
Article
Building Search into your Application Workflow

Nick Zincone
Lead Developer Advocate
Lead Developer Advocate
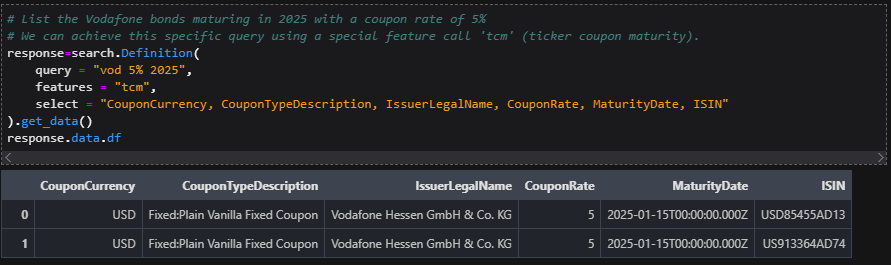
It is very easy to take for granted what modern search provides in our everyday lives. Typing a simple expression can return a wide range of content spanning various subjects, allowing the user to refine and present relevant information. With the wealth of content offered within the LSEG ecosystem, this article introduces the LSEG Search API — a powerful, Google‑like search engine covering content such as quotes, instruments, organizations, and many other assets that can be programmatically integrated into your business workflow.
Contents
The article will be broken down into logical sections allowing easy access and reference when building out your search algorithms.
Prerequisites
The source code demonstrating the various examples are presented in both Python and C#/.Net within a Jupyter notebook. Refer to the GitHub Python or GitHub .Net projects outlining the prerequisites to run the examples.
Overview
The Search family of APIs exposes the desktop Search services through LSEG's Data Platform so that it can be called by clients running outside the corporate firewall.
Search covers over:
77,000,000 quotes
35,000,000 instruments
9,000,000 organizations
2,000,000 people
1,000,000 deals
400,000 physical assets
Supporting the following key features:
Freeform (Google-like) quick search
Extensive filtering and ranking control
Faceted navigation (supplemental information)
Views to limit searches to a subset of content
Metadata services supporting thousands of properties
All examples presented in this article use the LSEG Data Library for Python only.
Note Example packages will include both Python and .Net.
In this article and within the examples packages, I will be utilizing features and capabilities within the following both the Access and Content layers of the library.
# Access Layer
ld.discovery.search(
view = search.Views.SEARCH_ALL,
query = '<free-form query expression>',
filter = '<structured filtered expression>',
select = '<comma-separated list of properties',
boost = '<structure expression ranking results>',
order_by = '<Property> asc',
group_by = '<Property>',
group_count = <numeric count>,
top = <numeric count>,
navigators = '<Property expression>',
features = '<Flag directives>'
)
# Content Layer
response=search.Definition(
view = search.Views.SEARCH_ALL,
query = '<free-form query expression>',
filter = '<structured filtered expression>',
select = '<comma-separated list of properties',
boost = '<structure expression ranking results>',
order_by = '<Property> asc',
group_by = '<Property>',
group_count = <numeric count>,
top = <numeric count>,
navigators = '<Property expression>',
features = '<Flag directives>'
).get_data()
Search
Searching for content can begin with the most basic, free form queries, to more complex filter expressions that can cross-reference the entire search data universe returning results matching your criteria. Content is organized within Views. A View defines properties, or fields, that can be grouped and sorted to suit your requirements.
Views
The data universe has been broken down into logical Views representing the entire data set. For example, if you wish to query for only people, a People View can be specified and a query can be applied only against that specific content set. Here is a list of available Views offered for users on the desktop:
|
|
Views offered to our Wealth clients (Light service):
|
|
Basic Views offered to all clients (also referred to as Search Explore):
|
The API also offers some help documentation that will provide a list of available Views. For example:
// Available Views for the desktop user
// Note: The Python implementation only supports views supported on the desktop. Subsequent releases will
// support both Light and Explore Views.
help(search.Views)
The details and examples within this article will demonstrate a number of different Views.
Note: The examples presented in this article use the full services within Search which are only available to the desktop user. By default, users that have been granted any license to any LSEG Data Platfgorm service will automatically be granted the Search Explore Views. Our Wealth users will be provided the Search Light capabilities. Both versions of search are a scale-down offering compared to the services available on the desktop.
How to approach Search
Depending on the nature of the data you wish to retrieve, Search offers different paths and capabilities to filter, group, and return the desired result set. The more detailed your search specification, the narrower and more accurate the results will be. The following guidelines can be applied.
For desktop users, the recommended approach is to utilize the Advanced Search App available within the LSEG Workspace desktop application. As you begin using Search, you will quickly discover that its capabilities are extremely rich, providing hundreds of available options to help refine your requirements. The Search App enables users to visually construct search algorithms and allows developers to export the corresponding API search parameters for use within their applications.
In addition to offering an intuitive GUI, its greatest value lies in the categorization and taxonomy of attributes that users typically need to filter their expressions and fine‑tune results.
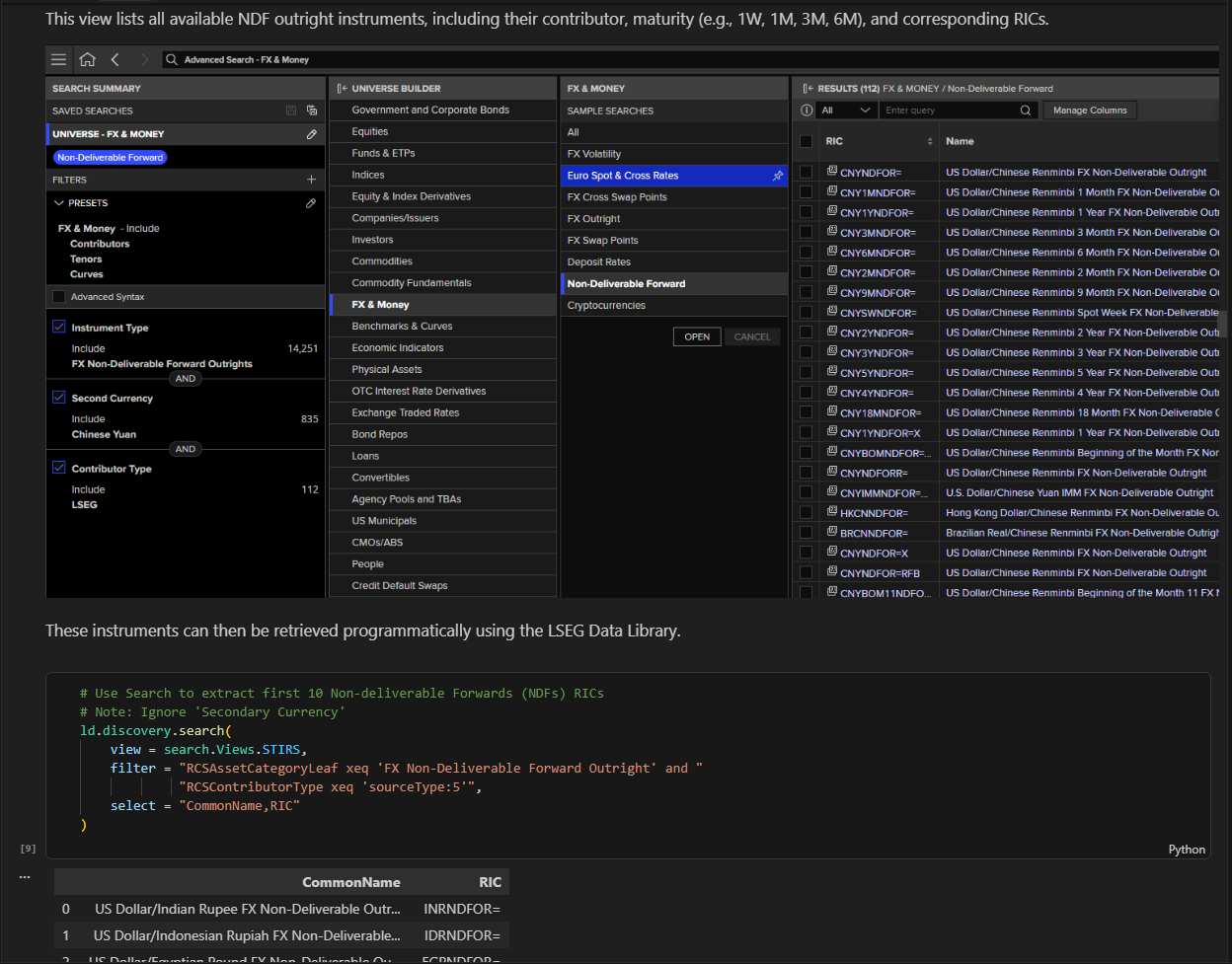
Please refer to the Advanced Search article that walks through the capabilities of the Workspace App and the ability to export the parameters to be used in your applications. For users that do not have access to Workspace, you will need to better understand the steps below to work through the API. However, it is highly recommended to have a general understanding of the details available within the API and how to best approach working with search.
Note: The ordering of the steps below is only a recommendation if you are unfamiliar where to start. As you become more proficient, you will immediately know which step will be most suitable. In addition, as you gain experience, you will realize that there is more than one way to arrive at your results.
Start with the most basic query
Using a query expression will quickly give you a sense of what is returned and whether the result set appears to be relevant. For example, when searching for Organizations or People, you can perform queries like: "Microsoft", "IBM CFO", "Steve Jobs", etc. The complexity of your query will significantly affect the result set. For example, if I choose a vague term like "IBM", this will return over 40,000 hits. Using an unambiguous query like "IBM CFO" significantly narrows the result set down to just a few. Because Query accepts any free-form text, you can be as vague or as explicit as you need.
However, you may have search requirements where Query does not provide the desired output. Alternatively, your query may be too vague such that despite returning results, you are unable to lessen the scope of data returned. Whatever the reason, you can enhance your search by utilizing the Filter mechanism.
Filter the result set using specific properties
One of the central search parameters is the ability to refine or filter your results using logical, structured expressions. The universe of data is organized within Views, each of which contains many properties. When you want to use the Filter mechanism to search, you apply structured expressions against Document Properties to help filter your data. Filters are a great way to refine your result set using simple yet powerful expressions.
The following is a simple expression to filter documents within a specific country:
RCSCountryLeaf eq 'United States'
Refer to the Filter section for more details and the syntax around this capability.
Navigators
Where a Query and Filter will determine what is included within your results, Navigators provide the ability to categorize and summarize the results. For example, if I use a Query to list all ships and their hull types, that are currently out on the water, I will see hundreds of results. If I simply want a list of the different types of hulls for these ships, I can use a navigator to categorize and summarize this into logical buckets.
Navigators can be used against a View, either alone or in conjunction with a query, a filter, or both. Navigators can be simple or very powerful but in general, allow you to collect and organize data within the result set and group that data into logical buckets.
The power of Navigators will allow you to use the values returned within the buckets in your filters. In addition, Navigators offer additional features such as grouping and simple calculations to organize your buckets.
Refer to the Navigators section for more details.
Use Views to narrow down your search
By default, when you perform either a Query or Filter, you are searching against the "SearchAll" View which is a combination of all views within the universe. When you apply a query against a specific View that is relevant to your needs, this can significantly narrow your result set. For example, if I choose to search for 'IBM' using the default View (SearchAll), it will return over 40,000 documents. However, if I'm only interested in a specific View, such as "Instruments", my query will drop down to ~9500 documents. The more you become familiar with the details of the Views and what they offer, the better the results.
Selecting your Properties
A Property represents a column or field for each document hit within the result set. By default, Search will return a well-defined set of Properties, such as DocumentTitle, PermID, etc. For example:
DocumentTitle BusinessEntity PermID RIC PI 0 International Business Machines Corp, Public C... ORGANISATION <NA> <NA> 37036 1 International Business Machines Corp, Ordinary... QUOTExEQUITY 55839165994 IBM 1097326 When choosing your own Properties, you provide a comma-separated list. For example:
"UnderlyingQuoteRIC, RIC, RCSAssetCategoryLeaf, TickerSymbol, UnderlyingIssuerName, ExpiryDateString"
There are hundreds of properties available for you to select when performing a search. The MetaData service provides a list of these properties for a specific View. However, depending on your result set, many properties may not be applicable or available for use. To help understand what properties are available and what their values contain, you can use a simple debugging capability to explicitly select all properties available using the "_debugall" special property. For more details, refer to the Properties - Metadata section.
The above recommendations provide a great start when approaching search. As you educate yourself on the capabilities and the data, you will begin to master specific techniques and the suggestions outlined above. In addition, once you start seeing the results, you can further manipulate the results by boosting, sorting, and grouping the data to suit your needs.
ld.discovery.search("IBM")
| DocumentTitle | BusinessEntity | PermID | RIC | PI | |
|---|---|---|---|---|---|
| 0 | International Business Machines Corp, Public C... | ORGANISATION | <NA> | <NA> | 37036 |
| 1 | International Business Machines Corp, Ordinary... |
QUOTExEQUITY | 55839165994 | IBM | 1097326 |
| 2 | IBM Credit LLC, Private Company | ORGANISATION | <NA> | <NA> | 99244 |
| 3 | IBM Retirement Fund Trust, Private Company | ORGS | <NA> | <NA> | 4297694029 |
| 4 | Tiers Corporate Bond Backed Certificates Trust... | ORGANISATION | <NA> | <NA> | 18062670 |
| ... | ... |
A query matches on composite fields, which are internal and not listed by metadata.
Note: Using the debugging feature, you can see a list of these composite fields as identified with the term 'composite' in the name, e.g.: 'CompositeSearchAll'.
Using the above query, there are a few assumptions here regarding the default behavior. When searching, there are a number of possible parameters that can be applied to help narrow down the result set. To better understand, the following search command is equivalent to the one above:
ld.discovery.search(
view = search.Views.SEARCH_ALL,
query = "IBM",
top = 10
)
By default, Search will occur against all Views, i.e. the entire data universe, returning the first 10 documents using a preset list of fields, or Properties, representing the above columns of data. Query does provide some flexibility to help narrow down the result set.
Query supports the following syntax:
| Feature | Example | Meaning |
|---|---|---|
| Free text | 'chinese shipping' | Matches any document that contains the words 'chinese' and 'shipping', in any order. |
| Phrases | '"hong kong"' | Phrases must appear in quotes. The phrase must match the order as specified. Case and (most) punctuation is ignored. |
| Wildcards | 'green*' | Will match green, greenfield, Greensleeves, etc |
| 'gran?' | Will match grand, grant but not gran or granule | |
| Boolean operators | 'cheese AND wine' | Both cheese and wine must appear in the document |
| 'cheese OR wine' | Either cheese or wine must appear in the document | |
| 'not wine' | The word wine must not appear |
Refer to the Playground Reference documentation for more details and specific behavior when applying query expressions.
While providing a query expression generally results in the desired output, there may be specific instances, depending on the View and what you are looking for, where you want to further refine the output based on the properties returned. Refer to the Filter section for more details.
Filter
One of the most powerful parameters when defining a search is the ability to filter the results. While a Query is more of an unstructured approach to search for text within documents, a Filter provides a well-defined structured approach when I know which fields I want to restrict within the matching documents.
The following is a basic example of a filter expression:
"TickerSymbol eq 'LSEG' and RCSAssetCategoryLeaf xeq 'Ordinary Share'"
A filter expression takes on the basic form:
PropertyName operator value
Like a Query, you can combine expressions with boolean operators as above with the example where I want to filter the search based on documents that contain the token 'LSEG' (London Stock Exchange Group) within the ticker symbol and that for each of these matches, the asset category is an ordinary share. Filters can and are often used in conjunction with a query expression within a search.
Note: The Playground Reference documentation defines the valid operator expressions such as 'eq', 'ne', 'xeq'. Each operator will define specific behavior, so it is important you review the details to ensure you have a complete understanding. For example, in the above expression that used the 'xeq' operator, the documentation states that only properties that are flagged with the 'Exact' attribute can be used. Unlike the 'eq' operator, 'xeq' cannot be used with wild cards and is case-sensitive.
Below, I have defined a search to look for the term 'IBM' within any document, but only collect results where the category is related to people.
ld.discovery.search(
query = "IBM",
filter = "SearchAllCategoryv3 eq 'People'"
)
While it can be fairly straightforward when building filter expressions, the most difficult challenge is how to determine the available properties to use and the values they contain?
Because the search facility is very rich in terms of how to formulate your expressions and the different paths you can take, in many cases, there can be multiple ways to arrive at your desired outcome. Whatever path you take to formulate your expressions, knowledge of which properties to use will be at the heart of your decision.
Defined within the Properties - Metadata section, I include a number of different techniques to help, not only the beginner, but advanced users to derive the properties to refine search results. You can be quite clever and creative when defining these expressions. The Filter section, defined within the Playground Reference provides a comprehensive outline of the types of expressions using well-defined syntax.
Navigators
Navigators provide the ability to summarize the distribution of your results. They are particularly useful when you are interested in gathering the domain of values for a specific property. Navigators can be used against a specific View, used in conjunction with either a query, a filter, or both. Navigators can be simple or very powerful, but provide a very useful way to capture results in logical buckets.
To demonstrate why you may want to use a Navigator as a preferred way to retrieve data, I will use the following query to retrieve the first 100 tankers to get a sense of what the different type of hulls there are and which types are most often used:
ld.discovery.search(
view = search.Views.VESSEL_PHYSICAL_ASSETS,
query = "tanker",
top = 10000 # Upper limit
)f
| DocumentTitle | HullType | |
|---|---|---|
| 0 | FPSO YUUM KAK NAAB, LNG Tanker, BW OFFSHORE SI... | Single Hull |
| 1 | MOZAH, LNG Tanker, NAKILAT SHIPPING QATAR LTD,... | Single Hull |
| 2 | UMM SLAL, LNG Tanker, NAKILAT SHIPPING QATAR L.. | Single Hull |
| ... | ||
| 9997 | ZHONG HAI 16, Other Tanker, Shanghai|Shang... | <NA> |
| 9998 | OOSTZEE, Other Tanker, English Channel... | <NA> |
| 9999 | YUESHAOGUANHUO2138, Other Tanker, South ... | <NA> |
Here, I can see a list of the different tankers and their Hull Types. The above displays only 1 Hull Type: "Single", and a bunch of vessels that do not have a HullType association, i.e. <NA>. I could expand the display to view the HullTypes within this collection but I'm only looking at the first 10,000 hits, which is the limit that I'm allowed to see in a single query. I could use a GroupBy feature which would help narrow down the list but I may also want to capture the distribution of how many of each type are there. . To avoid this effort, I can instead use a Navigator.
Using the above query, I will apply a Navigator by selecting the 'HullType' property. What this does is instruct search to bucket all unique Hull Types and summarize the total found for each.
The basic syntax of a Navigator is:
navigators = "PropertyName(arg1:value, arg2:value, ...), ..."
To retrieve all the available Hull Types using a Navigator:
response=search.Definition(
view = search.Views.VESSEL_PHYSICAL_ASSETS,
query = "tanker",
top = 0, # I'm only interested in the navigator response section
navigators = "HullType"
).get_data()
response.data.raw["Navigators"]["HullType"]["Buckets"]
[{'Label': 'Double Hull', 'Count': 16919},
{'Label': 'Single Hull', 'Count': 5092}]
Not only will this tell me there are 2 hull types, but will also provide distribution for each. In addition, I don't have to contend with the limitations of the server - I'm not returning hits, only the navigator results. Navigators can be extremely useful when you want to collect and categorize your results. Navigators can be used to simply list all values within a property or as complex as aggregating and sorting results within logical buckets.
Refer to the Examples section showing the power of Navigators. For a detailed list of the nested arguments and capabilities, refer to the Search Documentation.
Sorting and Grouping
The Search service offers the ability to organize your result set in different ways. Whether you choose to sort based on a specific property, group properties, or boost the result set, you have the option to override the default order returned. By default, the result set will provide some basic ranking, depending on the type of query or filter performed.
For example when choosing to search for a ticker symbol using the following filter:
ld.discovery.search(filter = "TickerSymbol eq 'VOD'")
Will return many documents, ranked by the symbols that are more significant or liquid. So in the above case, you will see the primary RIC code, "VOD.L", ranked at the top because it is the most significant instrument in the result set.
However, If I want to boost the result set for the above filter so that all the instruments that are traded on US exchanges appear at the top, I can apply a boost expression such as:
boost = "RCSExchangeCountryLeaf eq 'United States'"
Will force all documents where 'VOD' traded on any US exchange will be boosted to the top.
While boosting can organize specific documents to appear at the top, I may choose to organize my documents based on a value in an ascending or descending order. To do this, I need to specify a list of properties using the order_by parameter. For example:
order_by = "lastName, FirstName"
Is an expression that I can apply against a People View. The ordering expression will sort by the last name. The secondary property 'FirstName' is used to break a tie.
Finally, you may perform a query that lists duplicate items, such as a country or exchange. You can choose to group like properties together to help organize your output. For example:
group_by = "ExchangeCode"
Will collect all identical exchange codes within the output and group them together.
Additional details around these parameters are available within the Playground Reference documentation. To see a few of these in action, refer to the Examples section.
Properties / Metadata
The document properties or Properties represent the fields that define the data elements you want to retrieve as well as the elements you choose to filter your results. In addition, Properties are at the heart of other Search parameters such as Navigation, Grouping, and Boosting. There are hundreds of Properties available for each View providing critical details needed to fulfill your searching requirements.
In order for you to be successful at search, you will need to understand how to access the available Properties, how to determine what values they contain, and what they mean.
Metadata
The metadata service provides the ability to list all available properties within a View. To properly build a metadata list for inspection, you can issue the following:
response = search.metadata.Definition(
view = search.Views.GOV_CORP_INSTRUMENTS
).get_data()
response.data.df
In the above call, I'm requesting the list of Properties available within the View: GOV_CORP_INSTRUMENTS. Once executed, I can export it to an Excel spreadsheet for convenience:
# Export metadata to a spreadsheet for easy viewing
response.data.df.to_excel("GovCorpInstruments.xlsx")
The output will list all available properties and some important attributes for each. For example:
| Type | Searchable | Sortable | Navigable | Groupable | Exact | Symbol | ||
|---|---|---|---|---|---|---|---|---|
| AccrualDate | AccrualDate | Date | True | True | True | False | False | False |
| AccruedInterest | AccruedInterest | Double | True | True | True | False | False | False |
| ... | ... | |||||||
| RatingsScope | Agency | String | True | False | False | False | False | False |
| CurrentRatingDate | Date | True | True | False | False | False | False | |
| CurrentRatingRank | Date | True | True | False | False | False | False | |
| RatingType | String | True | False | False | False | False | False | |
| ... | ... | |||||||
| RCSCountryLeaf | RCSCountryLeaf | True | True | True | True | True | True | False |
| ... | ... |
Each property determines how it can be used in the different parameters defined within Search. For example, some properties are sortable, navigable, searchable, etc. Refer to the Playground Reference documentation for a comprehensive outline of the output and a definition of each attribute.
Note: While the names of the properties do provide some reference as to their meaning, I understand that this may be challenging to fully comprehend what these properties mean. We are planning on enhancing the attributes to include important details such as a description. Until enhancements are available, you can infer the meaning based on the names of the properties as well as some debugging techniques defined below to better understand their values.
Debugging (_debugall)
While MetaData will help list all properties available within a View, all properties will not be available for use. That is, depending on the type of search you perform, will determine which properties will be populated - not all will be. This is where users can use a technique to list all available properties that are populated, for the specific search requested.
For example:
# Query for all documents with the company IBM defined and dump some debugging info
response = search.Definition(
query = "IBM",
top = 1, # Specify a value of 1 to limit output and load on the server
select = "_debugall"
).get_data()
response.data.raw
By selecting the special property called: "_debugall", this will list all properties and some internal meta-properties that provide additional debugging details. The key takeaway from this technique is the output will carry up to hundreds of available properties that are populated for your use - whether to be used for selection, filtering, or navigation. This technique can be extremely useful to identify values in certain properties.
Note - This technique should only be used for debugging. This setting does put an excessive burden on the service and should not be used for regular document processing. While this technique can be useful to help understand the availability and values of properties, the amount of output can be quite extensive, which is why the call above only requested 1 document.
Using Navigators to help understand values
When reviewing the debugging output, a number of common properties can be used when filtering your search. For example, you may want to filter your results based on certain categories or data belonging to a specific sector. Using navigators will help us understand the values contained within specific properties.
For example, when reviewing debug output from the above query, you may notice a very useful property called: SearchAllCategoryv3. This property helps us understand all available categories of documents the query term 'IBM' was found. To list these categories, use the following:
response = search.Definition(
query = "IBM",
top = 0,
navigators = "SearchAllCategoryv3"
).get_data()
response.data.raw
Output will list all categories such as: 'Equities', 'Futures', 'Commodities', 'Companies/Issuers', 'People', etc. From here, I can use the 'SearchAllCategoryv3' property to help filter out unwanted traffic. That is, if we're only interested in documents related to people, I can now enhance the search to look like this:
# Query for documents in the 'People' category where the company IBM defined
ld.discovery.search(
query = "IBM",
filter = "SearchAllCategoryv3 eq 'People'",
)
Special Properties
The Search service includes a number of special properties that enhance the ability to find meaningful results.
| Property | Meaning |
|---|---|
| _debugall | Based on the query or filter, return every field or property available within the selected documents. Extremely useful to understand which properties are affected and the values they contain. Available as a single specification within a select. Details outlined above. |
| code | The 'code' specification will search across all codes, such as RICs, tickers, SEDOLs, etc. Primarily used within a filter but can be used as a selectable property. |
| name | The 'name' specification will search across all names, such as common name, legal name, issuer name, etc. Primarily used within a filter but can be used as a selectable property. |
| _ | The special character underscore (_) is a convenient token that can be used to select the default Properties. This will allow users to quickly choose the default values plus any other properties when testing out your search. |
Common Properties
As you become more familiar with Search, you will soon recognize there will be a number of very useful properties that will act as your "go-to's" when filtering or selecting fields. Here are a few to get you started:
| Property | Meaning |
|---|---|
| IsActive | When you generally want to know if an asset is active or not, you should apply this property. Where AssetState (below) defines an explicit code, this property categorizes the state as a boolean. If this property is not available, you should turn to the 'AssetState' property and apply your logic there to determine the active state. |
AssetState / AssetStateName |
Defines the specific state of an asset:
Note: Not all assets will carry this property. Alternatively, you can use 'IsActive' to provide a boolean state. |
| DocumentTitle | Convenient property that describes the content within a document. It is made up of the following child Properties: 'DTSubjectName', 'DTSimpleType', 'DTSource', and 'DTCharacteristics'. By default, this property is selected or included if you explicitly specify the special underscore (_) token within a select. |
| SearchAllCategoryv3 | When trying to narrow down your search to specific categories, this property can be extremely useful. When you apply a Navigator on this property, it will return a list of ~40 categories. Categories include asset-related instruments such as 'Equities', 'Futures' , 'Options', 'Bonds', 'Commodities' but can also include things like: 'People', 'Analyst', 'Officers'. |
| CodeResolutionBase | Represents the most significant codes defined within the document. For example, when searching for a symbol such as ISIN, SEDOL, RIC, etc, filtering against this property will significantly reduce the matches and only bring back the most relevant results. |
In addition to the above, there are a number of popular properties based on the Reuters Classification Scheme (RCS) that provide some critical tools when searching. When you review the metadata for a View or look at the output from a '_debugall' dump, you will notice many different RCS-based properties.
As outlined in Using Navigators to help understand values, you can list the values of a navigable property, such as an RCS-based property which provides critical details you can use. For example, to help understand values within an RCS-based property, you can apply a Navigator such as:
# List all the asset types available
response = search.Definition(
top = 0,
navigators = "RCSAssetCategoryLeaf",
).get_data()
response.data.raw["Navigators"]["RCSAssetCategoryLeaf"]["Buckets"]
Many of these RCS-based properties are grouped to provide a logical organization you can use to help understand the nature of the data and how to utilize each to help narrow down your search results. The following table outlines the basic groupings for the different RCS-based properties:
| RCS Property Grouping | Meaning |
|---|---|
| <RCS Property> | Defines a code for the RCS property. For example, the RCSAssetCategory property can contain the value 'A:J', which represents a 'Bond'. |
| <RCS Property>Leaf | Defines a convenient description for the RCS property code. For example, the RCSAssetCategoryLeaf property represents a description of the property RCSAssetCategory. For example, 'Bond'. |
| <RCS Property>Genealogy | In many cases, an RCS property is organized within a hierarchy. For example, the RCSAssetCategoryGenealogy property can contain the value: 'A:2\\A:J'. Separated by the double backslash (\\), each code represents the hierarchy the specific RCS property is part of. |
| <RCS Property>Name | To support the Genealogy property codes, this RCS property defines a convenient description of the hierarchy. For example, the RCSAssetCategoryName property can contain the value: 'Fixed Income\\Bond' which is equivalent to the 'A:2\A:J' defined within the genealogy above. |
Below are a number of common RCS-based properties:
| RCS Property | Meaning |
|---|---|
| RCSAssetCategory | Specific to assets, the 'Leaf' version of this property will categorize the results into a readable identifier such as: 'Bond', 'Commodity Future', 'Commercial Paper', etc. Where the property SearchAllCategoryv3 provides general categories, this property will be more specific to assets. |
RCSCountry RCSIssuerCountry RCSExchangeCountry |
Specific to some assets will allow you to narrow your search to focus on a specific country. |
| RCSCurrency | Specific to some assets will allow you to narrow your search to focus on a specific currency. |
| RCSTRBC2012 | Represents the industry sector. Using either the 'Genealogy' or 'Name' variant of this property will allow you to filter on different levels within the sector hierarchy. For example, if I filter on 'Technology' using the 'Name' variant, will include all documents in the technology sector. |
Limits
Search is intended as an interactive tool rather than a facility for bulk processing. To avoid abuse and excessive heavy usage, the service does have upper limits in terms of the data set returned. Heavy usage can be a result of users blasting requests in a very short period of time or if the overall service is experiencing excessive load. Please refer to the reference guide within the playground for more details.
While it can be frustrating dealing with these limits, there are some possible suggestions that can be used to help.
Rate Limits
When running into issues related to overall load and heavy usage, users will need to throttle their requests. Issues such as blasting the service with too many requests in a short period of time can be managed. However, you will need to be aware that the service as a whole may have an excessive burden that may also affect the frequency and timing of your requests.
Upper Limits
The underlying service enforces an upper limit in terms of the results requested. In some cases, this can be managed through techniques such as grouping or by using navigators. However, if your requirement is to retrieve an excessive amount of results within a single call, you will likely need to be more creative as to how you can segment your search requests to capture the domain of content.
For example, if I choose to request for a list of all exchanges in the United States, I may start with a basic search like this:
ld.discovery.search(
view = search.Views.EQUITY_QUOTES,
filter = "RCSExchangeCountryLeaf eq 'United States'",
top = 10000, # This is presently the limit
select = "ExchangeCode"
)
This will list all the exchange codes, but because each matched document is an individual instrument, you will receive duplicate exchange codes. As a result, the upper limit will be hit.
| ExchangeCode | |
|---|---|
| 0 | IOM |
| 1 | IOM |
| 2 | IOM |
| ... | |
| 9997 | PNK |
| 9998 | PNK |
| 9999 | PNK |
While you can try to intelligently segment the requests to retrieve the whole universe, it is anything but an easy task. Instead, the preferred approach is to use a Navigator. Navigators are specifically designed to capture and summarize properties within logical buckets. For example, the following search will use a navigator to collect all unique exchange codes in the United States:
ld.discovery.search(
view = search.Views.EQUITY_QUOTES,
filter = "RCSExchangeCountryLeaf eq 'United States'",
top = 0,
navigators = "ExchangeCode(buckets:1000)"
)
In the above request, I'm explicitly specifying a 'top' of 0 because the result set is different than the output from a navigator - in my case, I don't need to see any hits, only the buckets defined within my navigator.
The output will look something like this:
[{'Label': 'ONE', 'Count': 1441128},
{'Label': 'OPQ', 'Count': 1259871},
{'Label': 'IOM', 'Count': 836660},
{'Label': 'PNK', 'Count': 70243},
{'Label': 'CBT', 'Count': 59510},
{'Label': 'OBB', 'Count': 32934},
{'Label': 'OTC', 'Count': 22355},
...
The above search request will provide a complete list of exchange codes. In addition, you can also observe the distribution, i.e. instance count, of each.
Segmenting the search
When I started with the first search to retrieve the list of exchange codes within the United States, I discovered that the result set returned the entire universe of instruments. If the goal is to capture the entire instrument list, I cannot group and bucket the result set as I did above. The # of hits returned is over 4 million so I am forced to go through a tedious process of segmenting the requests.
One way to do this is to choose some kind of indicator that will allow you to group your individual requests to successfully segment the result set. However, you need to first ask yourself - do I need the entire data universe? You may only be interested in a specific asset category thus reducing the universe of results significantly.
Refer to the Limits example for an outline on how to segment your search to avoid hitting limits.
While it may be possible to pull out excessive amounts of data, you should ask yourself if you need to do this. In most cases, you may be able to reduce the result set when you set up your search instead of pulling in everything and then massage the results once you have them in hand. Search was designed specifically to allow users to filter out unwanted content prior to returning the results. If you think this way through your searching patterns, you will undoubtedly avoid situations where you need to create complicated algorithms to unnecessarily pull excessive amounts of data. Whether narrowing the request based on the interested categories, or data for a specific region, you will find that you can significantly simplify your logic and avoid issues with limits.
Examples
The following table outlines the organization of the examples available within the GitHub Python or GitHub .NET code packages. Each code package contains a number of Jupyter Notebooks demonstrating some of the details outlined within this article.
| Feature | Code Example | Details |
|---|---|---|
| Query | Simple expressions, phrases, boolean expressions, and wild card usage. | |
| Filter | Query vs Filter, common filter usage, filters using nested properties. Numerous examples show equity, bond, commodities, and people inquiries. |
|
| Properties & Metadata | Retrieving metadata for inspection within spreadsheets. Guidelines showing how to determine the properties to use within your search using the metadata, debug output, and navigators. |
|
| Navigators | List property values; bucket specification and summary calculations. | |
| Sorting | Demonstrates default ranking, boosting, grouping, ordering, and bucket sorting using navigators. | |
| Limits | How to deal with server limitations. | |
| Expired Assets | Samples searching for expired assets. |
Final Thoughts
Integrating search within your applications can be extremely powerful given the tools and content available. Looking at the example packages, you will notice there is more than one way you can arrive at your results. The tips and tricks offered within this guide will help you launch into search very quickly, but there is so much more that will help unleash the power of this service.
While this article focuses on some key techniques and different ways you can approach search, you likely want to better understand the finer details as you become more experienced with this service. The Playground Search reference documentation provides a detailed breakdown of some of the finer details that are mentioned in this article.
Get In Touch
Documentation
Source Code
Related APIs
Request Free Trial
Call your local sales team
Americas
All countries (toll free): +1 800 427 7570
Brazil: +55 11 47009629
Argentina: +54 11 53546700
Chile: +56 2 24838932
Mexico: +52 55 80005740
Colombia: +57 1 4419404
Europe, Middle East, Africa
Europe: +442045302020
Africa: +27 11 775 3188
Middle East & North Africa: 800035704182
Asia Pacific (Sub-Regional)
Australia & Pacific Islands: +612 8066 2494
China mainland: +86 10 6627 1095
Hong Kong & Macau: +852 3077 5499
India, Bangladesh, Nepal, Maldives & Sri Lanka:
+91 22 6180 7525
Indonesia: +622150960350
Japan: +813 6743 6515
Korea: +822 3478 4303
Malaysia & Brunei: +603 7 724 0502
New Zealand: +64 9913 6203
Philippines: 180 089 094 050 (Globe) or
180 014 410 639 (PLDT)
Singapore and all non-listed ASEAN Countries:
+65 6415 5484
Taiwan: +886 2 7734 4677
Thailand & Laos: +662 844 9576