate desc',
top = 10000)
deals_search
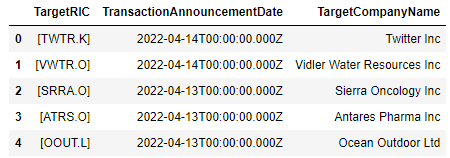
Let's also create a list of RICs which will be useful for the next part of data ingestion - financial ratio retrieval.
#create list of RICs
deals_search['TargetRIC'] = deals_search['TargetRIC'].explode()
deals_search = deals_search.drop_duplicates(subset='TargetRIC')
deals_search = deals_search.dropna(subset=['TargetRIC'])
target_rics = deals_search['TargetRIC'].to_list()
Having defined the list of target companies, the next step is to request financial ratios for them. We need to consider two different workflows of data retrieval depending on whether we want all ratios as of one universal date or as of a specific day for each company, e.g 30 days before the M&A announcement date. In this case, it would be more appropriate to request data as of a specific date for each company. However, we do present both workflows as the first workflow might be applicable for a different use case that could be encountered.
Workflow for ingesting data as of a universal date.
In order to get the financial ratios for the list of companies we use get_data function. We specify the ratios under the field argument and the date in the parameters. Since the request is as of a date for all companies in our list, the request workflow doesn't require loop procedures and multiple API requests. This allows us to receive the data relatively faster. We time the request to compare with the workflow involving looping and multiple API requests.
start_time = time.time()
#specify variables
fields = ["TR.TRBCIndustry", "TR.F.MktCap","TR.F.TotRevenue", "TR.F.ReturnAvgTotEqPctTTM", "TR.F.IncAftTaxMargPctTTM", "TR.F.GrossProfMarg", "TR.F.OpMargPctTTM","TR.F.CurrRatio",
"TR.F.ReturnCapEmployedPctTTM","TR.F.WkgCaptoTotAssets","TR.PriceToBVPerShare","TR.PriceToSalesPerShare","TR.EVToSales",
"TR.F.NetDebttoTotCap","TR.TotalDebtToEV","TR.F.NetDebtPerShr"]
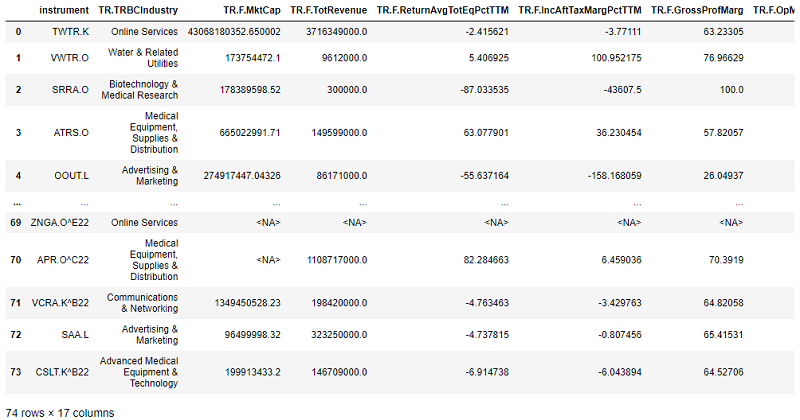
target_data_as_of = rd.get_data(universe=target_rics, fields = fields , parameters = {'SDate': '2021-12-12'})
print("--- %s seconds ---" % (time.time() - start_time))
target_data_as_of
--- 3.043107271194458 seconds ---
Workflow for requesting data as of different dates
Again, we use the get_data function, however, we call it under a loop by updating the date parameter. Since the process involves multiple API requests, it is advised to use a try - except statement to catch and respond to potential errors.
For our use case we want our feature space to be representative to the company fundamentals landscape 30 days prior to the M&A announcement. The snippet below creates a dataframe of deals containing dates materialised 30 days prior to the Announcement date.
#create list of announcement dates including one for 30 days prior to the announcement
deals_search['AD_30'] = (pd.to_datetime(deals_search['TransactionAnnouncementDate']) - datetime.timedelta(30)).dt.strftime('%Y-%m-%d')
request_dates = deals_search['AD_30'].to_list()
The code below calls get_data function for each RIC in the loop and concatenates the per RIC results to re-create the target dataset. We catch RICs throwing an exception, mainly due to connection issues to re-run the API request. Again, we time the request for reference purposes.
start_time = time.time()
target_data = pd.DataFrame()
retries = 0
for i in range(len(target_rics)):
while retries < 3:
try:
#get data for fields as of the specified date
df = rd.get_data(universe=target_rics[i], fields = fields , parameters = {'SDate': request_dates[i]})
#add anoouncement date to the resulting dataframe
df['AD_30'] = request_dates[i]
#append company data to the main dataframe
target_data = pd.concat([target_data, df], ignore_index = True, axis = 0)
except Exception as e:
# print(e)
retries += 1
continue
break
print ("--- %s seconds ---" % (time.time() - start_time))
--- 48.814064741134644 seconds ---
We can see that the code took approximately 48 secs to execute.
Optimising ingestion requests
One important concern during data ingestion is making sure that we have an optimised ingestion layer that is not presenting any unnecessary bottlenecks within our pipeline. This is a proprietary decision, and, in this case, we did notice that there are dates for which multiple M&A has been announced. To optimise our ingestion request we could bundle the deals by date. That will allow us to reduce API calls and retrieve the results much faster.
The code below groups our dataframe by the AD-30 and makes an API call for each date requesting feature values for the list of rics instead of making individual call for each ric.
start_time = time.time()
dfs = dict(tuple(deals_search.groupby('AD_30', sort = False)))
#create empty lists and dataframe to store requested values
target_data = pd.DataFrame()
retries = 0
for date in dfs:
rics = []
for ric in dfs[date]['TargetRIC']:
rics.append(ric)
#get data for fields as of the specified date
while retries < 3:
try:
df = rd.get_data(universe = rics, fields = fields , parameters = {'SDate': date})
#add anoouncement date to the resulting dataframe
df['AD_30'] = date
#append company data to the main dataframe
target_data = pd.concat([target_data, df], ignore_index = True, axis = 0)
except:
retries += 1
continue
break
print("--- %s seconds ---" % (time.time() - start_time))
--- 30.337662935256958 seconds ---
As we see the optimized version of our code returned the data roughly 40% faster due to the decreasing the number of API calls. Considering that there is a daily API call limit and for large requests you may hit that, this approach should always be the go-to strategy for API calls. Furthermore, this is a significant result that can greatly affect our time to data retrieval, in a productionised AI pipeline.
Data Ingestion for non-target dataset
The non-target sample set is constructed from companies similar to target companies in terms of business activity. To identify the non-target control group, this would be a complicated identification process, however, Refinitiv has a great function called Peer Screener which allows us to easily retrieve the top 50 peers of the any company.
The below code stores the RICs and dates into separate lists and calls the Peer Screener function for each RIC. The resulting dataframe is then merged with the main dataframe of peer companies. We present a try/except statement to catch API request errors and allow the code to gracefully handle the exception This is also an important part of any AI pipeline, as there will appear events during which our existing code might fail to handle, we should always provide for failover or pass through scenarios. Furthermore, such events should be logged so that AI engineers can revisit the pipeline and introduce new functionality to handle those.
#create empty lists for error data and a dataframe to store selected peers
retries = 0
peer_data = pd.DataFrame()
for i in range(len(target_rics)):
while retries < 3:
try:
#request Peer function for each target company in the lits
instruments =list(Peers(target_rics[i]))
vals = rd.get_data(universe=instruments, fields = fields, parameters = {'SDate': request_dates[i]})
#add a column for 30 days prior to the M&A announcement
vals['AD_30'] = request_dates[i]
#append target company's peer data to the main dataframe of all peers
peer_data = pd.concat([peer_data, vals], ignore_index = True, axis = 0)
except:
retries += 1
continue
peer_data
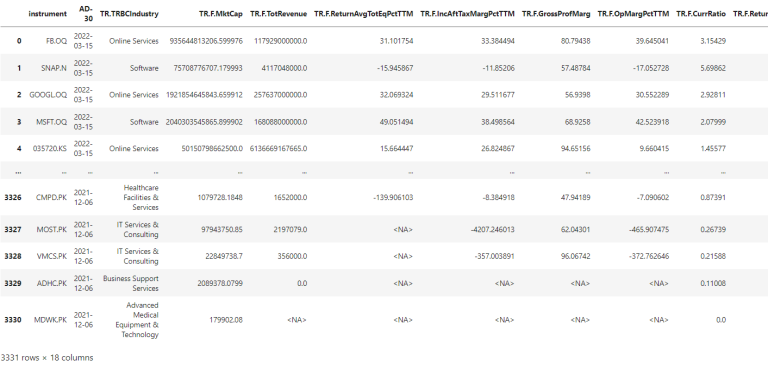
Finally, we will be saving our target_data and peer_data dataframes into excel files to use during the data exploration and data preparation steps which we will be covering in the respective Blueprints.
target_data.to_excel("target_data.xslx")
peer_data.to_excel("peer_data.xslx")
Conclusion
In this guide, we presented the business incentive for an M&A AI model and discussed data ingestion approaches to acquire the dataset for our pipeline. Furthermore, in the next phase of Data Engineering, the Data Exploration phase, we will explore more about the specifics of our dataset and the available feature space.