

Umer Nalla
Developer Advocate
Developer Advocate

Wasin Waeosri
Developer Advocate
Developer Advocate
Introduction to Data Library
The Data Library is latest evolution of library that provides a set of ease-of-use interfaces offering coders uniform access to the breadth and depth of financial data and services available on the Workspace, Delivery Platform, and Real-Time Platforms. You can find more details about the previous versions of libraries on Essential Guide to the Data Libraries - Generations of Python library (EDAPI, RDP, RD, LD) article.
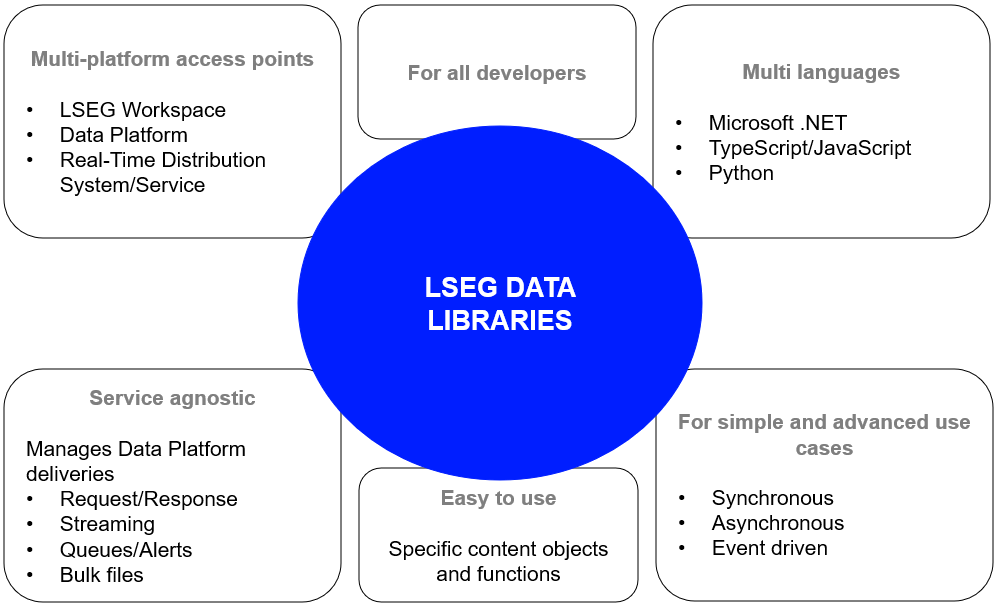
The library is available the following programming languages
This article is focusing on the Data Library for Python version 2 (LSEG Data Library, aka LD Library - As of May 2025).
Data Library - Raison D'être
Whilst LSEG offers huge breadth and depth of data content, it often involves multiple technologies, delivery mechanisms and data formats - and therefore the use of multiple APIs to access this content.
We recognize this is not ideal and we are gradually moving as much of our content as possible onto our Platforms.
If we are going to place the content in one place, it would be ideal if a single library could be used to access that content too.
And with the rise of Citizen Developers - those whose primary role is not Computer Science related - access to the data should be as simple and easy as possible.
Therefore, the Data Library has been designed with the following objectives in mind:
- Simplify integration into all LSEG platforms - Desktop, Deployed or Cloud
- Provide a consistent API experience - learn once and apply across the wealth of Refinitiv content
- Reach the largest audience of developers possible from Citizen developers to seasoned professionals
So, how does the Data Library deliver on those objectives?
One Library - Four Delivery Modes
Currently, the vast breadth and depth of data we provide often requires accessing multiple services with different delivery modes and therefore learning and coding with multiple APIs
Using this single library, you will be able to consume data across those different delivery modes:
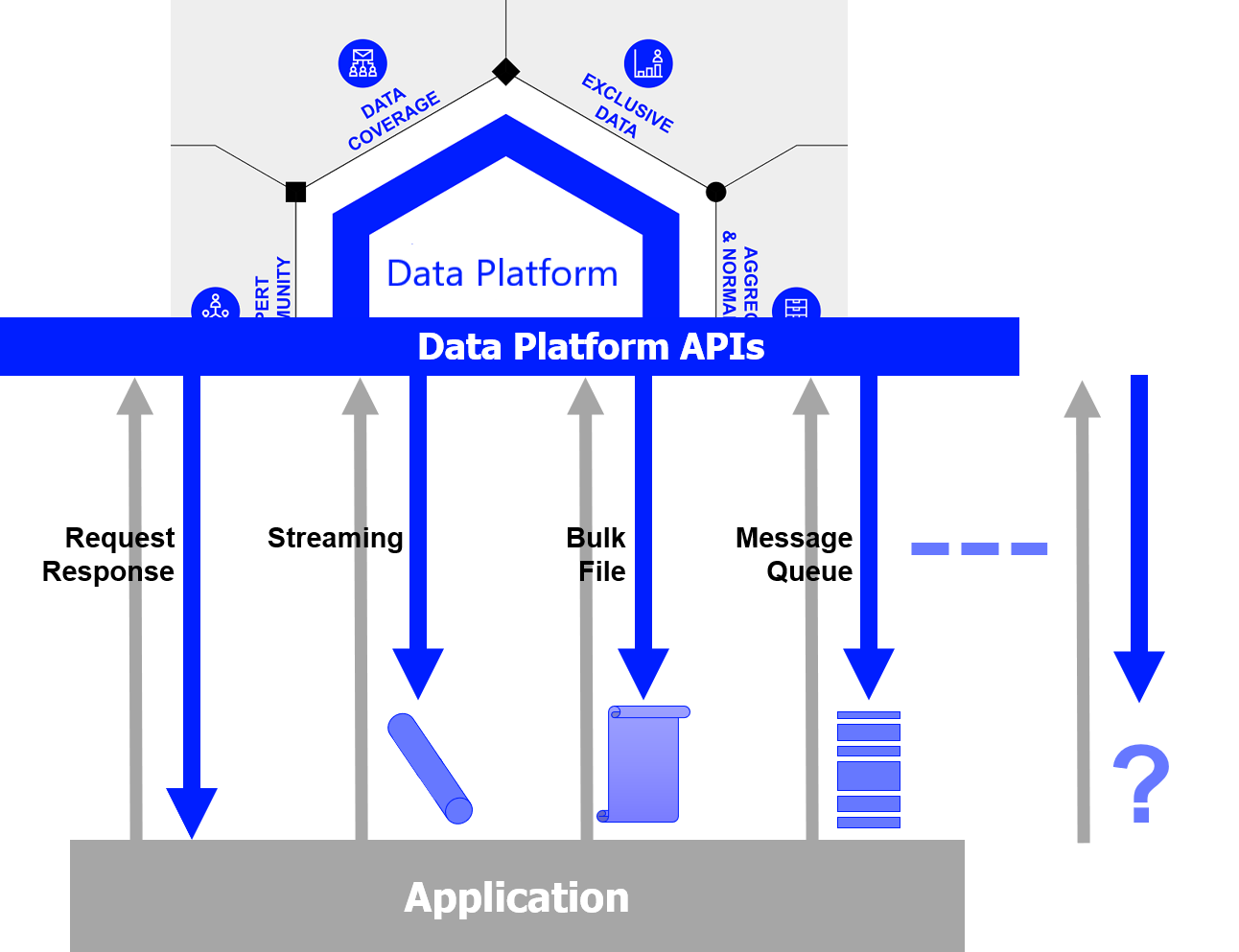
- Request Response - Historical pricing event & summary data, news, fundamentals, analytics, research, ESG etc.
- Streaming – Level 1 Trade & Quote data, Level 2 Order book data, internally published custom domains
- Bulk File – End of Day reports
- Queues – Alerts using the Amazon SQS Queue mechanism
One Library - Three Access Points
The Data library lets consume data from the following platforms
- Desktop - LSEG Workspace platform
- Cloud-based - Delivery Platform (aka Data Platform)
- Deployed - deployed or managed Real-Time Distribution System (RTDS formerly known as TREP)
Using the library you can access content from all 3 of the access points - all from within the same application if required. One example would be sourcing realtime streaming Pricing data from your RTDS server as well as say historical pricing events from the cloud-based Data platform.
Another unique advantage is that you could develop your application against one platform and then redeploy against a different platform as and when required. For example, you could develop an application consuming real-time streaming data from your internal RTDS and then switch that to the Realtime in Cloud service in the future.
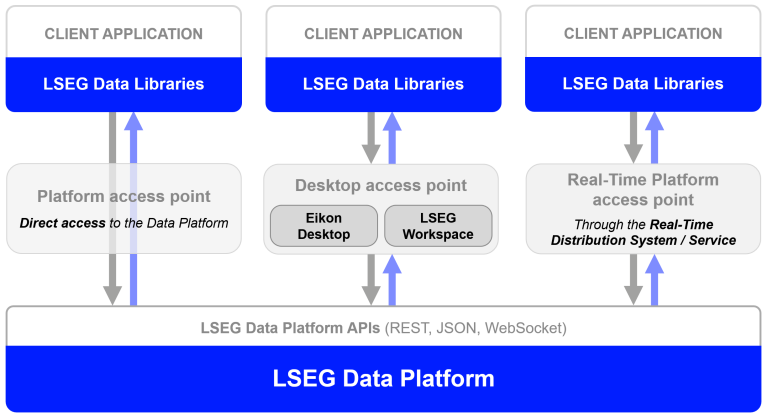
OR, you could develop a Proof of Concept application against your Workspace Desktop and then potentially roll that out to other users within the organization by redeploying against the Cloud. Changing an application to switch access point simply involves changing the session type, so instead of creating say a Desktop session, you would create a Cloud Platform session - see later for an example.
One Library - Four Abstraction Layers
In order to cater for all developer types, the library offers 4 abstraction layers from the easiest to the slightly(!) more complex.
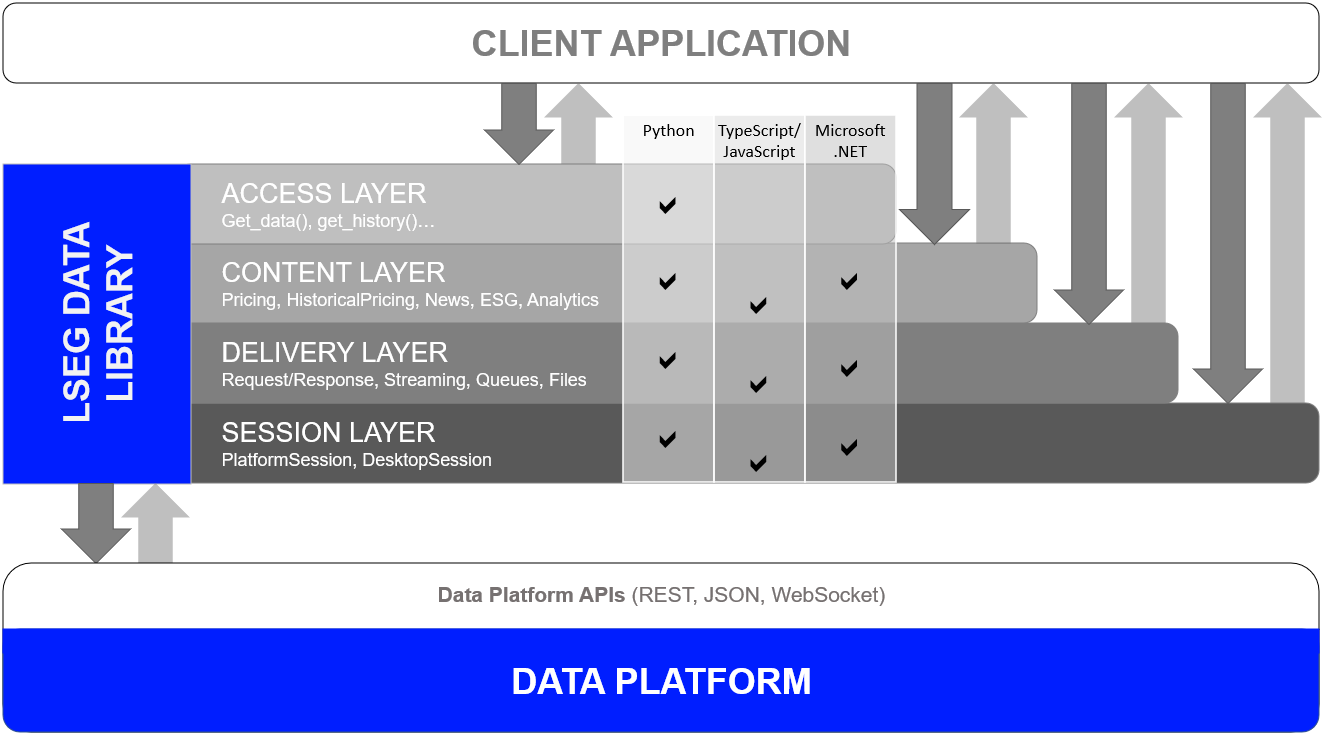
The four layers are as follows:
- Access: Highest level - single function call to get data
- Content: High level - Fuller response and logical market data objects
- Delivery: Low level - lets developers interact with the platforms via various delivery modes (HTTP Request-Response, Stream, Queue, File)
- Session: Manage all authentication and connection semantics for all access points.
Please note that the Access, Content, and Delivery layers are built on top of the Session Layer.
Let us start with the first one that an application code needs to interact with, the Session layer.
Session Layer
The session layer provides interface to for the following tasks:
- Defining authentication details.
- Managing connection resources.
- Implementing the necessary protocol to communicate with the Platform.
Depending on the access point your application uses to connect to the platform, it can choose from one of the session implementations to initiate the connection. For the creation phase, all session implementations expose the same API and behave in the same way.
The library lets developers configure authentication and connection detail via a configuration file name lseg-data.config.json file.
The file format is as follows:
{
"logs": {
"level": "debug",
"transports": {
"console": {
"enabled": false
},
"file": {
"enabled": false,
"name": "lseg-data-lib.log"
}
}
},
"sessions": {
"default": "platform.ldp",
"platform": {
"ldp": {
"app-key": "YOUR APP KEY GOES HERE!",
"username": "YOUR LDP LOGIN OR MACHINE GOES HERE!",
"password": "YOUR LDP PASSWORD GOES HERE!",
"signon_control":true
},
"ldpv2":{
"client_id": "YOUR V2 CLIENT ID GOES HERE!",
"client_secret": "YOUR V2 CLIENT SECRET GOES HERE!",
"signon_control":true,
"app-key": ""
},
"deployed": {
"app-key": "YOUR APP KEY GOES HERE!",
"realtime-distribution-system": {
"url" : "YOUR DEPLOYED HOST:PORT GOES HERE!",
"dacs" : {
"username" : "YOUR DACS ID GOES HERE!",
"application-id" : 256,
"position" : ""
}
}
}
},
"desktop": {
"workspace": {
"app-key": "YOUR APP KEY GOES HERE!"
}
}
}
}
You can specify the preferable session with the default parameter of the configuration file itself:
{
"sessions": {
"default": "desktop.workspace",
}
}
- With the platform.ldp session, the library establishes the connection to the Data Platform on Cloud using the Version 1 Authentication.
- With the platform.ldpv2 session, the library establishes the connection to the Data Platform on Cloud using the Version 2 Authentication.
- With the desktop.workspace session, the library establishes the connection to the Workspace Platform (via Workspace desktop application).
- With the platform.deployed session, the library establishes the connection to local deployed RTDS server.
Then place the lseg-data.config.json in the same location as your Python code. An application can establish a connection to the selected platform via the following code:
import lseg.data as ld
ld.open_session()
Once the session is created and opened, the application can use it in conjunction with objects of the other layers (access layer, content layer, or delivery layer) to get access to the breadth and depth of LSEG content and services available on the selected Platform.
To close the session, you can call this function at the end of the application code to clean up resources.
ld.close_session()
You can find more detail about example of Session configuration for each platform, Programmatic configuration, and tutorials from the following resources:
- Data Library for Python Quick Start Page
- Data Library for Python and its Configuration Process article.
- Data Library for Python Session example
Moving on to the next layer, the easiest to use - the Access layer.
Access Layer
For the easiest access to the most commonly used data content, the Access layer is the place to start.
Firstly we need to establish a connection (see the Session layer section above). Once connected to the desired access point, we can go ahead and request some content.
Market Price Snapshots
The get_data() function allows you to retrieve pricing snapshots as well as Fundamental & Reference data via a single function call.
# Snapshot Pricing Data
ld.get_data(
universe=['LSEG.L', 'VOD.L'],
fields=['BID', 'ASK']
)
The function returns data as Dataframe object.
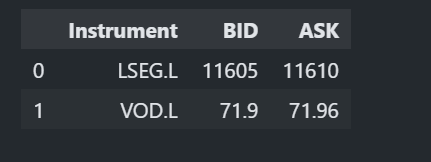
The function also support Fundamental Data request (the function also supports mix of pricing snapshots and fundamental data too).
# Fundamental Data
ld.get_data(
universe=['LSEG.L', 'VOD.L'],
fields=['TR.Revenue']
)
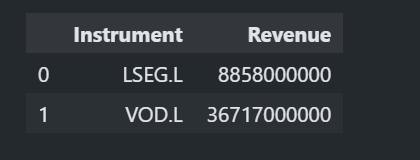
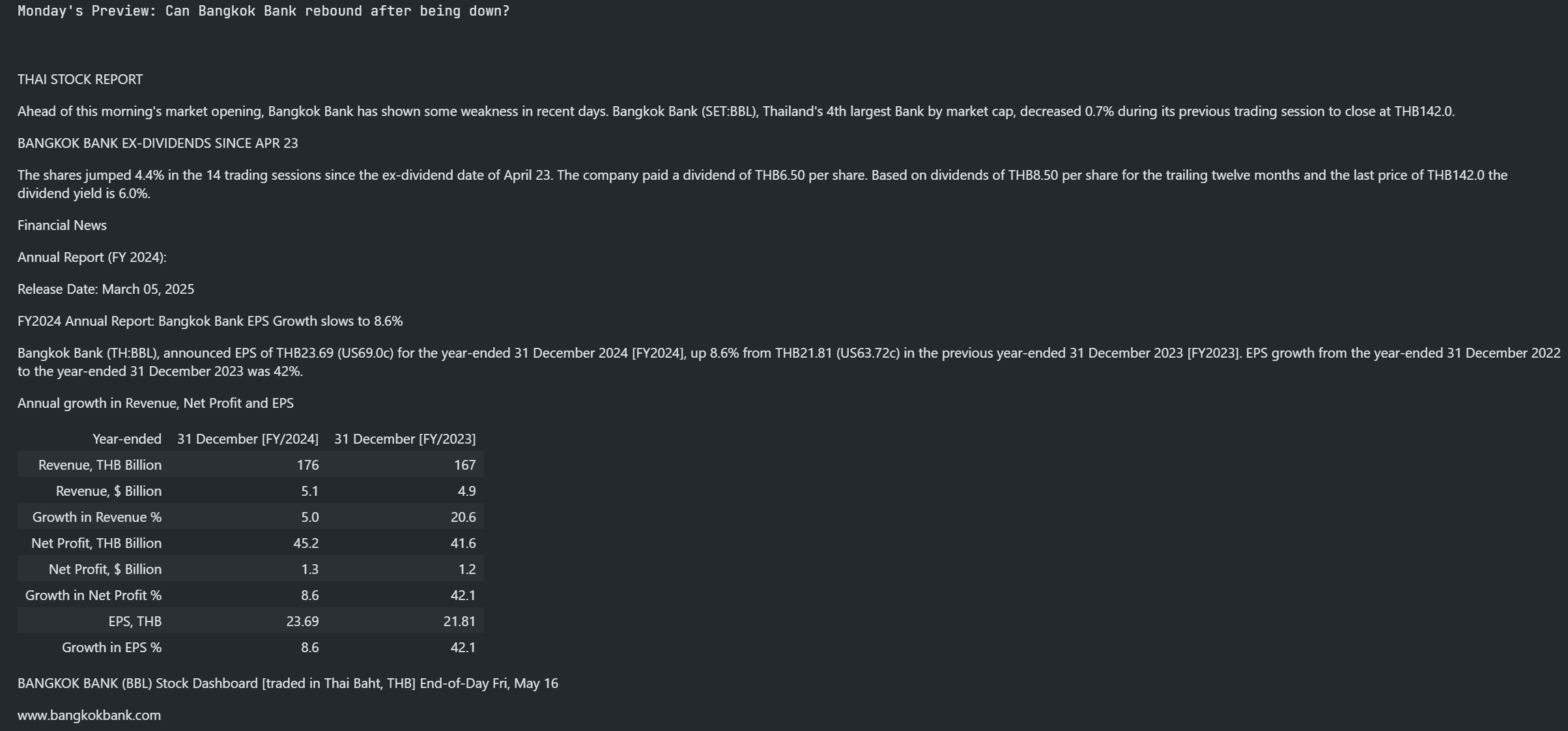
Historical Data
The get_history() function allows you to retrieve pricing history as well as Fundamental & Reference data history via a single function call.
Unlike the previous versions of the library, now you can just input a universe to get all historical fields data.
ld.get_history("LSEG.L")
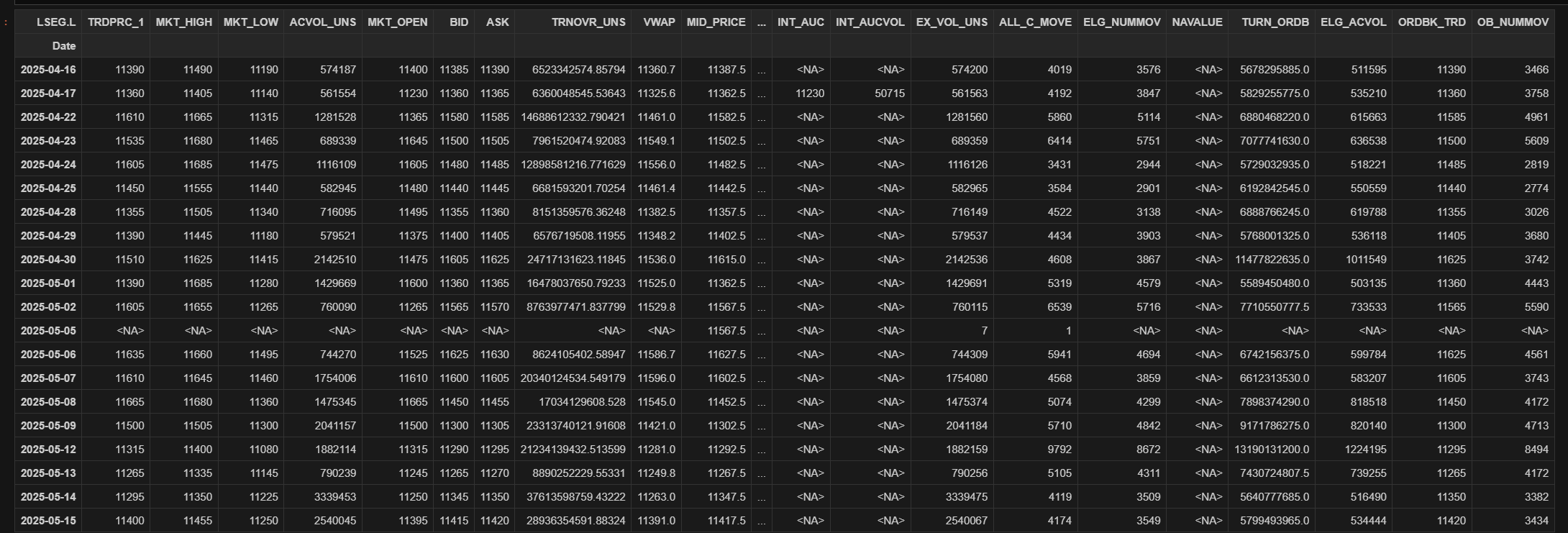
You can request Intraday data (supports 1min, 5min, 10min, 30min and 60min interval) with the following code.
import datetime
ld.get_history(
universe= 'LSEG.L',
start = datetime.timedelta(-1),
end = datetime.timedelta(0),
interval='5min',
adjustments= [
'exchangeCorrection',
'manualCorrection'
]
)
In the above snippet, we are requesting Historical Intraday data for the past 24hrs with 5 minutes interval and using the optional adjustments parameter to apply any exchange and analyst supplied corrections.
The function returns a Dataframe:
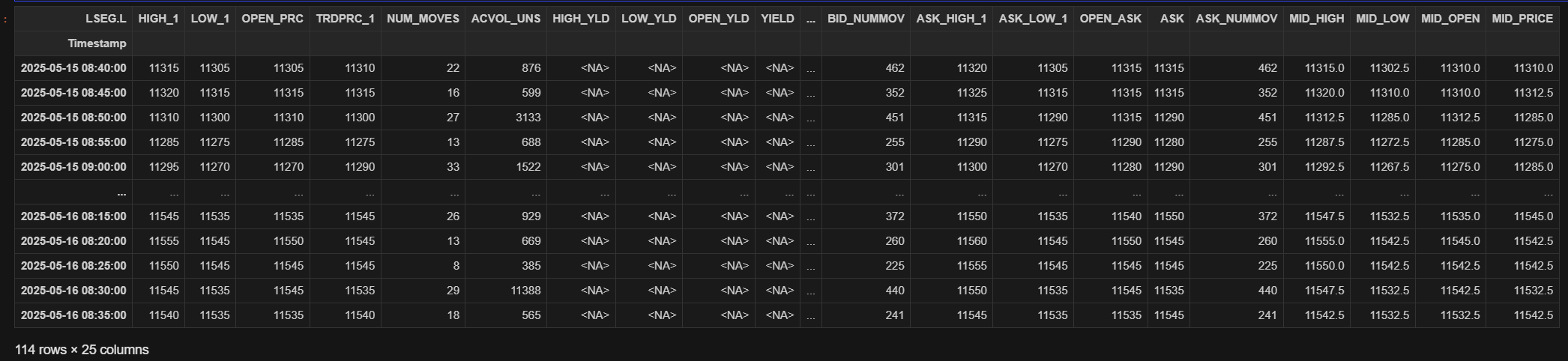
In an example above , the Pricing Events data-set consists of 25 fields of data. We can request a subset of fields if required by specifying a fields list in the request - see the next function for an example of this.
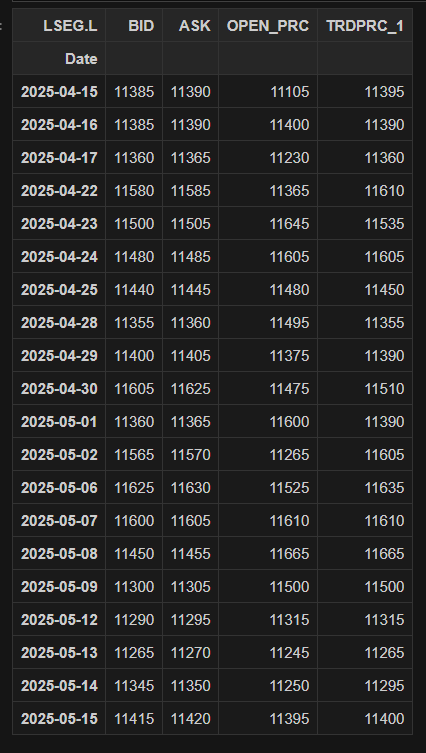
ld.get_history(
universe= 'LSEG.L',
interval='daily',
fields = ['BID','ASK','OPEN_PRC','TRDPRC_1'],
count = 20
)
Here we are requesting daily Interday for the past 20 days and optionally restricting the response to a subset of 4 required fields.
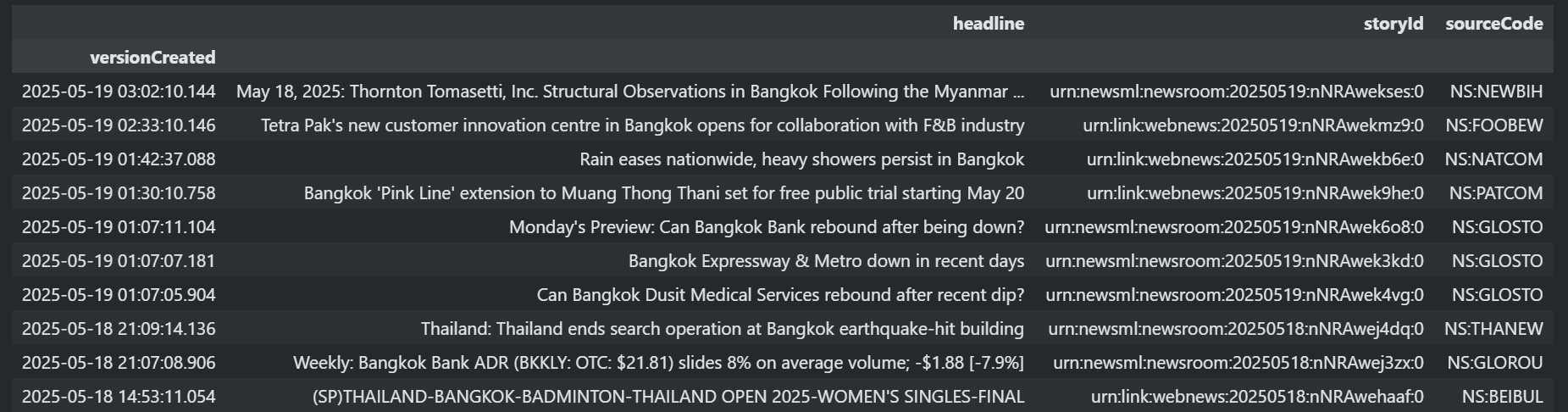
News Headlines and Stories
As well as Historical pricing data, the Access layer can also be used to snapshot News Headlines and the associated News Stories.
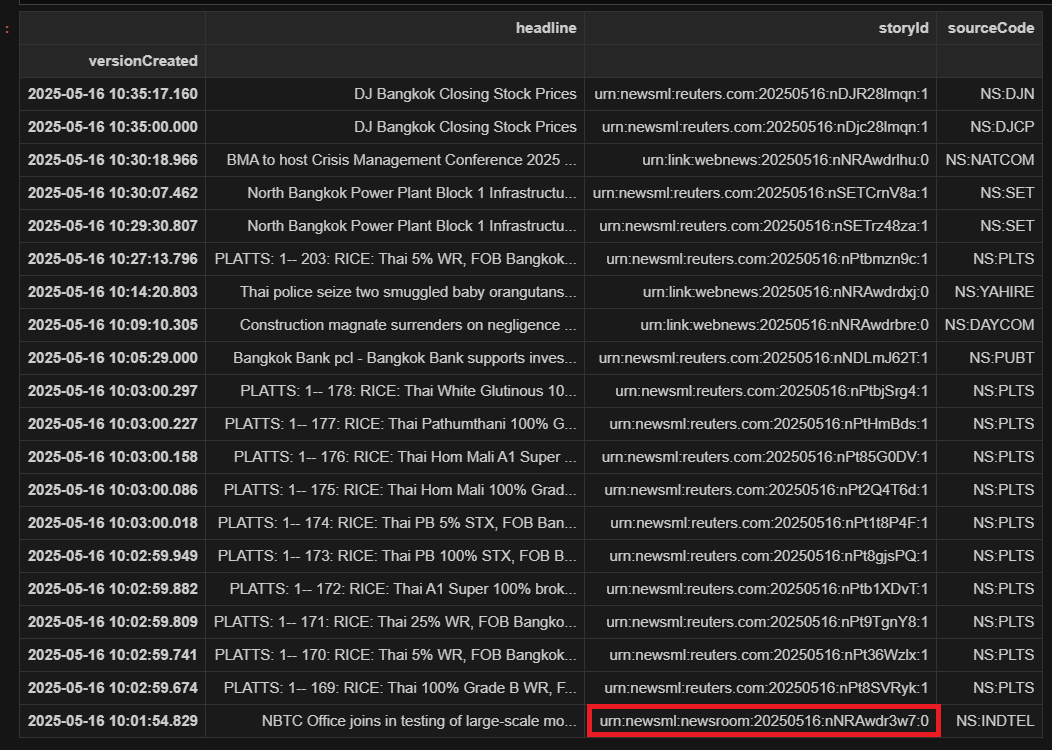
The get_headlines() function allows you to retrieve news headlines via a single function call.
ld.news.get_headlines(query="Bangkok AND Language:LEN", count=20)
And this returns a Dataframe - sample extract below:
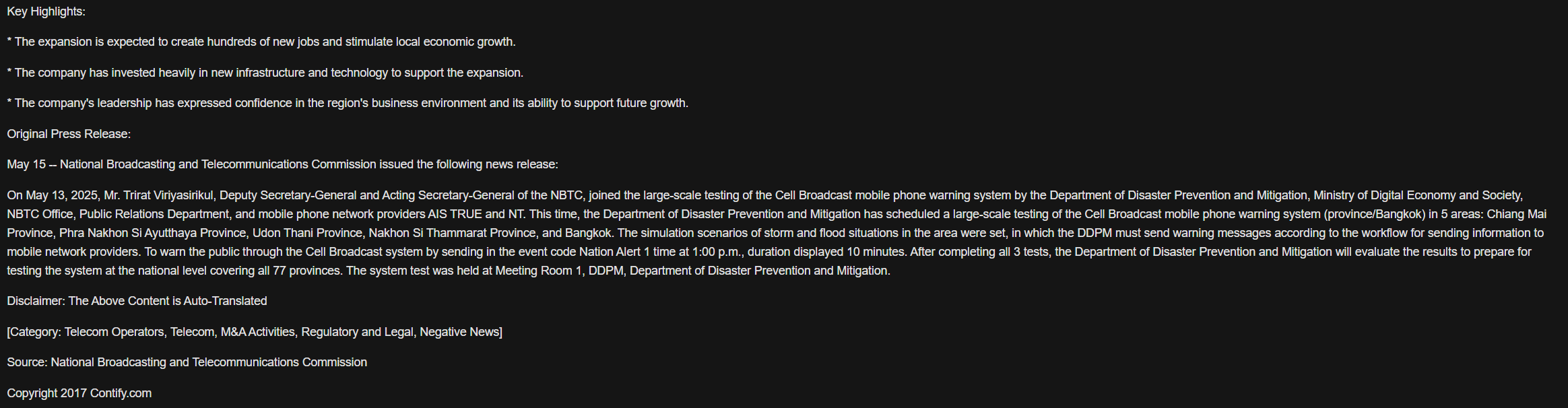
And if we want to read the full story behind any of the headlines, we can request this using the associated storyId using the get_story() function:
from IPython.display import HTML
story = ld.news.get_story('urn:newsml:newsroom:20250516:nNRAwdr3w7:0', format=ld.news.Format.HTML)
HTML(story)
There are more Data Library Access Layer functions to help developers get interested data in a single function call. Please see more details on the following resources:
- The Data Library for Python - Quick Reference Guide (Access layer) article.
- Data Library for Python - Access layer examples.
- Data Library for Python - Access layer tutorial codes.
Content Layer
The Content Layer allows developers to access the same content as above via which are a more flexible manner:
- Richer / fuller response e.g. metadata, sentiment scores - where available.
- Using Asynchronous or Event-Driven operating modes - in addition to Synchronous.
- The layer interfaces are based on logical market data objects such as Level 1 Market Price Data (snapshot/streaming), News, Historical Pricing, Bond Analytics, Environmental & Social Governance (ESG), Search, IPA, and so on.
As earlier, we need to create a session the same way as the Access layer above before we can request data:
# Configuration and Credential defined in **lseg-data.config.json** file
import lseg.data as ld
ld.open_session()
Richer Fuller Content
Depending on the data-set that you are requesting, the Content layer can often provide a richer / fuller response than the access layer.
I am demonstrating with the News Headline interface. The Content Layer application requires a little bit more effort on the part of code than the Access Layer as follows.
import lseg.data as ld
from lseg.data.content import news
response = news.headlines.Definition(
query="Bangkok AND Language:LEN",
date_from=timedelta(days=-2),
date_to=timedelta(days=0),
count=10
).get_data()
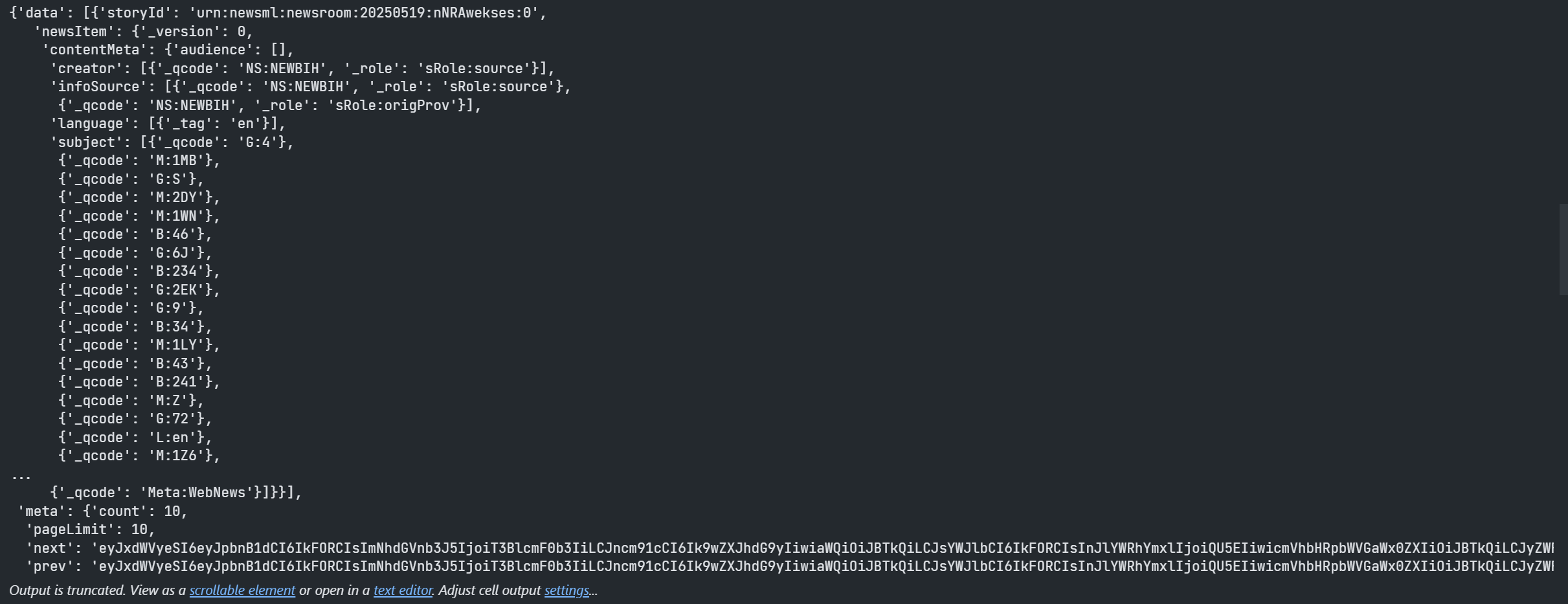
Once an application gets a response object. An application can choose to get the returned data as a JSON message format (aka raw data) via a response.data.raw attribute.
response = news.headlines.Definition(...).get_data() #see above
response.data.raw
This JSON message gives developers all data attributes information that an application may need for their business requirements.
If an application needs data as DataFrame object, the Content Layer provides response.data.df attribute for developers.
response = news.headlines.Definition(...).get_data() #see above
response.data.df
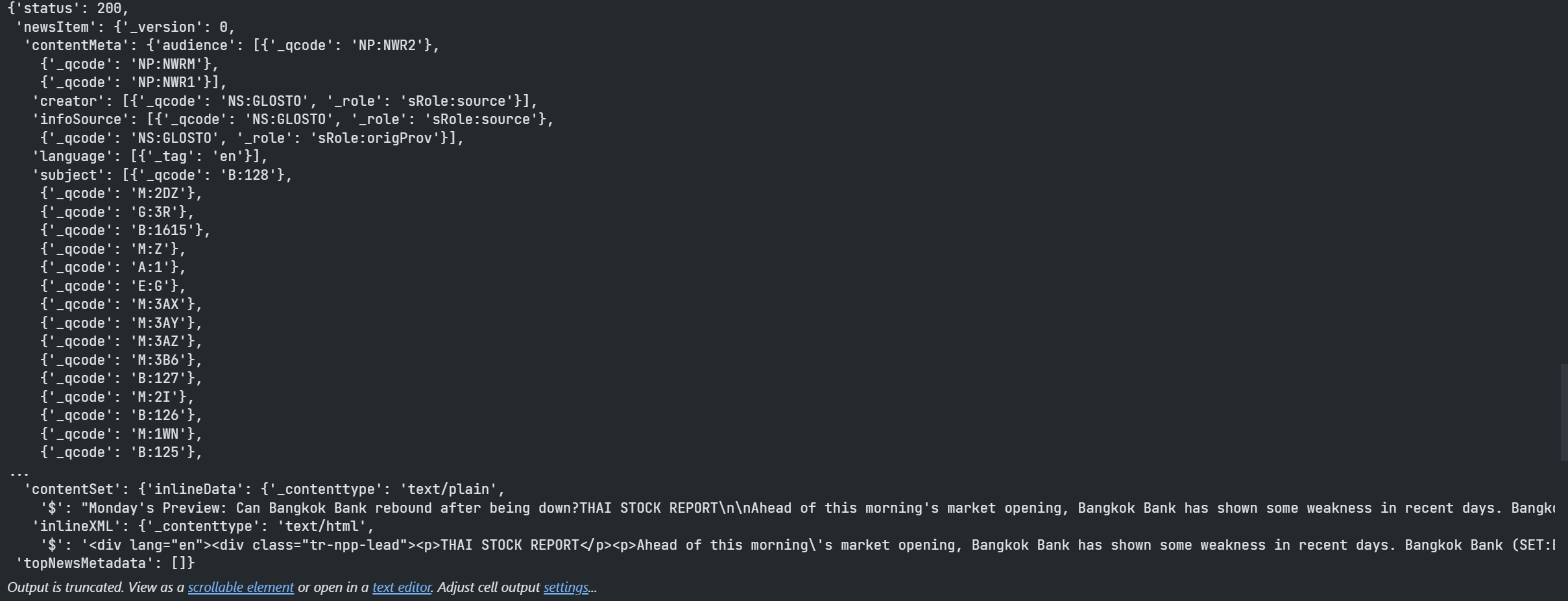
Other example is the NewsStory content; the JSON message response data also give us full News Story payload which includes some metadata related to the story too. This information is not available when we used the Access layer the response consisted of an HTML representation of the actual News Story.
response = news.story.Definition("urn:newsml:newsroom:20250519:nNRAwek6o8:0").get_data()
response.data.raw
Please note that you can still get the HTML data response via the much more richer API interfaces than the Access Layer.
from IPython.display import HTML
response = news.story.Definition("urn:newsml:newsroom:20250519:nNRAwek6o8:0").get_data()
print(response.data.story.title, '\n')
HTML(response.data.story.content.html)
Streaming Market Price Data
The Content layer expands on the Access layer's Snapshot functionality by supporting real-time Streaming requests for Level 1 Market Price data. So, for example if we wanted BID, ASK and a few other fields for a bunch of currency instruments we can use the Content Layer Streaming Events feature.
Using a Pricing stream object with events requires an application to define event handlers that are called by a background execution thread when new events are received for the instruments you requested. There are 4 different types of event handlers you can optionally define depending on the type to events your are interested in.
- Refresh events: Refresh events happen when all fields of one the requested instruments are received. This complete list of fields is sometimes called the 'image' of the instrument.
- Update events: Update events are received when fields of a requested instrument change. Update events only contain the fields and values that changed.
- Status events: Status events are received when the status of one of the requested instruments changes.
- Complete events: A Complete event is received once all the requested instruments received either a Refresh or a Status event.
Python Code example:
import datetime
import lseg.data as ld
from lseg.data.content import pricing
from IPython.display import display
# Define Refresh Event callback
def display_refreshed_fields(fields, instrument_name, pricing_stream):
print(f"{datetime.datetime.now().time()}- Refresh received for {instrument_name}:{fields}")
# Define Update Event callback
def display_updated_fields(fields, instrument_name, pricing_stream):
print(f"{datetime.datetime.now().time()}- Update received for {instrument_name}:{fields}")
# Define Status Event callback
def display_status(status, instrument_name, pricing_stream):
print(f"{datetime.datetime.now().time()}- Status received for {instrument_name}:{status}")
# Define Complete Event callback
def display_complete_snapshot(pricing_stream):
print(f"{datetime.datetime.now().time()}- Pricing stream is complete. Full snapshot:")
display(pricing_stream.get_snapshot())
Then an application can set up the interested RIC codes and fields as a Steam object:
stream = ld.content.pricing.Definition(
['EUR=', 'GBP=', 'JPY=', 'CAD='],
fields=['BID', 'ASK']
).get_stream()
stream.on_refresh(display_refreshed_fields)
stream.on_update(display_updated_fields)
stream.on_status(display_status)
stream.on_complete(display_complete_snapshot)
We can action the request by opening the Streaming Price object via stream.open() function.
stream.open()
Which generates something like the following Market Price events output:
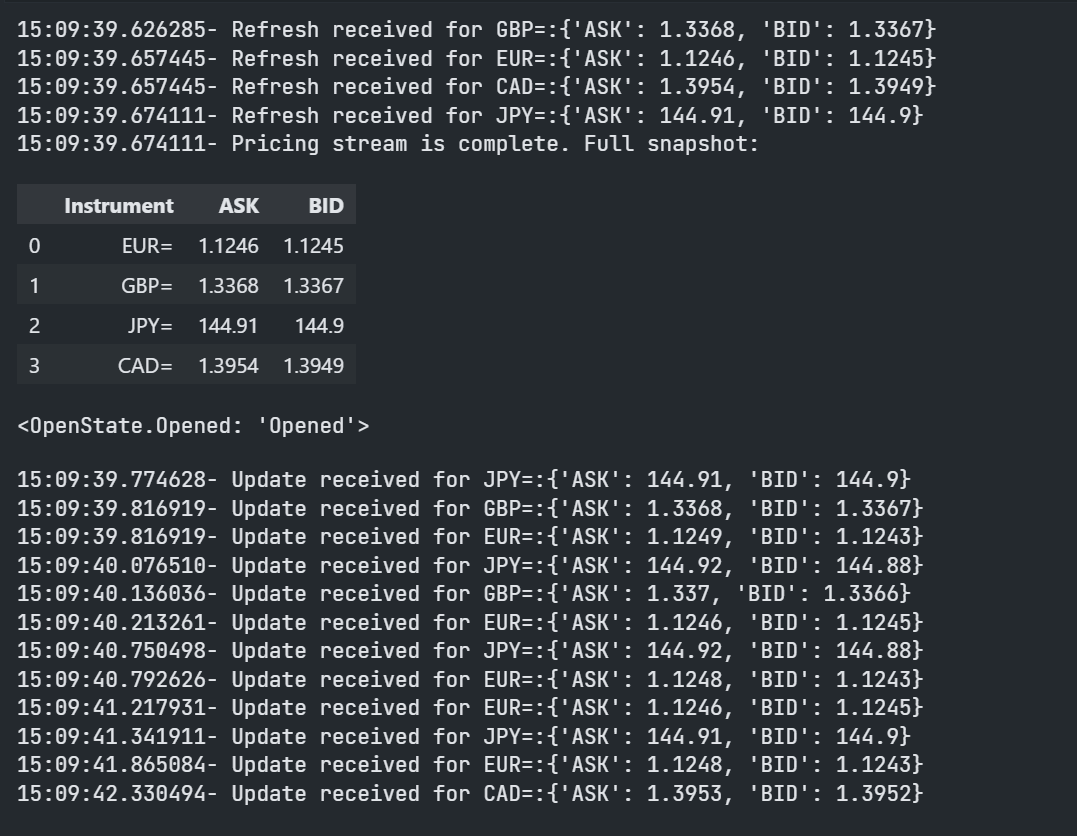
To stop the Streaming Price object (aka unsubscribe all data subscription), an application can call the following function.
stream.close()
Streaming Price Cache
In an example above, we are handling every single tick the server sends out by way of the Display Update callback functions. Sometimes, however, we don't need to handle every update - perhaps we only want to update our GUI every 10 secs or when someone interacts with the GUI.
The Pricing stream object automatically manages a streaming cache available for access at any time. An application can then reach into this cache and pull out real-time snapshots as Pandas DataFrames by just calling a simple access method.
Firstly, an application creates a Streaming Price object the same way as the Streaming Event application.
import lseg.data as ld
from lseg.data.content import pricing
from pandas import DataFrame
from IPython.display import display, clear_output
#
stream = ld.content.pricing.Definition(
universe = ['EUR=', 'GBP=', 'JPY=', 'CAD='],
fields = ['BID', 'ASK']
).get_stream()
Then subscribes all item using this code.
stream.open()
As soon as the open method returns, the stream object is ready to be used. Its internal cache is constantly kept updated with the latest streaming information received from the Platform. All this happens behind the scene, waiting for your application to pull out data from the cache.
When we then want to get the latest values from the cache we take a snapshot:
df = stream.get_snapshot()
display(df)
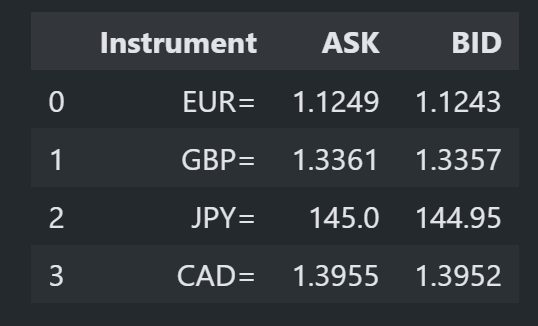
Selective Snapshot
There may be situations where we don't want a snapshot of all the RICs and/or Fields that we defined in our StreamingPrice object. This can also be easily achieved by optionally specifying a subset of RICS and/or Fields in the snapshot call:
df = stream.get_snapshot(
universe = ['EUR=', 'GBP='],
fields = ['BID', 'ASK']
)
display(df)
which returns a subset like:
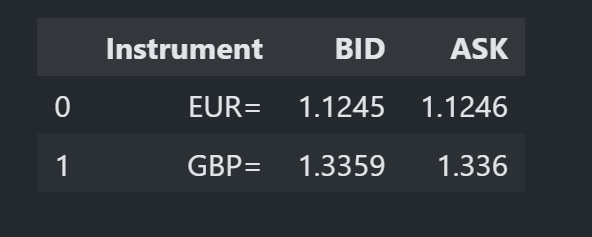
There are much more usages of the Content Layer's objects such as ESG, IPA, Symbology, etc. Please find more details on the following resources:
- LSEG Data Library for Python - Reference Guide
- Data Library for Python - Content layer examples.
- Data Library for Python - Content layer tutorial codes.
The Delivery Layer...
So that concludes my look at the Access and Content layer. The Data Library is the strategic library for consuming data from LSEG platforms (Workspace, Delivery Platform, Real-Time), so we continue to develop the library and hope to offer Access and Content layers to support for other data content.
In the meantime, you can access much of that Data using the Delivery Layer. So, join me again for the 2nd part of this article where we will explore the Delivery layer which give developers much more control of request and response messages.
References
You can find more details regarding the Data Library and Jupyter Notebook from the following resources:
- LSEG Data Library for Python, .NET and TypeScript on the LSEG Developer Community website.
- Data Library for Python - Reference Guide
- The Data Library for Python - Quick Reference Guide (Access layer) article.
- Essential Guide to the Data Libraries - Generations of Python library (EDAPI, RDP, RD, LD) article.
- Data Library for Python Examples on GitHub repository..
- Data Library for .NET Examples on GitHub repository.
- Data Library for TypeScripts Examples on GitHub repository.
- Discover our Data Library (part 2) article.
For any questions related to this article or Data Library, please use the Developers Community Q&A Forum.
Get In Touch
Related Articles
Related APIs
Source Code
Request Free Trial
Call your local sales team
Americas
All countries (toll free): +1 800 427 7570
Brazil: +55 11 47009629
Argentina: +54 11 53546700
Chile: +56 2 24838932
Mexico: +52 55 80005740
Colombia: +57 1 4419404
Europe, Middle East, Africa
Europe: +442045302020
Africa: +27 11 775 3188
Middle East & North Africa: 800035704182
Asia Pacific (Sub-Regional)
Australia & Pacific Islands: +612 8066 2494
China mainland: +86 10 6627 1095
Hong Kong & Macau: +852 3077 5499
India, Bangladesh, Nepal, Maldives & Sri Lanka:
+91 22 6180 7525
Indonesia: +622150960350
Japan: +813 6743 6515
Korea: +822 3478 4303
Malaysia & Brunei: +603 7 724 0502
New Zealand: +64 9913 6203
Philippines: 180 089 094 050 (Globe) or
180 014 410 639 (PLDT)
Singapore and all non-listed ASEAN Countries:
+65 6415 5484
Taiwan: +886 2 7734 4677
Thailand & Laos: +662 844 9576