




Overview
Why do we need to get the Swiss Tax Data attributes?
A Swiss Portfolio Manager is required to make periodic tax returns to the Swiss Federal Tax Authority. In order to calculate the appropriate taxation rates on these tax returns, the portfolio manager needs some key attributes alongside the basic instrument reference data that they already have.
In this article, we're going to retrieve the Swiss Tax Data attributes provided by Refinitiv, for each instrument of a mixed-asset portfolio (bonds, equities, and funds) of 2,000 instruments
• Instrument ID
• Issuer Domicile Text
• Swiss Stamp Duty Flag
• Swiss Stamp Tax Rate
• Taxation Comment
• Taxation Type
We're using Refinitiv Data Library (RD Library) to retrieve the data from these RDP APIs
• Symbology API: To convert the identifiers supplied in the instrument list into PermIDs
• Data Store GraphQL API: To request Swiss Tax Data for the instruments requested
Prerequisite
In this article, the code is running in a Jupyter notebook with the access credentials to Refinitiv Data Platform APIs (RDP API) and Refinitiv Data Python Library (RD Library) is used to authenticate and manage the session. Actually, the RDP API token can be managed using Python code (Authorization - All about tokens) but it's much easier using the library to handle it.
- Access Credentials are required to access RDP API via RD Library. For more detail, please check page Refinitiv Data Library for Python - Access Credentials. In this article, the authentication is being done using a Platform session that allows you to access content directly within the cloud and utilizes the OAuth 2.0 specification to ensure secure communication. While the libraries will shield the user from OAuth token management, the following credentials will be required to access content using the Platform Session:
| User ID | A User ID provided to you - in a Welcome email from Refinitiv |
| Password | The User Password you have set using a link in the above Welcome email |
| App Key | An Application Key used to monitor the application. Users can generate/manage their application ID's here. |
To acquire your Platform credentials, you will need to reach out to your Refinitiv Account Manager.
- Python version 3.9.6
- Required python libraries:
- refinitiv.data==1.0.0b10
- pandas==1.3.5
- logging==0.5.1.2
- asyncio==3.4.3
- json==2.0.9
- datetime==4.3
- copy
- collections
- time
- configparser
- functools
- contextlib
- traceback
- os
- Input files
1) credentials.ini credentials file that contains the access credentials
[RDP]
username = #RDP_USER_ID#
password = #RDP_PASSWORD#
clientId = #RDP_APP_KEY#
uuid =
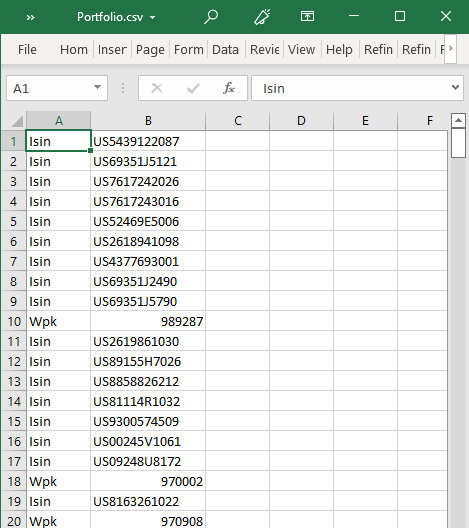
2) Portfolio.csv CSV file containing the instrument types (Isin, Wpk, ValorenNumber, Sedol) and instrument codes
The example of Portfolio.csv file can be found in this GitHub Repository.
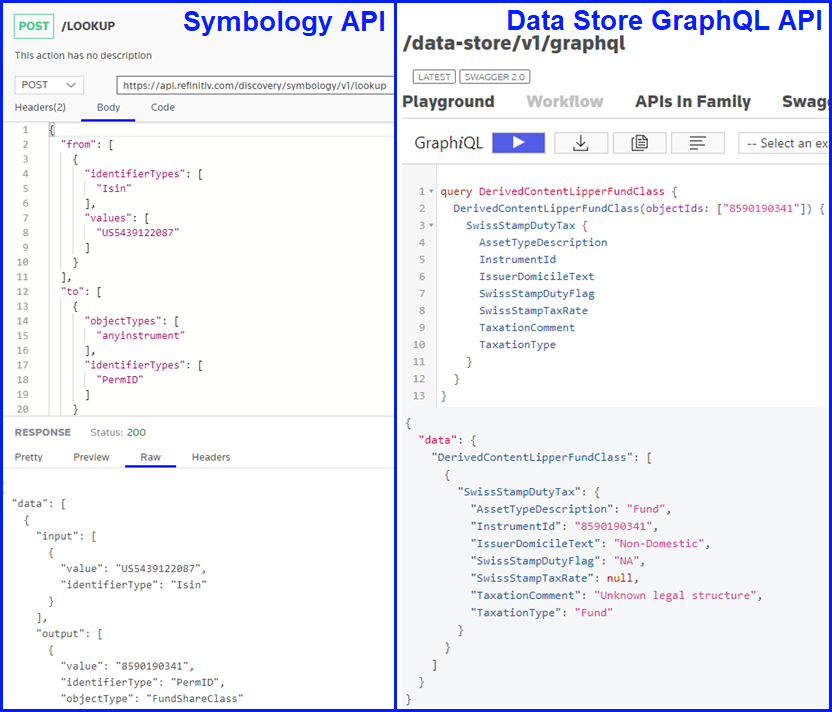
To find how to form an API call, search for an endpoint in RDP API Playground then check Playground tab and Reference tab
These 2 endpoints of RDP APIs are being used to retrieve the data
1) Symbology API (/discovery/symbology/v1/lookup) to retrieve PermIDs of input instruments (in various instrument types) or check Symbology User Guide
2) With output of the Symbology API, calling Data Store GraphQL API (/data-store/v1/graphql) to get Swiss Tax Data.
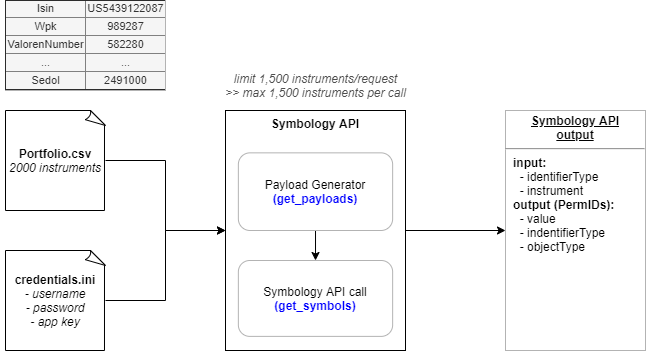
5 steps to retrieve the data
Step 1) Preparation
Import necessary Python libraries mentioned to manage the request/response and output dataframe and create the function read_input_file to import an input CSV file (Portfolio.csv) and convert it to Python dictionary with instrument type as a key and code as a value.
# ==============================================
def read_input_file(input_file_name):
# ==============================================
"""Import input file (Portfolio.csv) and convert it to Python dictionary with instrument type as a key and code as a value"""
port = pd.read_csv(f".\\{input_file_name}", header=None)
port.rename(columns={0: "type", 1: "id"}, inplace=True)
port = port.drop_duplicates()
# map instrument type
id_dict = defaultdict(list)
for row in port.itertuples():
id_dict[row[1]].append(row[2])
return id_dict
Step 2) Convert Symbology
Generate API Payload with get_payloads function, which dividing the instruments into batches with 1,500 instruments per each batch due to Symbology API input limit (maximum 1,500 instruments per call). Then with these payloads, call Symbology API to get instruments' PermID with get_symbols function
# =============================================
def get_payloads(id_dict_ori, limit):
# ==============================================
"""Generate API Payload
dividing the instruments into batches with 1,500 instruments per each batch
due to Symbology API input limit (maximum 1,500 instruments per call)"""
id_dict = deepcopy(id_dict_ori)
inputs = []
payloads = []
count = 0
initial = 0
while any(len(value) for value in id_dict.values()):
for key, value in id_dict.items():
count += len(value)
if count > limit:
ids = value[initial : len(value) + limit - count]
id_dict[key] = value[len(value) + limit - count :]
initial += limit
count = 0
input_dict = {"identifierTypes": [key], "values": ids}
inputs.append(input_dict)
payloads.append(inputs)
inputs = []
break
else:
input_dict = {"identifierTypes": [key], "values": value}
inputs.append(input_dict)
id_dict[key] = value[len(value) :]
payloads.append(inputs)
return payloads
# ==============================================
def get_symbols(payloads):
# ==============================================
symbols = []
for payload in payloads:
request_definition = rd.delivery.endpoint_request.Definition(
method = rd.delivery.endpoint_request.RequestMethod.POST,
url = 'https://api.refinitiv.com/discovery/symbology/v1/lookup',
body_parameters = { # Specify body parameters
"from": payload,
"to": [
{
"identifierTypes": [
"PermID"
]
}
],
"type": "auto"
}
)
response = request_definition.get_data()
symbols.extend(response.data.raw["data"])
return symbols
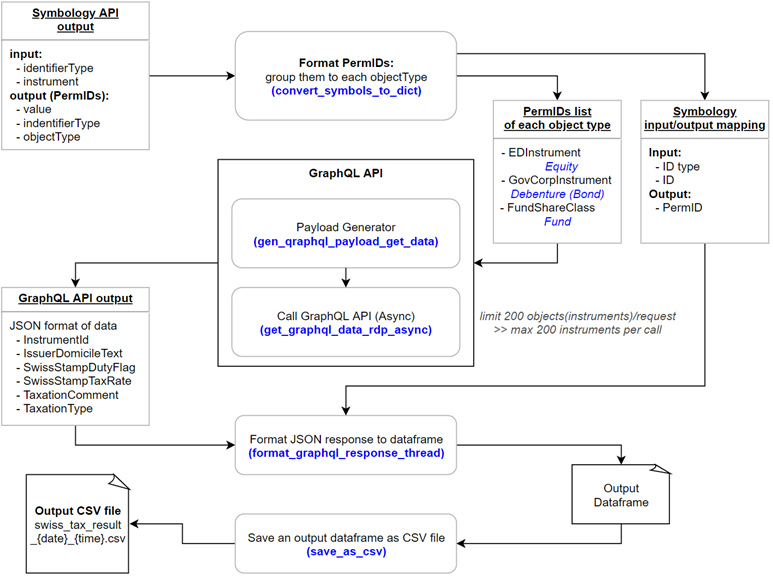
Step 3) Data Store GraphQL API - retrieve Swiss Tax Data
These functions are being used
2.1 ) convert_symbols_to_dict: convert the Symbology API output to Python dictionary data type and create a dataframe of its input/output
2.2) gen_qraphql_payload_get_data: generate GraphQL payload for calling the endpoint
2.2.1) get_graphql_data_rdp_async: call the endpoint as a batch with 200 instruments per batch due to the Data Store GraphQL API input limit (maximum 200 instruments per call)
2.3) format_graphql_response_thread: convert the output to a dataframe and merge it with the dataframe of Symbology API's input/output
2.4) save_as_csv: save an output dataframe as a CSV file named swiss_tax_result_{current_time}.csv in the folder swiss_tax_result
# ==============================================
def convert_symbols_to_dict(all_symbols):
# ==============================================
"""Convert the Symbology API output to Python dictionary data type and create a dataframe of its input/output"""
# response symbology
symbol = []
for index, value in enumerate(all_symbols):
if value["output"]:
symbol.append(value)
response_df = pd.DataFrame()
for index, data in enumerate(symbol):
input_list = []
output_list = []
#data["input"][0]["instrument"] = data["input"][0].pop("value")
if len(data["output"]) > 1:
for row in range(len(data["output"])):
input = pd.DataFrame.from_dict(data["input"][0], orient="index").T
input_list.append(input)
raw_input_df = pd.concat(input_list, ignore_index=True, sort=False)
else:
raw_input_df = pd.DataFrame.from_dict(data["input"][0], orient="index").T
if len(data["output"]) > 1:
for row in range(len(data["output"])):
output = pd.DataFrame.from_dict(data["output"][row], orient="index").T
output_list.append(output)
raw_output_df = pd.concat(output_list, ignore_index=True, sort=False)
else:
raw_output_df = pd.DataFrame.from_dict(data["output"][0], orient="index").T
raw_input_df.rename(columns={"value": "Input ID"}, inplace=True)
raw_output_df.rename(columns={"value": "PermID"}, inplace=True)
raw_df = pd.concat([raw_input_df, raw_output_df], axis=1)
response_df = response_df.append(raw_df, ignore_index=True, sort=False)
# logging.info(f'response dataframe \n{response_df}\n')
object_id_dict = defaultdict(list)
for row in response_df.itertuples():
object_id_dict[row[5]].append(row[3])
column_names = response_df.columns.values
column_names[1] = "Input ID type"
response_df.columns = column_names
io_mapping = response_df.loc[:,["Input ID type", "Input ID", "PermID"]]
return object_id_dict, io_mapping
def chunks(lst, n):
for i in range(0, len(lst), n):
yield lst[i : i + n]
gql_limit = 200
# ==============================================
def gen_qraphql_payload_get_data(object_id_dict):
# ==============================================
"""Generate GraphQL payload for calling the endpoint"""
gql_output = {}
gql_class_mapping = {
"FundShareClass": "DerivedContentLipperFundClass",
"EDInstrument": "DerivedContentEDFInstrument",
"GovCorpInstrument": "DerivedContentGovCorpBonds",
}
cnt = 0
for query_type, class_name in gql_class_mapping.items():
several_tasks = asyncio.gather(
*[
get_graphql_data_rdp_async(
class_name, json.dumps(chunk_instruments), cnt
)
for chunk_instruments in chunks(object_id_dict[query_type], gql_limit)
]
)
loop = asyncio.get_event_loop()
gql_output[class_name] = loop.run_until_complete(several_tasks)
cnt += 1
return gql_output
# ==============================================
async def get_graphql_data_rdp_async(class_name, list_instrument, cnt):
# ==============================================
"""Call the endpoint as a batch with 200 instruments per each batch due to the Data Store GraphQL API input limit (maximum 200 instruments per call)"""
print(f"[RDP-ASYNC] calling graphql for the {class_name} data {cnt}")
#response = await endpoint.send_request_async(
request_definition = rd.delivery.endpoint_request.Definition(
method = rd.delivery.endpoint_request.RequestMethod.POST,
url = 'https://api.refinitiv.com/data-store/v1/graphql',
body_parameters = {
"query": "{"
+ class_name
+ "(objectIds: "
+ list_instrument
+ "){SwissStampDutyTax {AssetTypeDescription InstrumentId IssuerDomicileText SwissStampDutyFlag SwissStampTaxRate TaxationComment TaxationType}}}",
"variable": {},
}
)
response = await request_definition.get_data_async()
return response.data.raw, class_name
# ==============================================
def format_graphql_response_thread(gql_output,io_mapping):
# ==============================================
"""Convert an output to a dataframe and merge it with the dataframe of Symbology API's input/output"""
raw_output_df = pd.DataFrame()
response_list = []
for gql_class in gql_output:
for response, class_name in gql_output[gql_class]:
raw_response = response["data"]
for raw in raw_response[class_name]:
output = pd.DataFrame.from_dict(raw, orient="index")
output["class_name"] = class_name
response_list.append(output)
raw_output_df = pd.concat(response_list, ignore_index=True, sort=False)
raw_output_df = io_mapping.merge(raw_output_df, left_on="PermID", right_on="InstrumentId", how="inner")
raw_output_df = raw_output_df.drop(columns=["InstrumentId"])
raw_output_df = raw_output_df.drop_duplicates()
return raw_output_df
# ==============================================
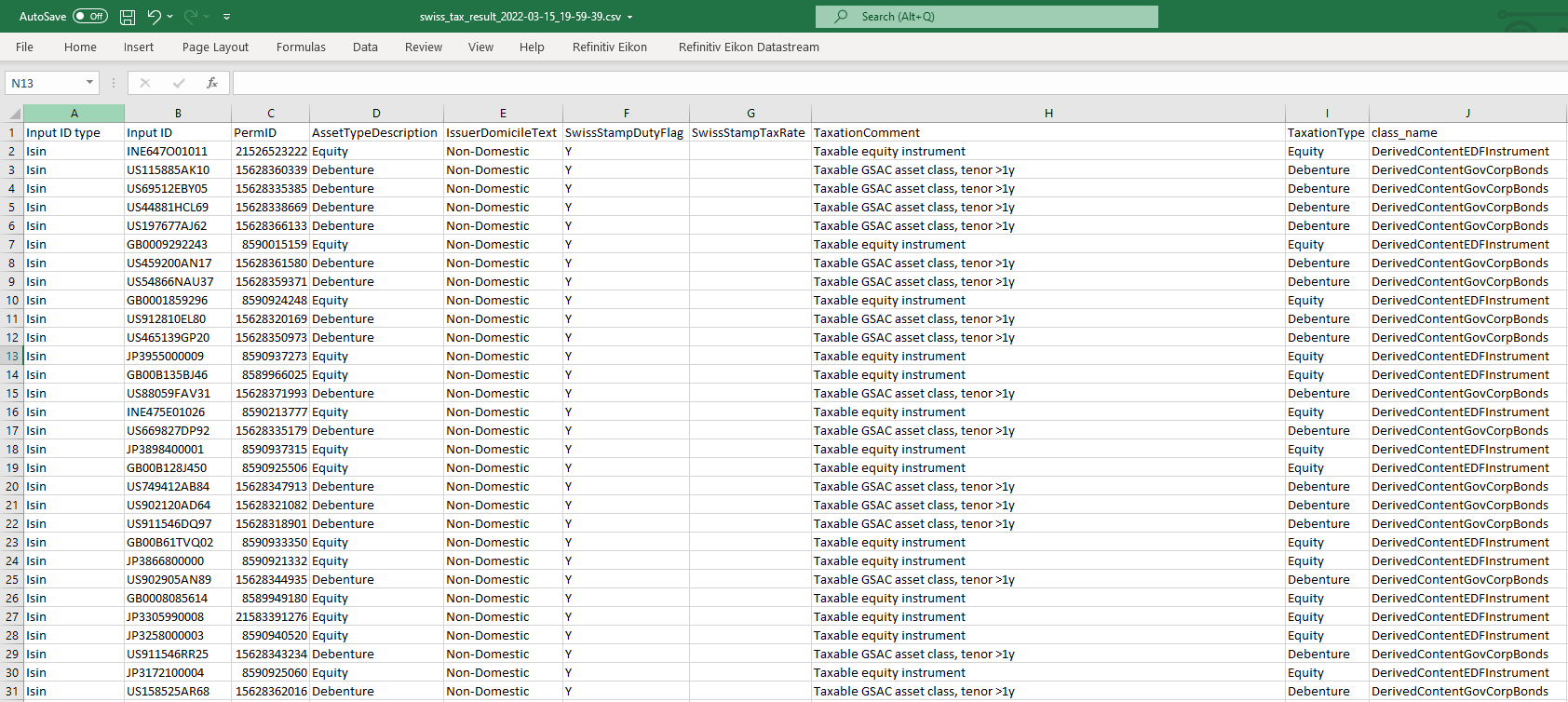
def save_as_csv(df, folder_name, file_name):
# ==============================================
"""Save an output dataframe as a CSV file named swiss_tax_result_{current_time}.csv in the folder swiss_tax_result"""
print(f"Save output dataframe as CSV file named: {file_name}")
if not os.path.exists(folder_name):
os.makedirs(folder_name)
df.to_csv(os.path.join(folder_name,file_name), index=False)
Step 4) Run the defined functions
Read RDP credentials from file credentials.ini and open the platform session with the RD library. Then read the input CSV file and convert it to the dataframe and use it to generate the payload for getting PermID from the Symbology API call. Next, from the PermID list, generate the payload and call GraphQL API to retrieve Swiss tax data and format the response to the output dataframe before exporting it as a CSV file.
# using now() to get current time for output file name
current_time = datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
input_file_name = 'Portfolio.csv'
swiss_tax_folder_name = "swiss_tax_result"
swiss_tax_file_name = f"swiss_tax_result_{current_time}.csv"
try:
# setting up
rd.open_session()
start = time.time()
# read input file
id_dict = read_input_file(input_file_name)
# request symbology
payloads = get_payloads(id_dict, limit=1500)
all_symbols = get_symbols(payloads)
# call graphql endpoint
object_id_dict, io_mapping = convert_symbols_to_dict(all_symbols)
gql_output = gen_qraphql_payload_get_data(object_id_dict)
swiss_tax_df = format_graphql_response_thread(gql_output, io_mapping)
# show runtime
end = time.time()
print(f"Runtime of the app is {end - start}")
rd.close_session()
# save to csv file
save_as_csv(swiss_tax_df, swiss_tax_folder_name, swiss_tax_file_name)
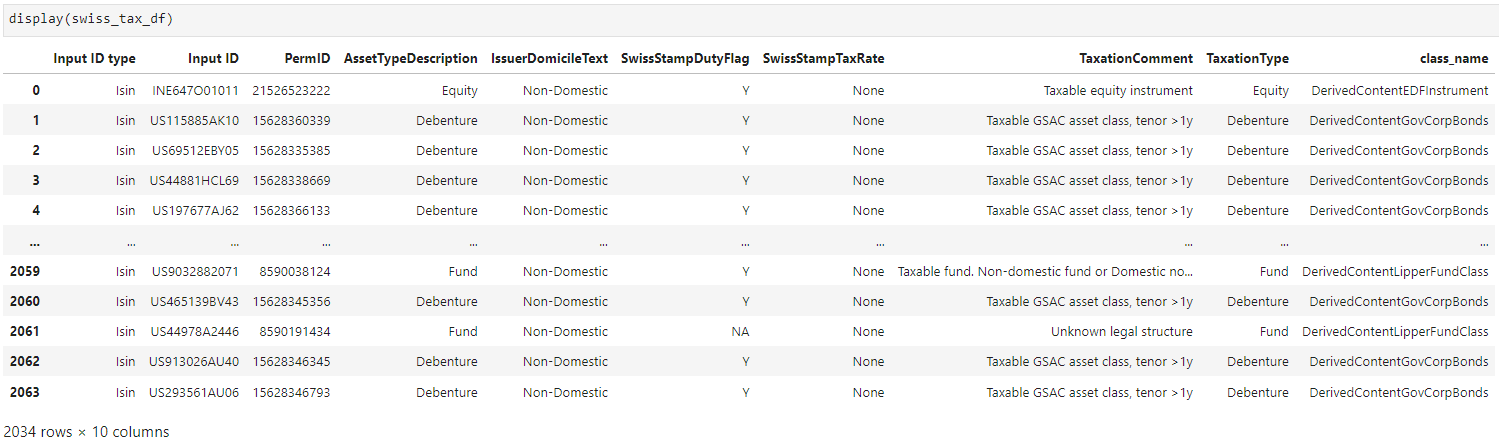
display(swiss_tax_df)
except Exception as e:
session.close()
logging.error(f'App failed with error message : {e}')
print(traceback.print_exc())
Here's the output dataframe of Swiss Tax Data
Output CSV files are saved with date and timestamp of the run in swiss_tax_result folder
Conclusion
This article demonstrates that we can retrieve Swiss Tax data from the input instruments provided in a CSV file using RDP API via RD Library and this data can be used to make periodic tax returns to the Swiss Federal Tax Authority.
The full code can be found in this GitHub Repository.
For more details regarding the RDP APIs and RD Library, please refer to the reference section below.
- Register or Log in to applaud this article
- Let the author know how much this article helped you