
Author:

The LSEG Tick History REST API offers programmatic access to LSEG content in a more flexible way than the Web GUI and FTP-based data access solutions. Users can use the API with the on-demand extraction to extract data from the LSEG Tick History server. The API supports the asynchronous mechanism which is designed to cope with large and/or long-running requests. Each asynchronous request starts a job, and each job has a unique id. After submitting an extraction request, this job id can be retrieved from the monitor URL and the Notes file.
The job id in the monitor URL is in the ExtractionId property, which might look something like this:
https://selectapi.datascope.refinitiv.com/RestApi/v1/Extractions/ExtractRawResult(ExtractionId='0x084d16104a586fd1')
The job id in the Notes file looks something like this:
{
"@odata.context": "https://selectapi.datascope.refinitiv.com/RestApi/v1/$metadata#RawExtractionResults/$entity",
"JobId": "0x084d16104a586fd1",
"Notes": [
"Extraction Services Version 16.3.44775 (2a6cb5e55172), Built Dec 15 2022 22:43:57
User ID: 9008895
Extraction ID: 2000000495197416
Correlation ID: CiD/9008895/0x0000000000000000/REST API/EXT.2000000495197416
Schedule: 0x084d16104a586fd1 (ID = 0x0000000000000000)
Input List (1 items): (ID = 0x084d16104a586fd1) Created: 12/30/2022 16:47:19 Last Modified: 12/30/2022 16:47:19
Report Template (4 fields): _OnD_0x084d16104a586fd1 (ID = 0x084d16104a686fd1) Created: 12/30/2022 16:45:45 Last Modified: 12/30/2022 16:45:45
Schedule dispatched via message queue (0x084d16104a586fd1), Data source identifier
…
…"
]
}
The job id in the samples above is 0x084d16104a586fd1. With a job id, users can query the status of an extraction, list all extracted files, download an extraction result, and cancel a job.
This article introduces the endpoints used to manage LSEG History on-demand extraction jobs and files.
- Query Jobs
- Cancel a Job
- List all extracted files of a job
- Download an extraction result
- Delete files
A sample postman collection and postman environment are also available on GitHub.
1. Query Jobs
The LSEG Tick History REST provides several /Jobs/Jobs endpoints which can be used to get a list of jobs and statuses.
| HTTP Method | Endpoint | Descriptions |
|---|---|---|
| GET | /Jobs/Jobs | Return all Jobs |
| GET | /Jobs/JobGetActive | Returns the active (in progress jobs) for all asynchronous requests |
| GET | /Jobs/JobGetCompleted | Returns the completed jobs |
| GET | /Jobs/Jobs({JobId}) | Returns a single job |
For example, the following is a response when using the /Jobs/Jobs endpoint to get all jobs.
{
"@odata.context": "https://selectapi.datascope.refinitiv.com/RestApi/v1/$metadata#Jobs",
"value": [
{
"JobId": "0x084ee2e040e872ea",
"UserId": 9008895,
"Status": "Completed",
"StatusMessage": " ",
"Description": "TickHistoryTimeAndSalesReportTemplate Extraction",
"ProgressPercentage": 0,
"CreateDate": "2023-01-04T07:45:18.580Z",
"StartedDate": "2023-01-04T07:45:18.580Z",
"CompletionDate": "2023-01-04T07:48:53.206Z",
"MonitorUrl": "https://selectapi.datascope.refinitiv.com/restapi/v1/Extractions/ExtractRawResult(ExtractionId='0x084ee2e040e872ea')"
},
{
"JobId": "0x084ea401d178727d",
"UserId": 9008895,
"Status": "Completed",
"StatusMessage": " ",
"Description": "TickHistoryTimeAndSalesReportTemplate Extraction",
"ProgressPercentage": 0,
"CreateDate": "2023-01-04T04:20:01.593Z",
"StartedDate": "2023-01-04T04:20:01.593Z",
"CompletionDate": "2023-01-04T04:23:38.746Z",
"MonitorUrl": "https://selectapi.datascope.refinitiv.com/restapi/v1/Extractions/ExtractRawResult(ExtractionId='0x084ea401d178727d')"
},
…
]
}
The possible values of the Status property are:
- NotStarted
- InProgress
- Completed
- Error
- PendingCancellation
- Canceled
- Purged
The monitor URL allows callers to retrieve the results, status, or error message. Asynchronous jobs are kept in the system for a maximum of seven days.
The retrieved response may contain the @odata.nextlink property if the number of jobs in the response is more than 250 records, as shown below. (250 is the default value of the page size for endpoints that support paging.)
{
"@odata.context": "https://selectapi.datascope.refinitiv.com/RestApi/v1/$metadata#Jobs",
"value": [
…
{
"JobId": "0x084d45c8b9f86ffb",
"UserId": 9008895,
"Status": "Completed",
"StatusMessage": " ",
"Description": "TickHistoryTimeAndSalesReportTemplate Extraction",
"ProgressPercentage": 0,
"CreateDate": "2022-12-30T10:38:32.216Z",
"StartedDate": "2022-12-30T10:38:32.216Z",
"CompletionDate": "2022-12-30T10:40:10.006Z",
"MonitorUrl": "https://selectapi.datascope.refinitiv.com/restapi/v1/Extractions/ExtractRawResult(ExtractionId='0x084d45c8b9f86ffb')"
}
],
"@odata.nextlink": "https://selectapi.datascope.refinitiv.com/RestApi/v1/Jobs/Jobs?$skiptoken='MjAyMi0xMi0zMFQxMDozODozMi4yMTYwMDAwfDF8'"
}
The @odata.nextlink property contains the URL used to retrieve the next 250 records.
https://selectapi.datascope.refinitiv.com/restapi/v1/Extractions/ExtractRawResult(ExtractionId='0x084f461873387377')

The HTTP response status will be 204 No Content and the Job status will be changed to PendingCancellation.
{
"JobId": "0x084f461873387377",
"UserId": 9008895,
"Status": "PendingCancellation",
"StatusMessage": "PendingCancellation",
"Description": "TickHistoryTimeAndSalesReportTemplate Extraction",
"ProgressPercentage": 0,
"CreateDate": "2023-01-05T08:42:09.420Z",
"StartedDate": "2023-01-05T08:42:09.420Z",
"MonitorUrl": "https://selectapi.datascope.refinitiv.com/restapi/v1/Extractions/ExtractRawResult(ExtractionId='0x084f461873387377')"
}
3. List all extracted files of a Job
For completed on-demand extractions, users can get a list of extracted files associated with a Job ID by using an extraction ID. An extraction ID can be retrieved from the Notes when accessing the monitor URL.
For example, the following in the Notes when accessing the monitor URL of the Job ID: 0x084d16104a586fd1.
{
"@odata.context": "https://selectapi.datascope.refinitiv.com/RestApi/v1/$metadata#RawExtractionResults/$entity",
"JobId": "0x084d16104a586fd1",
"Notes": [
"Extraction Services Version 16.3.44775 (2a6cb5e55172), Built Dec 15 2022 22:43:57
User ID: 9008895
Extraction ID: 2000000495197416
Correlation ID: CiD/9008895/0x0000000000000000/REST API/EXT.2000000495197416
Schedule: 0x084d16104a586fd1 (ID = 0x0000000000000000)
Input List (1 items): (ID = 0x084d16104a586fd1) Created: 12/30/2022 16:47:19 Last Modified: 12/30/2022 16:47:19
Report Template (4 fields): _OnD_0x084d16104a586fd1 (ID = 0x084d16104a686fd1) Created: 12/30/2022 16:45:45 Last Modified: 12/30/2022 16:45:45
Schedule dispatched via message queue (0x084d16104a586fd1), Data source identifier
…
…"
]
}
Then, an extraction ID can be used with the /Extractions/ReportExtractions({id})/Files endpoint to get a collection of files that belong to this extraction report.
For example, the following is a response when using the /Extractions/ReportExtractions('2000000495197416')/Files endpoint to get all files belong the extraction ID: 2000000495197416.
{
"@odata.context": "https://selectapi.datascope.refinitiv.com/RestApi/v1/$metadata#ExtractedFiles",
"value": [
{
"ExtractedFileId": "VjF8MHgwODRkNGZmZGNkODg3MDE2fA",
"ReportExtractionId": "2000000495197416",
"ScheduleId": "0x084d16104a586fd1",
"FileType": "Note",
"ExtractedFileName": "_OnD_0x084d16104a586fd1.csv.gz.notes.txt",
"LastWriteTimeUtc": "2022-12-30T09:47:19.746Z",
"ContentsExists": true,
"Size": 1333,
"ReceivedDateUtc": "2022-12-30T09:47:19.746Z"
},
{
"ExtractedFileId": "VjF8MHgwODRkNDZiNjE3ZDg2ZmZlfA",
"ReportExtractionId": "2000000495197416",
"ScheduleId": "0x084d16104a586fd1",
"FileType": "Full",
"ExtractedFileName": "_OnD_0x084d16104a586fd1.csv.gz",
"LastWriteTimeUtc": "2022-12-30T09:47:19.000Z",
"ContentsExists": true,
"Size": 135779
}
]
}
Each file has a unique ID called ExtractedFileId. Users can use extracted file IDs (ExtractedFileId) to download or delete files.
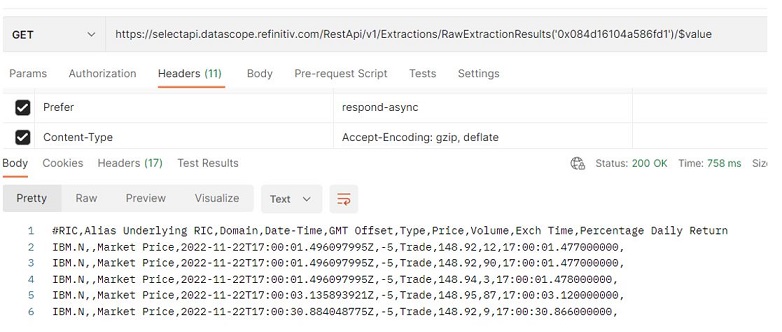
- Use an extracted file ID
Users can also use an extracted file ID (ExtractedFileId) with the /Extractions/ExtractedFiles(‘<Extracted File ID>’)/$value endpoint to download an extracted file. This endpoint can only be used to download an extraction result or note files.
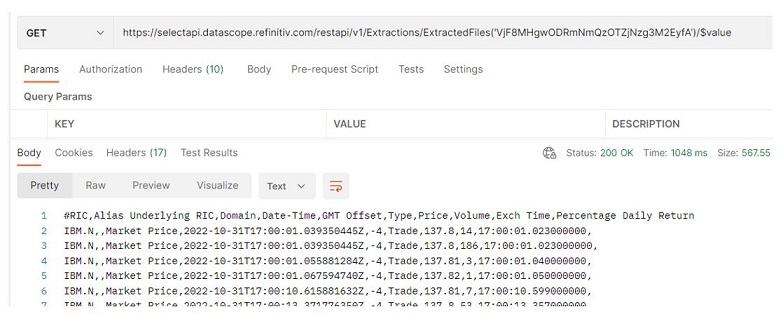
5. Delete files
The API provides the /Extractions/ExtractedFiles endpoint to get a list of extracted files, download files, and delete files.
| HTTP Method | Endpoint | Description |
|---|---|---|
| GET | /Extractions/ExtractedFiles | Retrieves all ExtractedFiles by paging via the @odata.nextlink property) |
| GET | /Extractions/ExtractedFiles('<Extracted File ID>') |
Retrieves a single ExtractedFile |
| GET | /Extractions/ExtractedFiles('<Extracted File ID>')/$value | Delivers the content of the file |
| DELETE | /Extractions/ExtractedFiles('<Extracted File ID>') | Deletes related file content |
| POST | /Extractions/ExtractedFileDeleteMultiple | Deletes related file content for multiple extractions |
Typically, users don’t require to delete on-demand extracted files because on-demand extractions expire after 3 days. However, files can be deleted by using extracted file IDs and the /Extractions/ExtractedFiles endpoint.
- Delete a single file
The API provides the /Extractions/ExtractedFiles(‘<Extracted File ID>’) endpoint to delete a single file by using an extracted file ID. For example, use the following endpoint with the HTTP DELETE method to delete the extracted file with the extracted file ID (VjF8MHgwODRmNmQzOTZjNzg3M2EyfA).
/Extractions/ExtractedFiles('VjF8MHgwODRmNmQzOTZjNzg3M2EyfA')
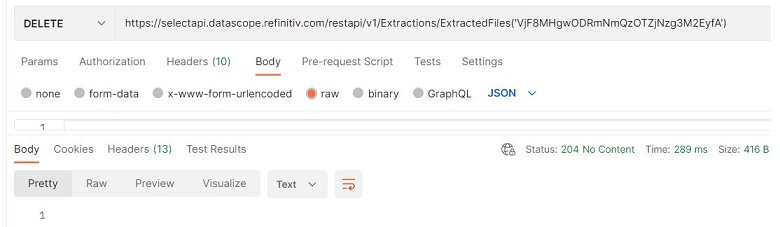
The HTTP response status is 204 No Content and the file has been deleted.
- Delete multiple files
The API also provides the /Extractions/ExtractedFileDeleteMultiple endpoint to delete multiple files by using extracted file IDs. For example, specify a list of extracted file IDs (ExtractedFieldIds) in the message body and use the /Extractions/ExtractedFileDeleteMultiple endpoint with the HTTP POST method to delete multiple files.
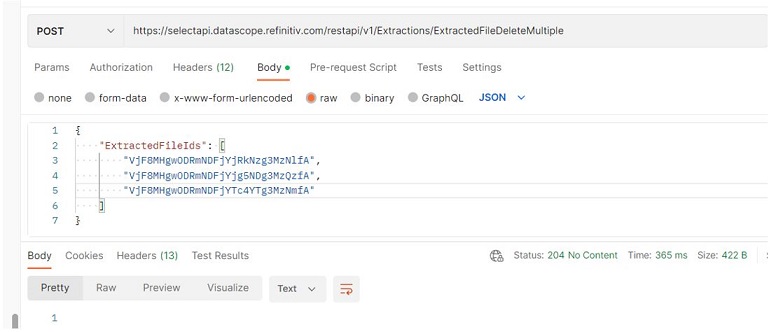
The HTTP response status is 204 No Content and files have been deleted.
Postman Examples
A postman collection and postman environment are available on GitHub. This postman example provides the sample HTTP request messages to perform jobs and files management, as explained in this article. You can download this Postman collection and environment and import them into your Postman application.
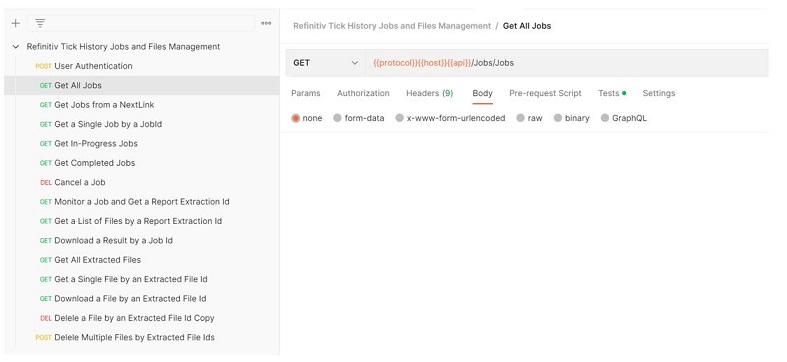
LSEG Tick History Jobs and Files Management Collection
LSEG Tick History Jobs and Files Management Environment
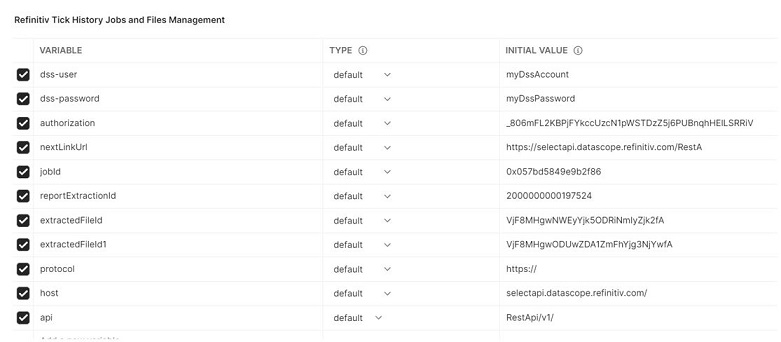
Set the dss-user and dss-password variables to a DSS username and password respectively before sending the HTTP request messages.
Summary
Tick History REST API supports on-demand extractions to extract data from the Tick History server. Each on-demand extraction starts a job and each job has a unique id. Users can use a job ID to query the status of an extraction, list all extracted files, download an extraction result, and cancel a job. Moreover, the API also provides the endpoints to manage extracted files, such as getting files’ descriptions, downloading files, and deleting files. The Postman collection is also available on GitHub.
References
- LSEG (2023) Best Practices & Fair Usage Policy for DataScope Select and Tick History, Documentation | Devportal. Available at: https://developers.lseg.com/en/api-catalog/refinitiv-tick-history/refinitiv-tick-history-rth-rest-api/documentation#best-practices-and-fair-usage-policy-for-data-scope-select-and-tick-history (Accessed: 12 May 2023).
- LSEG (no date) DSS REST API Reference Tree. Available at: https://selectapi.datascope.refinitiv.com/RestApi.Help/Home/RestApiProgrammingSdk (Accessed: 12 May 2023).
- Register or Log in to applaud this article
- Let the author know how much this article helped you