
Divide and Conquer in Action
Downloading a Large Tick History File with Python

Introduction
There are many approaches and techniques that can be utilized to download files. The most obvious and simple approach is, to just request the file, to receive it fully, and to store it locally.
In this article, we are going to discuss an approach to downloading really large files from RDP CFS - Tick History service, that is robust, and minimizes the chances of a potential failure.
The two primary aspects that should enable us to get down our large file with a large decree of reliability and that we will next focus on are:
- Streaming the file via requests module, rather then downloading as a whole
- Partitioning a large requirement into smaller pieces, that can also serve as checkpoints, and only requesting one piece, at a time by using HTTP request header Range
Let us introduce the concepts that will be part of the discussion:
- Refinitiv Data Platform (RDP)
- Client File Store (CFS)
- Tick History (TH)
- Python Jupyter Notebook - a Python interface to run, document, share and learn Python code, that will be our vehicle
Authentication Requirement
RDP CFS Tick History service that is used to obtain Tick History files requires authentication with valid RDP credentials. In order to keep the focus of this discussion on downloading large tick history files, while still fullfilling the authentication requirements, and including the complete working example that is available for download on GitHub ( see References) authentication is implemented in a separate AuthTokenHandling notebook. We install module ipynb and reference the notebook from the same directory:
from ipynb.fs.full.AuthTokenHandling import getToken
next we are ready to call the defined functions:
Authenticate- Call getToken
accessToken = getToken();
print("Have token now");
Request File Sets - Define a Helper Function
We are going to identify required FileSet and required FileID
def requestFileSets(token, withNext, skipToken, bucket, attributes):
global FILESET_ENDPOINT
print("Obtaining FileSets in "+bucket+" Bucket...")
FILESET_ENDPOINT = RDP_BASE_URL+'/file-store'+RDP_CFS_VERSION + '/file-sets?bucket='+ bucket
querystring = {}
payload = ""
jsonfull = ""
jsonpartial = ""
headers = {
'Content-Type': "application/json",
'Authorization': "Bearer " + token,
'cache-control': "no-cache"
}
if attributes:
FILESET_ENDPOINT = FILESET_ENDPOINT + attributes
if withNext:
FILESET_ENDPOINT = FILESET_ENDPOINT + '&skipToken=' +skipToken
response = requests.request("GET", FILESET_ENDPOINT, data=payload, headers=headers, params=querystring)
if response.status_code != 200:
if response.status_code == 401: # error when token expired
accessToken = getToken(); # token refresh on token expired
headers['Authorization'] = "Bearer " + accessToken
response = requests.request("GET", FILESET_ENDPOINT, data=payload, headers=headers, params=querystring)
print('Raw response=');
print(response);
if response.status_code == 200:
jsonFullResp = json.loads(response.text)
return jsonFullResp;
else:
return '';
So that next we can
Request FileSets Containing Large Tick History File -
The file we are going to use as example is FRA-2020-02-25-NORMALIZEDMP-Data-1-of-1
We request Tick History File Sets for a venue FRA and limit by dates 2020.02.25 to 2020.02.29, and the first FileSet should contain the file ID of the file that we require.
RDP_TH_BUCKET = "TICKHISTORY_VBD_UNLIMITED"
CFS_VBD_VENUE = "FRA"
CFS_VBD_VIEW = "normalised"
jsonFullResp = requestFileSets(accessToken, False, '',RDP_TH_BUCKET,'&attributes=venue:'+CFS_VBD_VENUE+',view:'+CFS_VBD_VIEW+
'&contentFrom=2020-02-25T00:00:00Z&contentTo=2020-02-29T00:00:00Z');
print('Same response, tabular view');
df = pd.json_normalize(jsonFullResp['value'])
df

Select File Id
We are going to select the first File ID in the File Set, to use 2020.02.25 FRA normalized as an example of a large file. Another large file can be handled analogously- we just need it's File ID to proceed
FILE_ID = df.iloc[0]['files'][0]
print('FILE_ID selected is: ' + FILE_ID)
Get TH File Details by File ID - Define a Helper Function
FILES_ENDPOINT_START = RDP_BASE_URL+'/file-store'+RDP_CFS_VERSION + '/files/'
def requestFileDetails(token, fileId):
print("Obtaining File details for File= "+ fileId + " ...")
print("(If result is Response=400, make sure that fileId is set with a valid value...)")
FILES_ENDPOINT = FILES_ENDPOINT_START + fileId
querystring = {}
payload = ""
jsonfull = ""
jsonpartial = ""
headers = {
'Content-Type': "application/json",
'Authorization': "Bearer " + token,
'cache-control': "no-cache"
}
response = requests.request("GET", FILES_ENDPOINT, data=payload, headers=headers, params=querystring)
if response.status_code != 200:
if response.status_code == 401: # error when token expired
accessToken = getToken(); # token refresh on token expired
headers['Authorization'] = "Bearer " + accessToken
response = requests.request("GET", FILES_ENDPOINT, data=payload, headers=headers, params=querystring)
print('Raw response=');
print(response);
if response.status_code == 200:
jsonFullResp = json.loads(response.text)
return jsonFullResp;
else:
return '';
that we can next use to
Request File Details of a Large File
* We verify the size of the file to be retrieved
* Store its file name and file size
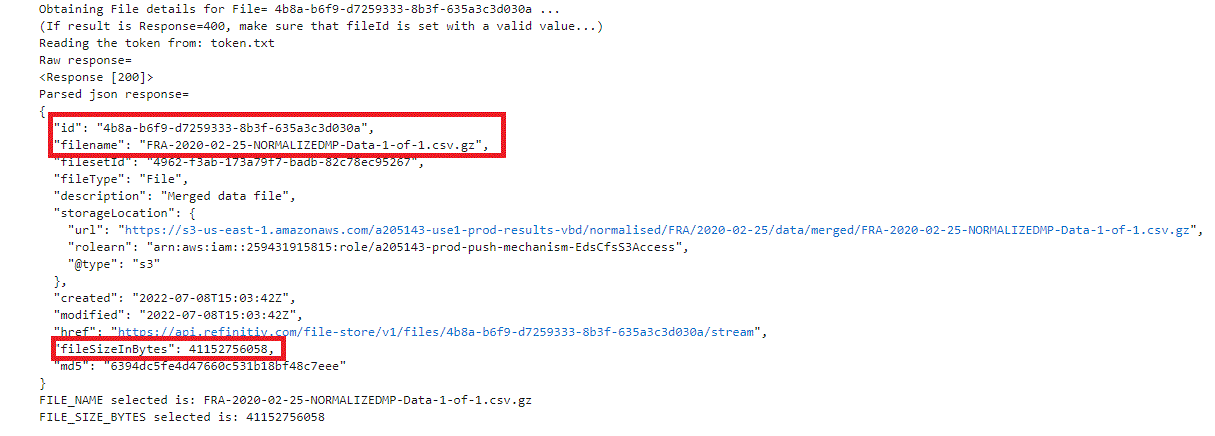
jsonFullResp = requestFileDetails(accessToken, FILE_ID);
print('Parsed json response=');
print(json.dumps(jsonFullResp, indent=2));
FILE_NAME = jsonFullResp['filename'];
print('FILE_NAME selected is: ' + FILE_NAME)
FILE_SIZE_BYTES = jsonFullResp['fileSizeInBytes'];
print('FILE_SIZE_BYTES selected is: ' + str(FILE_SIZE_BYTES))
with what we have learned from the File details, we are ready to download as two step, without Redirect:
- Obtain the complete file location (URL)
- Stream and download file in chunks, continuously copying to disk just as it becomes ready
Get File Location (Step 1 of 2)
FILES_STREAM_ENDPOINT_START = RDP_BASE_URL+'/file-store'+RDP_CFS_VERSION + '/files/'
DIRECT_URL = ''
def requestFileLocation(token, fileId):
FILES_STREAM_ENDPOINT = FILES_STREAM_ENDPOINT_START + fileId+ '/stream?doNotRedirect=true'
print("Obtaining File ... " + FILES_STREAM_ENDPOINT)
chunk_size = 1000
headers = {
'Authorization': 'Bearer ' + token,
'cache-control': "no-cache",
'Accept': '*/*'
}
response = requests.request("GET", FILES_STREAM_ENDPOINT, headers=headers, stream=False, allow_redirects=False)
if response.status_code != 200:
if response.status_code == 401: # error when token expired
accessToken = getToken(); # token refresh on token expired
headers['Authorization'] = "Bearer " + accessToken
response = requests.request("GET",FILES_STREAM_ENDPOINT, headers=headers, stream=False, allow_redirects=False)
print('Response code=' + str(response.status_code));
if response.status_code == 200:
jsonFullResp = json.loads(response.text)
DIRECT_URL = jsonFullResp['url'];
print('File Direct URL is: ' +str(DIRECT_URL));
return DIRECT_URL;
DIRECT_URL = requestFileLocation(accessToken, FILE_ID);

and
Download File From File Location in Chunks (Step 2 of 2)
The chunk size can be tuned for the specific environment and the required download size. chunkSize=3000000000 has worked well in my environment for the 38G file that was downloaded.
from urllib.parse import urlparse, parse_qs
def requestDirectFileDownload(token, fileURL, fileName,fileSizeBytes, chunkSize):
print("Obtaining File from URL... " + fileURL + '... to file name=' + fileName+ ', it\'s size is '+ str(fileSizeBytes))
headers_ = {
'Accept': '*/*',
}
#Parse out URL parameters for submission into requests
url_obj = urlparse(fileURL)
parsed_params = parse_qs(url_obj.query)
# extract the URL without query parameters
parsed_url = url_obj._replace(query=None).geturl()
for i in range(0, fileSizeBytes, chunkSize):
rangeEnd = i+chunkSize -1
if rangeEnd > (fileSizeBytes -1):
rangeEnd = fileSizeBytes -1
rangeExpression = 'bytes='+str(i)+'-'+str(rangeEnd)
print('Processing rangeExpression='+rangeExpression)
headers_['Range'] = rangeExpression
# ignore verifying the SSL certificate as example only 'verify=False'
# otherwise add security certificate
response = requests.get(parsed_url, headers = headers_, params=parsed_params, stream=True) #, verify=False)
print('Response code=' + str(response.status_code)+ ' text='+ str(response.reason));
if response.status_code != 206:
if response.status_code == 401: # error when token expired
accessToken = getToken(); # token refresh on token expired
headers_['Authorization'] = "Bearer " + accessToken
response = requests.get(parsed_url, params=parsed_params, headers=headers_, stream=True) #, verify=False)
elif response.status_code == 400: #bad request
break;
filename = 'downloaded_'+fileName
if response.status_code == 206:
print('Processing into file '+str('downloaded_'+fileName)+' ...')
with open(filename, 'ab') as fd:
shutil.copyfileobj(response.raw, fd)
print('Look for gzipped file named: '+ 'downloaded_'+filename + ' in current directory')
response.connection.close()
return;
requestDirectFileDownload(accessToken, DIRECT_URL, FILE_NAME, FILE_SIZE_BYTES, 3000000000);

<<<>>>

Now our large file is ready to unzip and use as required.
To learn more, visit us on LSEG Developers Forums
References
- Quick Start | LSEG Developers -Refinitiv Data Platform APIs Quick Start Guide
- Documentation | LSEG Developers -CFS API User Guide
- LSEG Data Platform Questions - Forum | LSEG Developer Community -Developer Q&A Forums
- API Playground - API Playground