
Requesting ESG Bulk PIT Content Set- Python

Introduction
ESG stands for Environmental, Social and (Corporate) Governance data.
Refinitiv Data Platform (RDP) provides simple web based API access to a broad range of content, including ESG content and ESG content in bulk.
PIT content is newly made available on RDP, and this article will review the recommended approach to requesting complete ESG Bulk PIT content set and keeping it up-to-date.
For information on how to get started working with RDP, including the generation of CLIENT_ID, which is the same as AppKey, please refer to Quickstart guide for Refinitiv Data Platform included in References
Programmatic Approach
Every Monday 9am UTC, both full and delta ESG Bulk PIT filesets will be published.
There are currently 100 constituent initialization or full files, and as we add years, these will increase in 5’s.
At present, there are 5 delta or change files.
There are two ways to stay up-to date:
- Every week, we initialize the local ESG Bulk PIT store or database by requesting the full set of initialization ESG Bulk PIT files (.F)
- First week, we Initialize the local store by requesting the full set of initialization ESG Bulk PIT files (.F). Consequently, we request the delta ESG Bulk PIT files (.I) that will contain all the changes that were applied to the database since the last week's ESG Bulk PIT .F. files
Therefore, at any beginning of the week, depending on the approach that was selected, we need to request either full set of initialization files, or all the delta/change files, and we never require to request both types of files.
Requirements and Setup to Access RDP ESG Bulk
To interact with RDP platform we require valid RDP credentials and setup:
- Import required libraries and define RDP endpoint paths and constants.
- Load valid RDP credentials that are permissioned for RDP ESG Bulk access.
- Authenticate with RDP using credentials to obtain a valid token
These steps are included in the companion code examples hosted on GitHub (see References section) and are described in detail in many RDP articles, for example https://developers.refinitiv.com/en/article-catalog/article/exploring-news-metadata-refinitiv-data-platform-and-python, so we omit what would be a redundant detailed discussion of these steps here as well, and focus solely on requesting RDP ESG Bulk PIT.
Request Available ESG Bulk PIT File Sets per Package ID
We are going to define bucket to use as a variable, at this time the bucket in use is
RDP_ESG_PIT_BUCKET = 'bulk-esg'
PackageID assigned to PIT content set should be known prior, and at this time it's '4173-aec7-8a0b0ac9-96f9-48e83ddbd2ad'
We are going to define a helper function accepting packageID as parameter, that populates this infromation into attributes of the request:
jsonFullResp = requestFileSets(accessToken, False, '','&packageId='+packageIdPIT);
The helper function will work with a packageID, valid at the time of the request and communicated prior to it.
packageIdPIT = '4173-aec7-8a0b0ac9-96f9-48e83ddbd2ad'
FILESET_ENDPOINT = RDP_BASE_URL+'/file-store'+RDP_ESG_BULK_VERSION + '/file-sets?bucket='+ RDP_ESG_PIT_BUCKET
def requestFileSets(token, withNext, skipToken, attributes):
global FILESET_ENDPOINT
print("Obtaining FileSets in ESG Bucket...")
FILESET_ENDPOINT = RDP_BASE_URL+'/file-store'+RDP_ESG_BULK_VERSION + '/file-sets?bucket='+ RDP_ESG_PIT_BUCKET
querystring = {}
payload = ""
jsonfull = ""
jsonpartial = ""
headers = {
'Content-Type': "application/json",
'Authorization': "Bearer " + token,
'cache-control': "no-cache"
}
if attributes:
FILESET_ENDPOINT = FILESET_ENDPOINT + attributes
if withNext:
FILESET_ENDPOINT = FILESET_ENDPOINT + '&skipToken=' +skipToken
print('GET '+FILESET_ENDPOINT )
response = requests.request("GET", FILESET_ENDPOINT, data=payload, headers=headers, params=querystring)
if response.status_code != 200:
if response.status_code == 401: # error when token expired
accessToken = getToken(); # token refresh on token expired
headers['Authorization'] = "Bearer " + accessToken
response = requests.request("GET", FILESET_ENDPOINT, data=payload, headers=headers, params=querystring)
print('Raw response=');
print(response);
if response.status_code == 200:
jsonFullResp = json.loads(response.text)
return jsonFullResp;
else:
return '';
jsonFullResp = requestFileSets(accessToken, False, '','&packageId='+packageIdPIT);
print('Parsed json response=');
print(json.dumps(jsonFullResp, indent=2));
print('Same response, tabular view');
dfPIT = pd.json_normalize(jsonFullResp['value'])
dfPIT
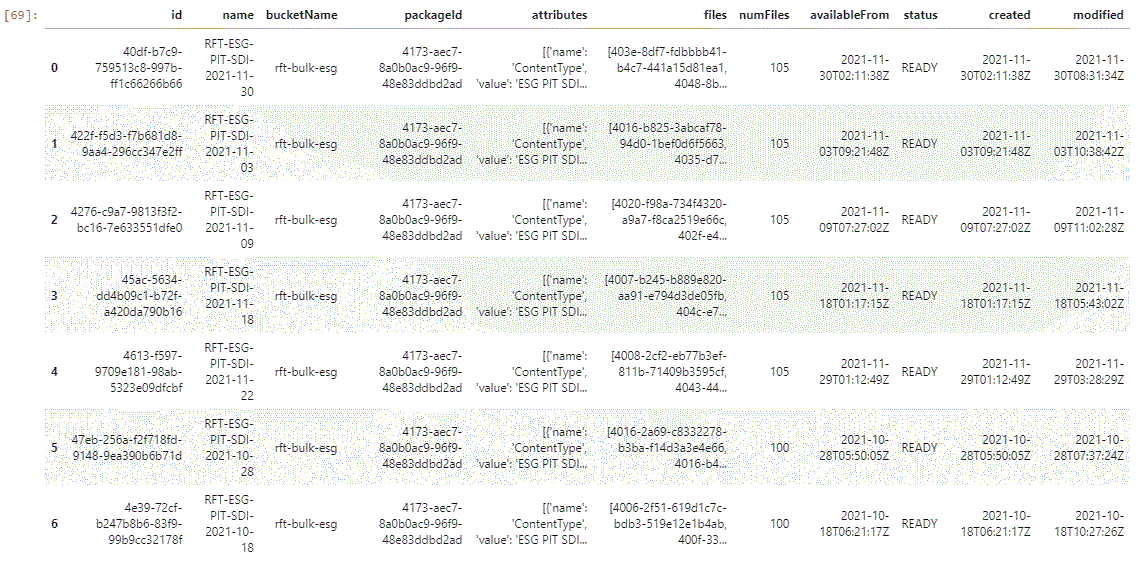
dfPITlast = dfPIT[dfPIT.created == dfPIT.created.max()]
FILESET_ID = dfPITlast["id"].iloc[0]
print('FILESET_ID selected is: ' + FILESET_ID)
and next we are ready to
Request File IDs per selected Fileset ID
We are going to define a helper function:
FILES_ENDPOINT_START = RDP_BASE_URL+'/file-store'+RDP_ESG_BULK_VERSION + '/files?filesetId='
def requestFileDetails(token, fileSetId, attributes, withNext, skipToken):
print("Obtaining File details for FileSet= "+ fileSetId + " ...")
print("(If result is Response=400, make sure that fileSetId is set with a valid value...)")
if withNext:
FILES_ENDPOINT = RDP_BASE_URL + skipToken
else:
FILES_ENDPOINT = FILES_ENDPOINT_START + fileSetId
if attributes:
FILES_ENDPOINT = FILES_ENDPOINT + attributes
querystring = {}
payload = ""
jsonfull = ""
jsonpartial = ""
headers = {
'Content-Type': "application/json",
'Authorization': "Bearer " + token,
'cache-control': "no-cache"
}
response = requests.request("GET", FILES_ENDPOINT, data=payload, headers=headers, params=querystring)
if response.status_code != 200:
if response.status_code == 401: # error when token expired
accessToken = getToken(); # token refresh on token expired
headers['Authorization'] = "Bearer " + accessToken
response = requests.request("GET", FILES_ENDPOINT, data=payload, headers=headers, params=querystring)
print('Raw response=');
print(response);
if response.status_code == 200:
jsonFullResp = json.loads(response.text)
return jsonFullResp;
else:
return '';
We will call the helper function with pageSize of 100 (max) to obtain the first 100 available results as well as skipToken or nextLink, to obtain the remaining available results.
jsonFullResp = requestFileDetails(accessToken, FILESET_ID, '&pageSize=100', False, '');
print('Parsed json response=');
print(json.dumps(jsonFullResp, indent=2));
dfPart1 = pd.json_normalize(jsonFullResp['value'])
dfPart1
skipToken = jsonFullResp['@nextLink']
skipToken
jsonFullRespRemainder = requestFileDetails(accessToken, FILESET_ID, '&pageSize=100', True, skipToken);
print('Parsed json response=');
print(json.dumps(jsonFullRespRemainder, indent=2));
dfPart2 = pd.json_normalize(jsonFullRespRemainder['value'])
dfPart2
#Put the two results together
dfAll = dfPart1.append(dfPart2)
dfAll
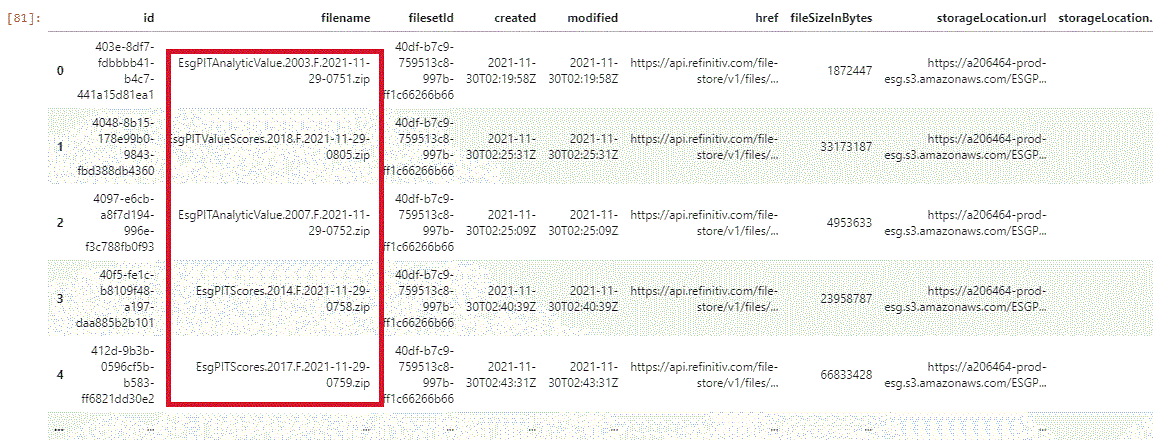
dfFull = dfAll.loc[dfAll['filename'].str.contains('\.F\.')]
dfFull
note how initialization or full files always contain '.F.' in the file name:
Identify The Latest Delta Files
Select .I files
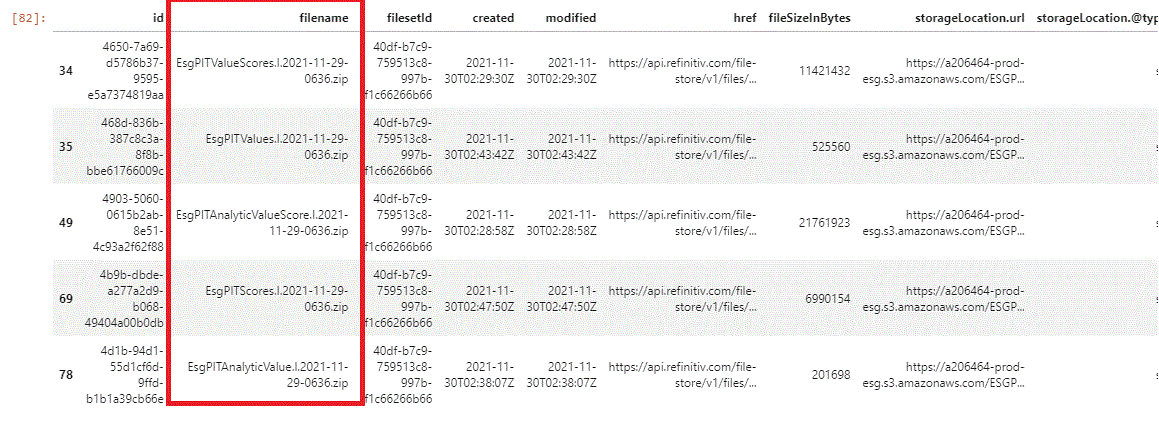
dfDelta = dfAll.loc[dfAll['filename'].str.contains('\.I\.')]
dfDelta
note how delta/Incremental files always contain '.I.' in the file name:
we are going to define a helper function to
Download File via File Id with Redirect
import shutil
FILES_STREAM_ENDPOINT_START = RDP_BASE_URL+'/file-store'+RDP_ESG_BULK_VERSION + '/files/'
# use valid values, obtained from the previous step
exampleFileId = '4edd-99af-da829f42-8ddd-07fabfcddca9'
exampleFileName = 'RFT-ESG-Sources-Full-Init-2021-01-17-part07.jsonl.gz'
def requestFileDownload(token, fileId, fileName):
FILES_STREAM_ENDPOINT = FILES_STREAM_ENDPOINT_START + fileId+ '/stream'
print("Obtaining File ... " + FILES_STREAM_ENDPOINT)
chunk_size = 1000
headers = {
'Authorization': 'Bearer ' + token,
'cache-control': "no-cache",
'Accept': '*/*'
}
response = requests.request("GET", FILES_STREAM_ENDPOINT, headers=headers, stream=True, allow_redirects=True)
if response.status_code != 200:
if response.status_code == 401: # error when token expired
accessToken = getToken(); # token refresh on token expired
headers['Authorization'] = "Bearer " + accessToken
response = requests.request("GET",FILES_STREAM_ENDPOINT, headers=headers, stream=True, allow_redirects=True)
print('Response code=' + str(response.status_code));
if response.status_code == 200:
print('Processing...')
with open(fileName, 'wb') as fd:
shutil.copyfileobj(response.raw, fd)
print('Look for gzipped file named: '+ fileName + ' in current directory')
response.connection.close()
return;
we are going to call this function repeatedly to
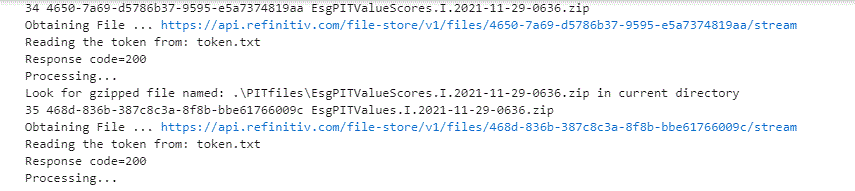
Download the Latest PIT Delta Files
for index, row in dfDelta.iterrows():
print (index,row["id"], row["filename"])
requestFileDownload(accessToken, row["id"],'.\\PITfiles\\'+row["filename"]);
and to call this function repeatedly to
Download the Latest PIT Full Files
for index, row in dfFull.iterrows():
print (index,row["id"], row["filename"])
requestFileDownload(accessToken, row["id"],'.\\PITfiles\\'+row["filename"]);
Downloading ESG Bulk Files Without Redirect
The code to request ESG Bulk files without redirect is included at the bottom of the companion example on GitHub:
- Request File Location (Step 1 of 2)
- Download File From File Location (Step 2 of 2)
References
Thanks to our subject matter expert, product manager Anita Varma, for sharing her knowledge and insight.
Example code on GitHub: Refinitiv-API-Samples/Example.RDPAPI.Python.ESGBulkPIT
RDP API are on developers portal: Refinitiv Data Platform APIs
RDP Quickstart guide: Quickstart guide for Refinitiv Data Platform
RDP ESG Bulk PIT User Guide on developers portal: RDP ESG Bulk PIT User Guide