

Once the data acquisition phase is complete and we have our initial feature space, the Data Exploration phase starts. This phase enables us to uncover insights from the data and/or identify areas or patterns to dive into and further explore. It allows for a deeper, more detailed, and better understanding of the data. This phase will also reveal any problems that the datasets might have, including dataset imbalance, multi-collinearity, missing values, outliers etc. After the problems with the dataset is identified the AI team can start devising strategies towards solving or smoothing them out.
This guide will walk through the exploration process of the M&A dataset we have acquired during the Data Ingestion phase in our Blueprint Data Ingestion for M&A predictive modelling. To learn more about the business incentive and data acquisition process of the analysed dataset please visit the before-mentioned guide.
Import necessary modules and read the dataset
First, let's import the necessary modules that will help us explore and visualise statistical inferences in our dataset.
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
from plotly.graph_objs.scatter.marker import Line
from scipy.stats import ttest_ind, ttest_ind_from_stats
from statsmodels.stats.outliers_influence import variance_inflation_factor
Getting high-level information about the dataset
After reading the ingested datasets created in our Blueprint Data engineering - Data Ingestion for M&A predictive modelling we can request for general information on the structure of the dataframe using the info function. The function will give us basic statistics and meta information on non-null values per feature, dtype of the columns in memory as well as memory usage from the dataframe.
peer_data = pd.read_excel('peer_data.xlsx', index_col = 0)
target_data = pd.read_excel('target_data.xlsx', index_col = 0)
#add labels
target_data['Label'] = 1
peer_data['Label'] = 0
#merge the target and non-target datasets
dataset = pd.concat([target_data, peer_data], ignore_index = True, axis = 0).reset_index(drop = True)
dataset.info()
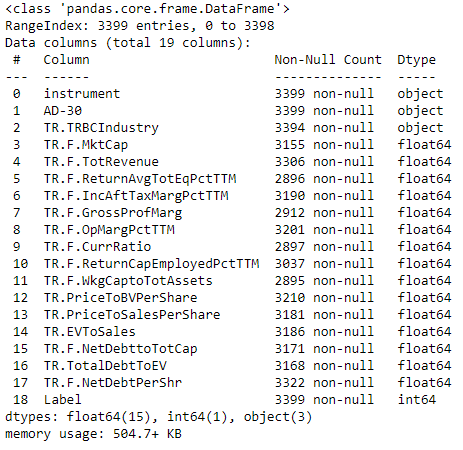
Alongside the dataset information, let's also explore the distribution of records between the two classes.
print(f"Number of target companies in training dataset is: {dataset.loc[dataset['Label']==1].shape[0]}")
print(f"Number of non-target companies in training dataset is: {dataset.loc[dataset['Label']==0].shape[0]}")
Number of target companies in training dataset is: 70
Number of non-target companies in training dataset is: 3329
From the dataset information we can see that there are 15 features, including the RIC, date indicating 30 days prior to announcement, industry, and 13 financial indicators. Most of our variables are numeric and only the industry is a categorical one. When it comes to the RIC and date features, these could be useful during the feature engineering phase rather than being direct inputs of the AI model core. Next thing we observe is that the dataset is labeled for all datapoints. Also, there is some mild to modest imbalancing, reflecting the fact that target companies are a small portion of all companies.
Another observation is that the features contain many null values, and we don't have consistent number of non-null datapoints across features. Finally, we notice that some features are describing the same aspect of a company, i.e. profitability (Income After Tax Margin, Profit Margin), leverage (Net Debt to Total Capita, Debt to EV), Leverage (Current Ratio, Working Capital to Total Assets). Although this is not necessarily a problem, it may cause multi-collinearity issues and therefore bias our models during training. Further in this guide we conduct statistical analysis to identify such patterns.
Let's also observe the qualitative side of our features, particularly the distribution of the features, whether the financial data are relative or absolute valued features, statistical distributions etc. For that we use the dataset.describe() pandas command.
dataset.describe()
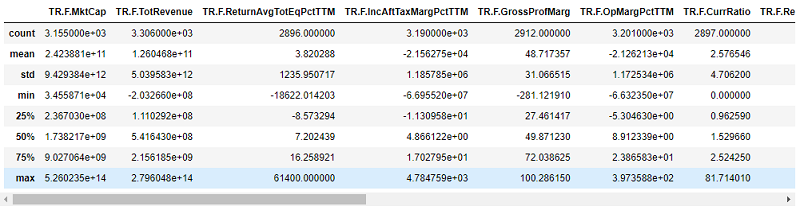
From the above descriptive dataframe we can observe that part of our features is relative measure of the company in the form of ratios (Gross Profit margin, Return on Equity etc.) and many are absolute measures (Market Capitalization, Total Revenue). This can cause biasing issues if used as is. We therefore need to develop strategies that will reformat the data in a more consistent space. These strategies can include dropping some of the features, feature engineering, normalization and more.
We can also notice that the standard deviation is quite high for some of the features. For example, Gross Profit Margin has a standard deviation of 40 with values ranging from -281 to 100. This can be a result of outliers’ existence in our feature space. To understand more about the data, we need to do a deep dive into the individual feature distributions.
fig = make_subplots(rows=2, cols=2)
fig.add_trace(go.Box( x = dataset["TR.F.GrossProfMarg"], name = 'Boxplot'), row=1, col=1)
fig.add_trace(go.Scatter( y = dataset["TR.F.GrossProfMarg"], name = 'DistPlot'), row=2, col=1)
fig.add_trace(go.Histogram( x = dataset["TR.F.GrossProfMarg"], name = 'ScatterPlot'), row=1, col=2)
fig.update_layout(height=800, width=1100)
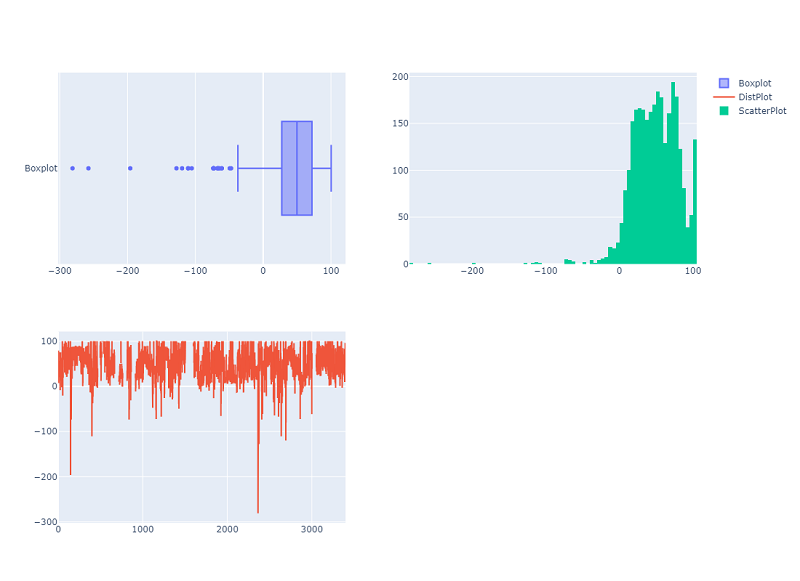
The Boxplot is a very insightful visualisation that allows us to quickly identify outliers. If we consider datapoints which are 3 standard deviations (93) from the mean (46.68) as outliers, any observation outside - 47 to + 130 is an outlier. This is clearly visualized in the graph.
Another detail worth our attention about the Gross Profit Margin Distribution can be observed from the Histogram. There are several companies which have Gross Profit Margins larger than 100. This contradicts the nature of the formula calculating the ratio (Gross Profit Margin can be at maximum 100 if COGS is zero). This indicates the presence of noise in the data distribution which we need to address in the data preparation phase.
Another interesting visualisation is the scatterplot, in this case we notice that most of the companies in our feature space have positive margins.
In reality, during the Data Engineering phase of building AI models, we would want to do this exercise for all of the features, however, we will stop here as the purpose of this guide is just to showcase the major tools and workflows.
Make statistical inferences on the dataset
Amongst other statistical exploration tools that we can use, we need check our features against multi-collinearity which can greatly bias regression models. We can do that by simply looking to a correlation matrix and also conduct a Variance Inflation Factor (VIF) analysis which is a measure of the amount of multi-collinearity in a set of multiple regression variables.
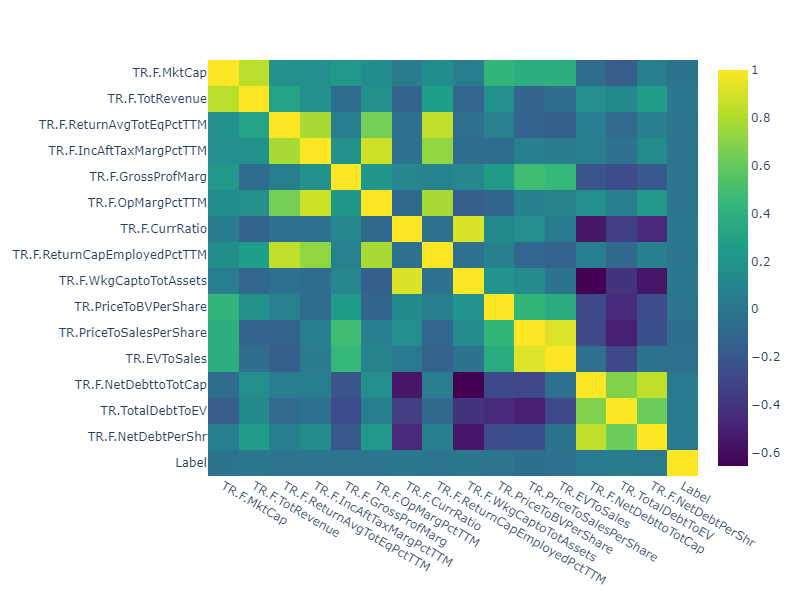
Let's start by generating the correlation matrix. We calculate and show both Spearman and the Pearson correlations, where Spearman is measuring the monotonic relationship between the variables and Pearson identifies the linear relationship.
# get the subset of the dataset
dataset = dataset.iloc[:,3:19]
# calculate spearman correlation
corr_spear = dataset.corr(method ='spearman')
fig = make_subplots(rows=2, cols=2)
fig = px.imshow(corr_spear, aspect="auto", color_continuous_scale='viridis')
fig.update_layout(height=600, width=800)
fig.show()
#calculate pearson correlation
corr_pears = dataset.corr(method ='pearson')
fig = px.imshow(corr_pears, aspect="auto", color_continuous_scale='viridis')
fig.update_layout(height=600, width=800)
fig.show()
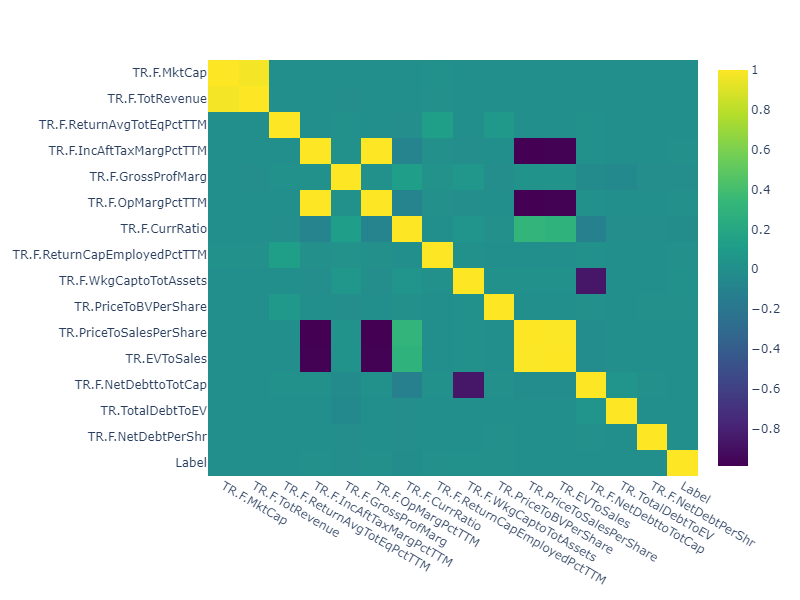
According to the correlation Heatmaps we can see quite a few features correlated with each other. For example, Market Capitalization is highly correlated with the Revenue measure, EV to Sales with Price to sales and more. Moreover, the Pearson correlation identifies stronger correlations suggesting high linear relationship.
The simplest approach to tackle the issue is to drop one of the correlated variables. The VIF test can help us determine which one to drop. The higher the VIF measure, the higher the variance that is captured by the variable. VIF values for other variables will decrease if we iteratively remove the variables with the highest VIF measures.
The code snippet below calculates and presents VIF scores for our features.
dataset.dropna(inplace = True)
# create dataframe to store VIF scores
vif_data = pd.DataFrame()
vif_data["feature"] = dataset.columns
vif_data
# calculate VIF for each feature
vif_data["VIF"] = [variance_inflation_factor(dataset.values, i)
for i in range(len(dataset.columns))]
vif_data = vif_data.T
vif_data.rename(columns = vif_data.iloc[0], inplace = True)
vif_data = vif_data.iloc[1:]
vif_data
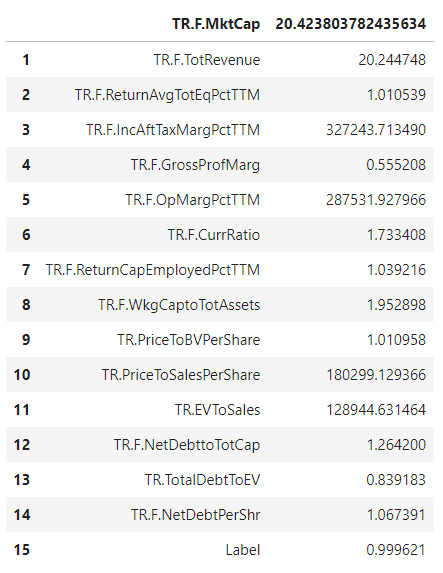
As mentioned above EV to Sales is highly correlated with Price to Sales and from the VIF results, we can see that the VIF on Price to Sales is higher than the one for EV to Sales, therefore the Price to Sales is a good candidate to be removed. However, if this would not be accepted as a solution, any feature engineering approaches can be used to eliminate the multi-collinearity issue.
Another statistical inference that can be made from our dataset and which can be useful especially for AI models addressing classification problems is the significance of the mean differences of features between two classes. That could indicate potential feature importances for our AI model. A T-test analysis is one of the best practices when it comes to making a statistical inference on mean differences between two datasets.
Below we calculate and report T-test measures (along with the statistical significance) for our feature space.
# run t-test
t_test = ttest_ind(dataset.loc[dataset['Label']==1], dataset.loc[dataset['Label']==0], equal_var = False)
#store results in a dataframe
ttest_data = pd.DataFrame()
ttest_data["feature"] = dataset.columns
ttest_data["t_test"] = t_test[0]
ttest_data["p-value"] = t_test[1]
ttest_data = ttest_data
ttest_data.rename(columns = ttest_data.iloc[0], inplace = True)
ttest_data = ttest_data.iloc[1:]
ttest_data
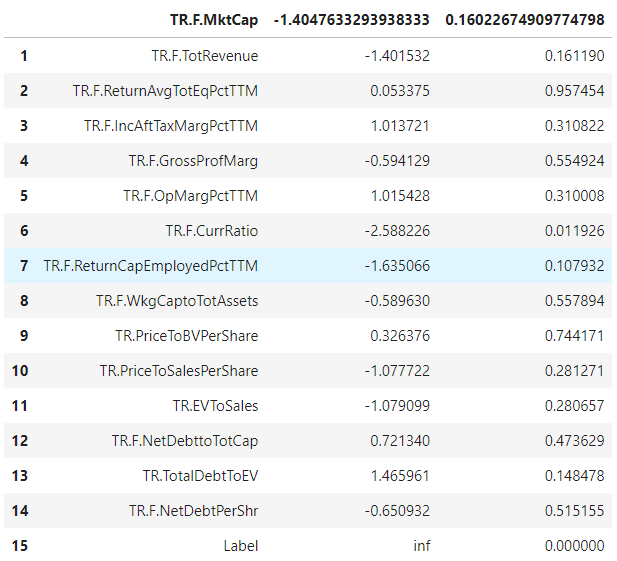
The P-values of the t-test results, suggest that for almost all the features there is no statistically significant mean difference between the two classes, except for the Current ratio. Although we conducted a Welch’s t-test, which doesn't assume equal populations, absence of significant mean differences between our two populations (target and non-target) can be a result of dataset imbalancing. Particularly, our dataset consists of 70 target and 3329 non-target companies which can pose a challenge for the AI model cores and should be addressed before training and evaluation.
Conclusions
In this guide, we presented data exploration methodologies spanning many different levels of detail, from a high level overview of the dataset to detailed statistical inference on multi-collinearities. We note here that, this initial statistical inference process is conducted on the uncleaned dataset and the landscape after dataset cleaning can be different. It is therefore suggested to do this step close to the data preparation phase as well to ensure correct feature selection.