
Authors:


Ecological, social and governance measures are gaining importance in the realm of financial services. On the one hand, investors' principles and their recognition of non-financial risks connected to exploitative business lead to a growing green capital market. On the other hand, allocating capital for ecological and social companies promotes sustainable development as it is aimed for e.g. in UN's 17 SDGs (sustainable development goals). As a reaction to climate change and human rights movements ESG measures will become legally relevant in the forseeable future.
This article shows how ESG-Data can be used in portfolio decisions. The present text is standalone and targets readers who are interested, but not neccessarily familiar with portfolio optimization.
Overview
We follow roughly the steps in Jason Ramchandani's Portfolio Optimisation and build up an effective frontier from Markowitz' classical portfolio selection theory. But in difference to the classical risk-return-approach, we aim at a low risk combined with high ESG score.
For details on ESG measures we refer to Gurpreet Bal's article "How to integrate ESG data into investment decisions". We enhance his approach of selecting an ESG subset of a given index by requiring a lower bound on the TR ESG Score.
Technical Prerequisites
- LSEG Workspace with access to the Data Library (Free Trial Available)
- Python 3.x
- Required Python Packages: lseg.data, pandas 0.17.0 or higher, numpy, scipy, matplotlib
Portfolio selection as a glance
In portfolio selection, a set of shares is given, e.g. an index, for example all shares listed in DAX. From this so-called universe, a combination of shares is selected into a portfolio. The selection follows some conditions and optimization goals. A classical condition on portfolios is an upper bound on the weight of a single share preventing high risks due to one very strong component. Classical goals are for instance a maximal expected return of the portfolio, a minimum mean variance, or low risk measures. In this tutorial, we will include a high ESG-Score into the optimization goal.
import lseg.data as ld
import pandas
import numpy
import matplotlib.pyplot as plt
import scipy.optimize as sco
import os
ld.open_session()
Getting instruments and data
Our portfolio will be built from a universe (or a pre-selection) of shares. We will work based on ETF iShares Core MSCI World UCITS ETF USD which is based on the MSCI World index.
Reading a universe from the Data Library
We use the Data Library to get the constituents of the index. For simplicity we will reduce the list of entries here to 100.
N=100
constituents = ld.get_data(['IWDA.L'], ['TR.FundHoldingRIC', 'TR.FundHoldingName'])
constituents.rename(columns={'Holding RIC': 'ric', 'Holding Name': 'name'}, inplace=True)
constituents = constituents[['ric','name']][0:N]
display(constituents)
| ric | name | |
| 0 | FITB.OQ | FIFTH THIRD BANCORP ORD |
| 1 | HOLX.OQ | HOLOGIC ORD |
| 2 | 8630.T | SOMPO HLDGS INC ORD |
| 3 | CTSH.OQ | COGNIZANT TECHNOLOGY SOLUTN CL A ORD |
| 4 | 6965.T | HAMAMATSU PHOTONICS ORD |
| .. | ... | ... |
| 95 | CBOE.Z | CBOE GLOBAL MARKETS INC ORD |
| 96 | 8031.T | MITSUI ORD |
| 97 | OREP.PA | L OREAL S.A. |
| 98 | BDEV.L | BARRATT DEVLPMNT |
| 99 | DAST.PA | DASSAULT SYSTEMES ORD |
[100 rows x 2 columns]
Reading instruments time series price data
We get the time series of our chosen instruments for one year. We need to remove the NA data in order to prevent problems with calculating the covariance matrix.
start='2020-01-01'
end='2020-12-31'
instruments = constituents['ric'].astype(str).values.tolist()
ts =pandas.DataFrame()
for r in instruments:
try:
ts1 = ld.get_history(r,'TRDPRC_1',start=start,end=end,interval='daily')
ts1.rename(columns = {'TRDPRC_1' : r}, inplace=True)
ts =pandas.concat([ts, ts1], axis=1)
except:
continue
ts = ts.dropna()
| FITB.OQ | HOLX.OQ | 8630.T | CTSH.OQ | 6965.T | AVV.L | WCN.N \ | |
| Date | |||||||
| 07/01/2020 | 29.85 | 52.49 | 4280 | 60.32 | 4555 | 3789.54556 | 92.58 |
| 08/01/2020 | 29.92 | 52.29 | 4188 | 60.73 | 4490 | 3815.21564 | 93.27 |
| 09/01/2020 | 30.25 | 53.275 | 4228 | 61.11 | 4545 | 3828.05068 | 93.75 |
| 10/01/2020 | 29.76 | 53.17 | 4239 | 60.64 | 4530 | 3805.58936 | 93.82 |
| 14/01/2020 | 29.74 | 53.53 | 4213 | 61.37 | 4575 | 3905.06092 | 95.13 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 21/12/2020 | 27.165 | 75.23 | 4038 | 80.47 | 6030 | 3199 | 101.64 |
| 22/12/2020 | 26.93 | 74.67 | 4034 | 81.02 | 5880 | 3213 | 102.72 |
| 23/12/2020 | 27.73 | 75.06 | 4068 | 80.99 | 5920 | 3209 | 101.23 |
| 29/12/2020 | 27.28 | 71.74 | 4186 | 80.5 | 6060 | 3281 | 101.48 |
| 30/12/2020 | 27.28 | 71.75 | 4173 | 81.07 | 5900 | 3225 | 101.84 |
| BAMa.TO | FERG.L | BCE.TO | ... | 5101.T | 7259.T | G24n.DE | TRYG.CO \ | |
| Date | ... | |||||||
| 07/01/2020 | 50.093358 | 6948 | 60.48 | ... | 2112 | 4045 | 59.45 | 200 |
| 08/01/2020 | 50.300025 | 6980 | 60.64 | ... | 2054 | 3985 | 59.35 | 197.5 |
| 09/01/2020 | 50.746692 | 7146 | 60.29 | ... | 2088 | 3945 | 60.4 | 197.5 |
| 10/01/2020 | 50.846692 | 7078 | 60.52 | ... | 2066 | 3900 | 60.25 | 199.1 |
| 14/01/2020 | 52.35336 | 7216 | 60.89 | ... | 2049 | 3905 | 60.45 | 204.4 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 21/12/2020 | 50.98 | 8818 | 54.75 | ... | 1565 | 3125 | 67.05 | 188.1 |
| 22/12/2020 | 51.11 | 8890 | 54.6 | ... | 1560 | 3140 | 67.4 | 187.3 |
| 23/12/2020 | 51.81 | 8858 | 54.66 | ... | 1530 | 3110 | 67.35 | 187.8 |
| 29/12/2020 | 52.88 | 9004 | 54.69 | ... | 1558 | 3120 | 66.8 | 192 |
| 30/12/2020 | 52.72 | 8890 | 54.6 | ... | 1534 | 3095 | 67.05 | 192.1 |
| 8411.T | CBOE.Z | 8031.T | OREP.PA | BDEV.L | DAST.PA | |
| Date | ||||||
| 07/01/2020 | 1682 | 118.22 | 1971 | 259.6 | 762.2 | 148.7 |
| 08/01/2020 | 1668 | 117.01 | 1949 | 261.2 | 761.2 | 150.5 |
| 09/01/2020 | 1677 | 116.01 | 1981.5 | 262.8 | 758 | 152.45 |
| 10/01/2020 | 1672 | 115.85 | 1971.5 | 263.9 | 756.2 | 154 |
| 14/01/2020 | 1666 | 115.49 | 1972.5 | 263.8 | 781 | 154 |
| ... | ... | ... | ... | ... | ... | ... |
| 21/12/2020 | 1315.5 | 90.26 | 1904.5 | 295.6 | 636.4 | 159.85 |
| 22/12/2020 | 1312 | 90.71 | 1876 | 301.8 | 649 | 163.25 |
| 23/12/2020 | 1293 | 91.1 | 1864.5 | 303.7 | 676 | 165 |
| 29/12/2020 | 1315 | 91.66 | 1911 | 312.2 | 681.6 | 166.85 |
| 30/12/2020 | 1307.5 | 92.62 | 1889.5 | 313.2 | 680.2 | 167.55 |
[208 rows x 100 columns]
Reading ESG-data from the Data Library
LSEG provides a large bunch of data connected to ESG-evaluation of companies. In this exemplary portfolio selection, we use the TR.TRESGScore which ranges from 0 to 100.
df_esg = ld.get_data(instruments, ['TR.TRESGScore','TR.BusinessSummary'])
df_esg = df_esg.rename(columns={'Instrument':'ric', 'ESG Score':'esg'}).set_index('ric')
df_esg = pandas.concat([constituents.set_index('ric'), df_esg], join='inner', axis=1)
df_esg
| ric | name | esg | Business Description |
|---|---|---|---|
| FITB.OQ | FIFTH THIRD BANCORP ORD | 69.891816 | Fifth Third Bancorp is a bank holding company ... |
| HOLX.OQ | HOLOGIC ORD | 73.698711 | Hologic, Inc. is a developer, manufacturer and... |
| 8630.T | SOMPO HLDGS INC ORD | 71.080134 | Sompo Holdings, Inc. is a Japan-based company ... |
| CTSH.OQ | COGNIZANT TECHNOLOGY SOLUTN CL A ORD | 58.391002 | Cognizant Technology Solutions Corporation is ... |
| 6965.T | HAMAMATSU PHOTONICS ORD | 60.111937 | HAMAMATSU PHOTONICS K.K. is a Japan-based comp... |
| ... | ... | ... | ... |
| CBOE.Z | CBOE GLOBAL MARKETS INC ORD | 46.769310 | Cboe Global Markets, Inc. is a holding company... |
| 8031.T | MITSUI ORD | 71.280614 | Mitsui & Co., Ltd. is a general trading compan... |
| OREP.PA | L OREAL S.A. | 79.008395 | L'Oreal SA is a France-based cosmetics company... |
| BDEV.L | BARRATT DEVLPMNT | 69.361833 | Barratt Developments PLC is a holding company.... |
| DAST.PA | DASSAULT SYSTEMES ORD | 57.005719 | Dassault Systemes SE is a France-based softwar... |
100 rows × 3 columns
Unconstrained minimum volatility portfolio (MVP)
As a first step, we calculate the classic minimum volatility portfolio.
Calculate past returns and covariance matrix
We calculate the past returns using pandas. We need to remove the NA numbers, that will be occuring in the first row -and possibly elsewhere.
returns = ts.pct_change().replace(numpy.inf, numpy.nan).dropna()
covMatrix = returns.cov()
def risk_measure(covMatrix, weights):
return numpy.dot(weights, numpy.dot(covMatrix, weights))
First, we set the boundary conditions for the single weights that should range between 0 and 1.
constraints = {'type': 'eq', 'fun': lambda weights: weights.sum() - 1}
The minimum volatility portfolio (MVP) portfolio is computed by scipy's optimize function, which returns a result 'res' that includes the portfolio weights 'res['x']' and the minimized risk measure 'res['fun']'. We evaluate the number of instruments in the portfolio, the minimum and maximum weights, the MVP's (historical) annual return, it's volatility, and also the ESG score.
mvp = sco.minimize(lambda x: risk_measure(covMatrix, x), # function to be minized
len(instruments) * [1 / len(instruments)], # initial guess
bounds=bounds, # boundary conditions
constraints =constraints, # equality constraints
)
mvp_weights = list(mvp['x'])
mvp_esg = numpy.dot(mvp_weights, df_esg['esg'])
mvp_risk = mvp['fun']
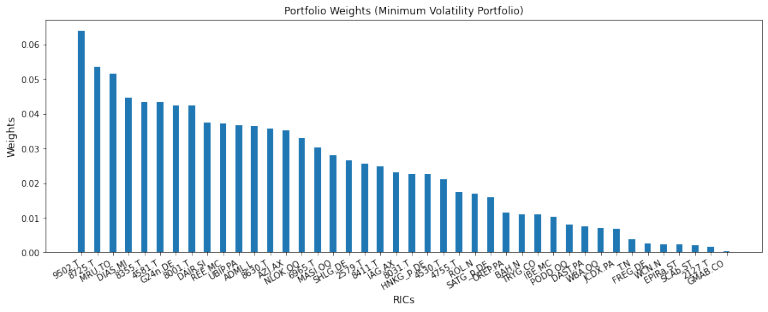
print('\nMVP in a universe with {N} instruments\nNumber of selected instruments: {n}\nMinimum weight: {minw}\nMaximum weight: {maxw}\nHistorical risk measure: {risk}\nHistorical return p.a.: {r}\nESG score: {esg}'.format(N=N,n=numpy.sum(mvp['x']>0),minw=numpy.min(mvp['x'][numpy.nonzero(mvp['x'])]),maxw=numpy.max(mvp['x']),risk=mvp_risk,r=numpy.dot(mvp_weights,returns.sum()),esg=mvp_esg))
MVP in a universe with 100 instruments
Number of selected instruments: 65
Minimum weight: 2.44826270139076e-20
Maximum weight: 0.06396593250127255
Historical risk measure: 0.0001294899285868813
Historical return p.a.: 0.07872510570868128
ESG score: 55.31860881168306
Results
We use a pandas DataFrame to assign the weights to the instruments, sort them by size and remove the very small ones for the plot (note that in order to use the sort_values function your pandas version needs to be higher than 0.17.0).
df_weights =pandas.DataFrame(data=mvp_weights, index=instruments)
df_weights =df_weights.sort_values(by=[0], ascending=False)
df_weights =df_weights[df_weights > 1e-4].dropna()
df_weights =df_weights.T
#plotting the weights
plt.figure(figsize=(15, 5))
ypos = numpy.linspace(0, 100, num=len(df_weights.iloc[0,:]))
plt.bar(ypos, df_weights.values[0], width =1)
plt.xticks(ypos, df_weights.columns, rotation =30, ha ='right')
plt.xlabel('RICs', fontsize=12)
plt.ylabel('Weights', fontsize=12)
plt.title('Portfolio Weights (Minimum Volatility Portfolio)', fontsize=12)
plt.show()
MVP for prescribed ESG score
We are now interested in selecting a portfolio with a higher ESG score than the MVP. This additional restriction is implemented via a second constraint in scipy's optimize. Note that the prescribed ESG score should be higher than the MVP's ESG -- we are the good guys, and want more ecological, social and governance value! On the other hand, the maximum ESG can be achieved by simply investing all the money into the highest rated instrument -but that would be too much of a risk, we want more diversity. This yields an upper bound on a meaningful setting for the prescribed ESG.
prescribed_esg = 80
esg_constraint = {'type': 'eq', 'fun': lambda weights: numpy.dot(weights, df_esg['esg']) - prescribed_esg}
esgmvp = sco.minimize(lambda x: risk_measure(covMatrix, x), # function to be minized
len(instruments) * [1 / len(instruments)], # initial guess
bounds=bounds, # boundary conditions
constraints =[constraints, esg_constraint], # equality constraints
)
esgmvp_weights = list(esgmvp['x'])
esgmvp_esg = numpy.dot(esgmvp_weights, df_esg['esg'])
esgmvp_risk = esgmvp['fun']
print('\nMVP with prescribes ESG = {pe} in a universe with {N} instruments\nNumber of selected instruments: {n}\nMinimum weight: {minw}\nMaximum weight: {maxw}\nHistorical risk measure: {risk}\nHistorical return p.a.: {r}\nESG score: {esg}'.format(N=N,n=numpy.sum(esgmvp['x']>0),minw=numpy.min(esgmvp['x'][numpy.nonzero(esgmvp['x'])]),maxw=numpy.max(esgmvp['x']),risk=esgmvp_risk,r=numpy.dot(esgmvp_weights,returns.sum()),esg=esgmvp_esg,pe=prescribed_esg))
MVP with prescribes ESG = 80 in a universe with 100 instruments
Number of selected instruments: 66
Minimum weight: 2.0241858872983442e-20
Maximum weight: 0.09328007383074229
Historical risk measure: 0.00024141858003072668
Historical return p.a.: 0.15745991254900046
ESG score: 80.00000000021717
Results
We use a pandas DataFrame to assign the weights to the instruments, sort them by size and delete the very small ones:
df_weights =pandas.DataFrame(data=esgmvp_weights, index=instruments)
df_weights =df_weights.sort_values(by=[0], ascending=False)
df_weights =df_weights[df_weights > 1e-4].dropna()
df_weights =df_weights.T
#plotting the weights
plt.figure(figsize=(15, 5))
ypos = numpy.linspace(0, 100, num=len(df_weights.iloc[0,:]))
plt.bar(ypos, df_weights.values[0], width =1)
plt.xticks(ypos, df_weights.columns, rotation =30, ha ='right')
plt.xlabel('RICs', fontsize=12)
plt.ylabel('Weights', fontsize=12)
plt.title('Portfolio Weights (Minimal Risk with ESG Score 80)', fontsize=12)
plt.show()
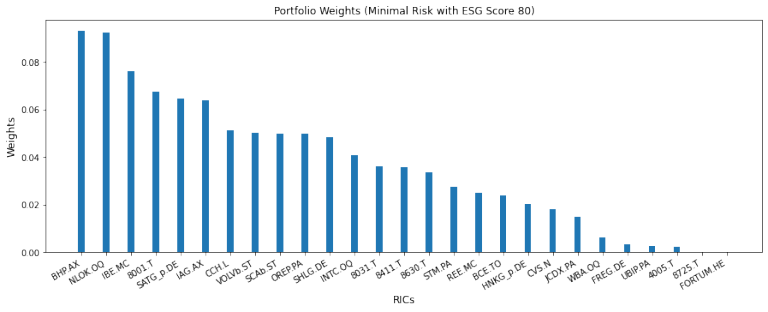
The risk measure of the resulting portfolio is increased compared to the MVP, because we optimize over a more restricted set -- namely, only those portfolios providing the prescribed ESG score instead of all possible portfolios. But nothing is said about the historical return: In this example, it is increased by a factor of about 2 compared to the MVP. Demanding more value for the climate, the environment and for humans can thus lead to higher return.
ESG-efficient frontier
Portfolios can be evaluated with respect to return and volatility, and plotted as dots into a respective coordinate system. In the classical context of H. Markowitz, the efficient frontier is a line that consists of all those portfolio-dots, which are efficient in the following sense: There is no other portfolio which has the same return at a lower risk.
We adjust this idea to the ESG context by replacing Markowitz's return with the ESG score. From a mathematical viewpoint, both measures are very similar: The return/ESG of a portfolio is computed as a scalar product of a vector with return/ESG scores of the instruments with the weights vector.
To build up the ESG-efficient frontier, we calculate several optimal portfolios with different prescribed ESG values. The prescribed ESG values will be in the range between the MVP's ESG, and the maximum ESG of all instruments in the underlying universe. We save the resulting portfolio weights, their ESG value and their risk measure in our results dictionary.
max_esg=numpy.floor(max(df_esg['esg'].values.tolist())) #max esg value to be achieved dependent on the universe
min_esg=mvp_esg #min esg value which is interesting for portfolio selection
results = {'esg_val':[],'weights':[],'risk':[],'return':[]}
for rho in numpy.linspace(min_esg,max_esg,num=25):
constraints2 = {'type': 'eq', 'fun': lambda weights: numpy.dot(weights, df_esg['esg']) - rho}
res = sco.minimize(lambda x: risk_measure(covMatrix, x), # function to be minized
len(instruments) * [1 / len(instruments)], # initial guess
bounds=bounds, # boundary conditions
constraints =[constraints, constraints2], # equality constraints
)
weights = list(res['x'])
esg_val= numpy.dot(weights, df_esg['esg'])
results['esg_val'].append(esg_val)
results['weights'].append(weights)
results['risk'].append(res['fun'])
results['return'].append(numpy.dot(weights,returns.sum()))
plt.plot(results['risk'],results['esg_val'], 'o')
plt.xlabel('risk')
plt.ylabel('esg_val')
plt.show()
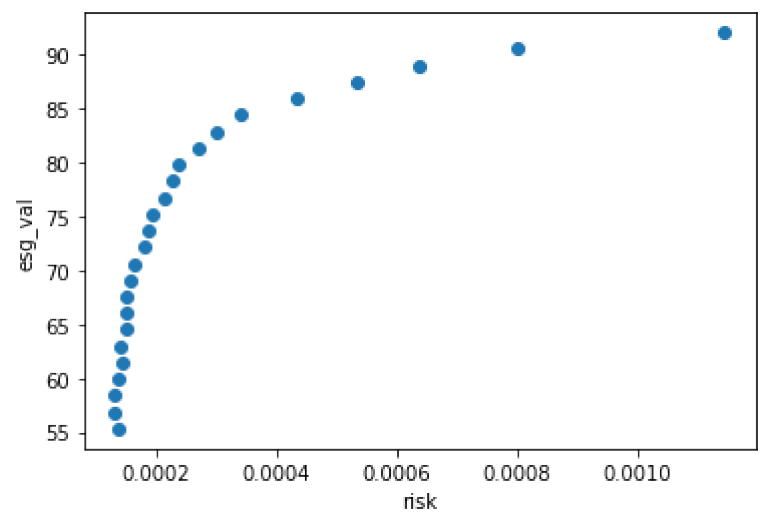
Remark on the trade-off between risk and ESG rating in this model
The fact that a higher ESG score comes with higher risks is intrinsic to this model, but it does not fully recover reality (that's always the problem with mathematical models . . . ). One just minimizes over a subset, and the minimum will thus increase. As a remedy, one can enlarge or change the universe. In this way, almost any combination of ESG score, risk measure and (expected) return can be achieved.
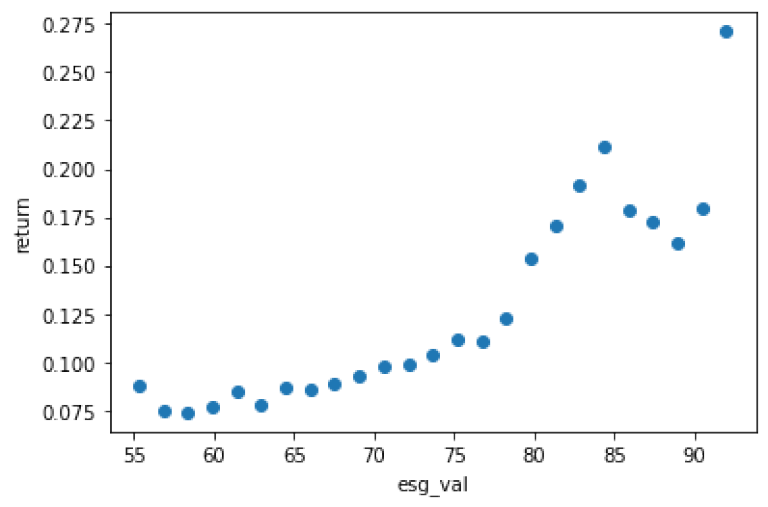
A happier fact (also kind of model-intrinsic) is that higher ESG scores come with higher returns within the ESG-efficient portfolios:
plt.plot(results['esg_val'],results['return'],'o')
plt.xlabel('esg_val')
plt.ylabel('return')
plt.show()
Outlook
This tutorial focuses on employing ESG-data in portfolio selection. For this purpose, we chose simple models for returns and risks. One can enhance both measures, e.g. by forecasting methods, weighted or non-smooth risk measures, and more. Furthermore, we did not consider the expected return in our optimization and utilized only one out of a bunch of ESG data that is available via the Data Library. One can include more constraints or add terms to the objective functional of the optimization problem.
For more information about the authors, check out https://goldmarie-finanzen.de!
Further Resources for the Data Library can be found in its page in the developer portal.
For Content Navigation of the Data Library - please use the Data Item Browser Application: Type 'DIB' into Workspace Search Bar.