
Christiaan Meihsl
Head of Developer Content, Platform Application Developer
Head of Developer Content, Platform Application Developer
Last Updated: Jan 2026
Introduction
The purpose of this article is to explain what the Tick History AWS feature is, sometimes also referred to as S3, how you can use it when programming in various languages, and investigate its efficiency in speeding up Tick History data downloads.
You need some notions of Tick History to understand this article. To experiment with the API a valid Tick History user account is also required.
Disclaimer
The performance numbers given in this article are purely indicative, and do not constitute a guarantee of any sort.
What is AWS ?
In June 2017, a new feature was added to the Tick History REST API: AWS downloads. This is the capability to download extracted data directly from the AWS (Amazon Web Services) cloud in which they are hosted, instead of from the DataScope servers. Its purpose is very simple: to enhance the download speed.
This feature was originally limited to VBD (Venue by Day) data, because those were the largest data sets, but in August 2017 it was extended to the following custom Tick History reports:
- Tick History Time and Sales
- Tick History Market Depth
- Tick History Intraday Summaries
- Tick History Raw reports
Nothing changed for the other Tick History reports; you continue downloading the data from the DataScope servers.
How does a request to AWS work ?
This feature only applies to the extraction data download, not to the other API calls. In other words, only the final API call to retrieve the extracted data must be modified, to specify that you want to download the data from AWS instead of from the DataScope servers.
All that is required is to include the HTTP header field X-Direct-Download: true in the request, and the request will be automatically redirected to Amazon, ensuring that you receive the extraction file in the shortest possible time.
Remember that this only applies to VBD files, and the 4 reports mentioned in the previous section. Adding the header to other requests will have no effect.
Let us look at the sequence of requests and responses.
Flow diagram

Data request
Method: GET
Endpoint: https://selectapi.datascope.lseg.com/RestApi/v1/Extractions/RawExtractionResults('0x05709cc5aadc3156')/$value
Headers:
Authorization: Token <your_auth_token_goes_here>
Prefer: respond-async
X-Direct-Download: true
The last header is the one we add to use AWS.
Response
We receive a response with HTTP status 302 (redirect). The response header contains a redirection URI in item Location. The location URI looks like this:
https://s3.amazonaws.com/tickhistory.query.production.hdc-results/C15C8A6BBD824C5FB5BE39AD36BD9B16/data/merged/merged.csv.gz?AWSAccessKeyId=AKIAJVAI4XORJURKYMEA&Expires=1508181359&response-content-disposition=attachment%3B%20filename%3D_OnD_0x05e996379ebb3036.csv.gz&Signature=6TRD6XTbeesQ7165A3KF%2BDofgPs%3D&x-amz-request-payer=requester
This is a self signed URI, using an AWS Access Key Id. This built-in authentication key avoids having to synchronize authentication details between AWS and DataScope servers.
Redirection handling
Most HTTP clients automatically follow the redirection.
Some HTTP clients (like curl command, or Invoke-WebRequest of Powershell) support and follow the redirection, but fail to connect to AWS, because they include the Authorization header in the request message redirected to AWS, which returns a BadRequest status (400) with the error:
“Only one auth mechanism allowed; only the X-Amz-Algorithm query parameter, Signature query string parameter or the Authorization header should be specified”.
This is because the AWS servers receive two authentication keys, which is not allowed:
- The Authorization header
- The AWS Access Key Id (in the URI)
If your HTTP client does not automatically follow the redirection, or if it re-uses the original request headers in the redirection and runs into this error, then you must use some simple programming (illustrated further in Java) to overcome this behavior:
- If required, send the data request with redirection disabled.
- Retrieve from the 302 header the Location item, which is the pre-signed URI that allows you to get your data directly from AWS.
- Perform a GET on this URI, without using the original headers (in particular the Authorization header).
How to use AWS downloads from the GUI ?
Since end October 2017 it is possible to use AWS downloads from the GUI. This can be enabled in the Preference screen:

How to code for AWS downloads ?
Let us now look at some code that implements AWS downloads.
Bear in mind that the HTTP header field X-Direct-Download: true must only be added for the calls that retrieve the extracted data. As a best practice it should not be added to the other API calls, i.e. those that send the original extraction request, poll the status, retrieve file IDs or the notes file. Note: if you add it by mistake to a call it does not apply to, it will be ignored.
AWS download in Postman
You can test this in Postman. Ensure that redirection is enabled in the Postman settings:

Then add the new header in the call to request the data:
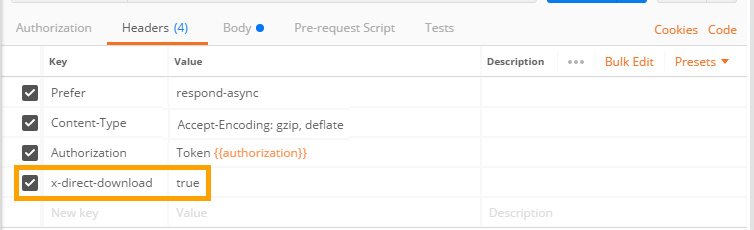
When viewing the results, you will notice the result window displays unreadable encrypted data. This behavior is due to the response headers, which differ between DataScope and AWS.
DataScope returns the following content related headers:
Content-Encoding:gzip
Content-Type:text/plain
AWS returns different headers:
Content-Disposition:attachment; filename=_OnD_0x05de99857e5b3036.csv.gz
Content-Type:application/gzip
Postman automatically decompresses the data if it finds the following header:
Content-Encoding:gzip
AWS does not return that header, so Postman does not decompress the data. To verify that AWS actually returns a gzip file, you can save the returned data instead of displaying it. Instead of clicking on “Send” to submit the data retrieval request, use the dropdown menu to select “Send and Download”, then look at the file.
To conclude: AWS download works as expected; the data is just not decompressed automatically by Postman because of the different AWS response headers.
AWS download in C#, using the .Net SDK
With the .Net SDK it is very easy to use AWS downloads. Most of the work is handled for you in the background. All you need to do is add the required header to select AWS download, by referring to the extractions context. Our .Net SDK Tutorials code samples for .Net SDK Tutorials 2 (VBD), 4 (schedule) and 5 (on demand) simply add it to the default header before retrieving the data, and remove it afterwards:
//Set the header for AWS download in the default headers set:
extractionsContext.DefaultRequestHeaders.Add("x-direct-download", "true");
//Retrieve all the data files:
[…]
//Remove the header for AWS download from the default headers set:
extractionsContext.DefaultRequestHeaders.Remove("x-direct-download");
AWS download in Python
The code is easy. First we set up the data request call, with the additional header:
requestUrl = "https://selectapi.datascope.lseg.com/RestApi/v1/Extractions/RawExtractionResults" + "('" + jobId + "')" + "/$value"
requestHeaders={
"Prefer":"respond-async",
"Content-Type":"text/plain",
"Accept-Encoding":"gzip",
"X-Direct-Download":"true",
"Authorization": "token " + token
r = requests.get(requestUrl,headers=requestHeaders,stream=True)
The redirection is handled automatically, we move on to save the compressed data to file:
#Ensure we do not automatically decompress the data on the fly:
r.raw.decode_content = False
fileName = filePath + fileNameRoot + ".csv.gz"
chunk_size = 1024
rr = r.raw
with open(fileName, 'wb') as fd:
shutil.copyfileobj(rr, fd, chunk_size)
fd.close
Our Tick History Python On Demand Intraday Bars code sample implements AWS downloads, saving compressed data to file, as well as reading it from file, to decompress and treat it.
AWS download in Java
As we are not using an SDK, and we must handle the redirection manually, the code is slightly more involved.
First we set up the data request call, with the additional header:
String urlGet=urlHost+"/Extractions/ExtractedFiles('"+ExtractedFileId+"')/$value";
HttpGet requestGet = new HttpGet(urlGet);
requestGet.addHeader("Authorization", "Token "+sessionToken);
requestGet.addHeader("Prefer", "respond-async");
requestGet.addHeader("X-Direct-Download", "true");
try {
HttpClientContext context = HttpClientContext.create();
HttpResponse responseGet = httpclient.execute(requestGet, context);
Then we retrieve the redirection URI from the response header item Location:
//Initialise awsURI to the initial URI (the same value as that of urlGet):
URI awsURI = requestGet.getURI();
//Retrieve the last Location, which is the AWS URL:
List<URI> locations = context.getRedirectLocations();
if (locations != null) {
awsURI = locations.get(locations.size() - 1);
} else {
throw new IOException("ERROR: could not retrieve the AWS URI");
}
Finally we retrieve the data from AWS, using the self signed redirection URI. We do not add any headers (with the Tick History session token this call would fail):
URL myURL = awsURI.toURL();
HttpURLConnection myURLConnection = (HttpURLConnection)myURL.openConnection();
//This works both with compressed and non compressed files
try( DataInputStream readerIS = new DataInputStream(
myURLConnection.getInputStream())) {
Files.copy (readerIS, Paths.get (filename));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
In this example we simply save the data to file.
Four of our Java code samples implement AWS downloads, and demonstrate saving the data or treating it on the fly:
- DSS2ImmediateScheduleIntradayBarsRTH
- DSS2ImmediateScheduleTicksRTH
- DSS2OnDemandIntradayBarsRTH
- DSS2OnDemand TicksRTH
AWS download performance
Why is AWS faster ?
Before looking at the numbers, let us look at what is happening behind the scenes.
When you download from DataScope servers, this is the path your data follows:
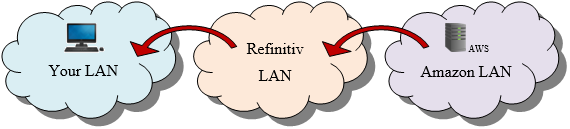
The mention of an AWS server here is no mistake: the DataScope servers are hosted in the Amazon Web Services cloud. But when you download from DataScope servers you transit through the Refinitiv LAN before and after accessing the AWS server.
When you download directly from AWS, this is the path your data follows:
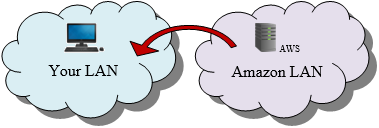
This shorter path is the key to better performance.
Using AWS has a cost: it requires a redirection, and a separate authentication mechanism (the self signed URL). This overhead is the reason why AWS is only used for data downloads that can deliver significantly large results.
AWS use is optional, you are free to use it or not (for instance if your security policies do not allow redirections).
Influence of the size of the data set
With a direct AWS download, the only overhead is the initial redirect. For very small data extractions this redirect overhead becomes significant, and AWS might not deliver the expected advantage. But as soon as the data set is medium to large (above ~1MB), the direct AWS connection’s benefits become obvious.
Location influence
The DataScope and AWS servers are located in the US, so if you are located in the US you are lucky, you will get better performance.
Side note, only for LSEG employees
If you are on the LSEG internal network, due to different network paths you will not necessarily benefit from AWS. If you need to download large amounts of data, make a few tests to find out what performance to expect.
Numbers, numbers ...
Important caveat
Bandwidth measurements on the internet are very unreliable, due to many influencing factors, quite a few of which are out of our control !
Absolute values are practically meaningless and can vary greatly, but ratios - like that between the DataScope and AWS download speed measured in the same conditions - can deliver insights.
The numbers that follow are purely indicative, and do not constitute a guarantee of any sort.
Test methodology
To compare the download performance from DataScope (abbreviated DSS in the tables below) and AWS, I asked a few colleagues to download a set of VBD files, using a pre-built C# test application. Each file was downloaded once from DataScope, and immediately afterwards once from AWS. We did not run parallel downloads. File sizes and timestamps were logged for later analysis.
This was done using internet connections in 4 locations: 2 in North America, 2 in Europe.
The most thorough test was run in Toronto, on a total of 120 samples, from 4 to 11 AM (GMT time). The 3 other tests were on small data sets, between 5 and 11 files.
Test results analysis
The influence of the file size was obvious, so the throughput numbers were averaged in 5 buckets corresponding to increasing file sizes.
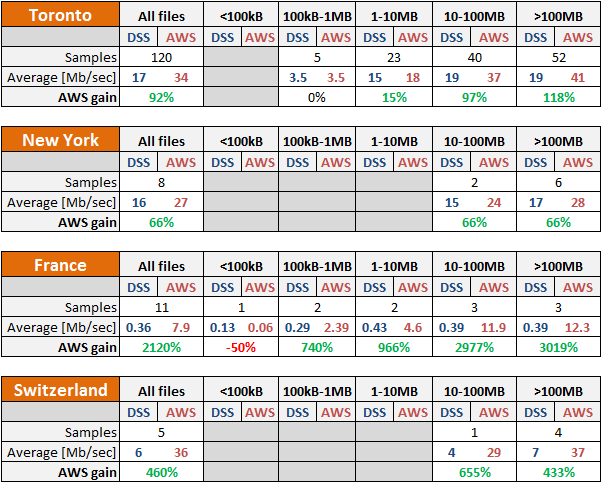
Numerical results:
Charts:
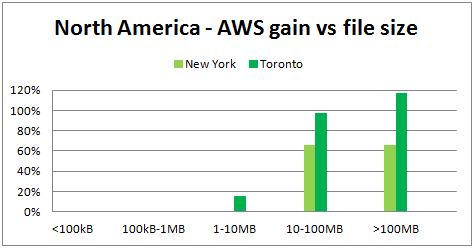

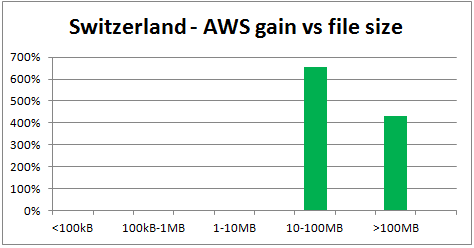
In the following chart, the X-axis is in GMT time:
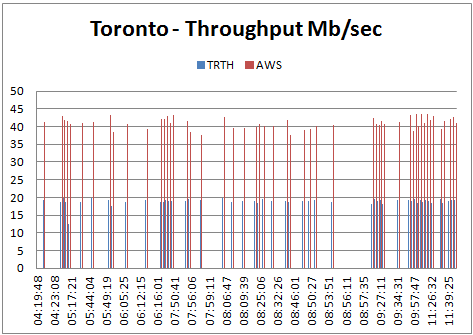
Analysis:
We observe several things:
- Overall, AWS delivers better throughput.
Exception: files <100kB, where DataScope seems to have the advantage. - Maximum DataScope throughput:
- North America: ~ 18Mb/sec
- Europe: ~7Mb/sec (40% of N. America)
- Maximum AWS throughput:
- North America: ~41Mb/sec
- Europe: ~37Mb/sec (90% of N. America)
- Gain obtained by using AWS:
- North America: ~66-118%
- Europe: ~600-3000%
The higher gain in Europe is not due to higher AWS performance versus North America, it is due to lower DataScope performance in Europe.
- The Toronto measurements seem to indicate that DataScope and AWS performance do not vary significantly between 4 and 11 AM GMT. This slightly contradicts other DataScope measurements made in August 2017 from Switzerland, in which a degradation in download speed of approximately 20% was observed after 8 AM GMT. As the test conditions are different, it is difficult to compare these results.
We must remember that all these numbers are unreliable, but from these observations we can draw a few simple guidelines:
- For small On Demand requests (any request for less than 100kB of data), using DataScope to retrieve the data will probably deliver better performance.
- For large On Demand requests (more than 100kB of data), using AWS is a better choice that will deliver faster downloads.
- For VBD (Venue by Day) data files (most of which are very big), using AWS is a great advantage, delivering much faster throughput.
Other paths to optimize download performance
Using AWS for downloads is the optimization technique that delivers the greatest performance gain, but there are other factors that influence download performance:
- The available bandwidth of your internet connection, and other traffic sharing the same connection, between your machine and the DataScope or AWS servers.
- Server load, which can peak at some periods of the day.
- The nature of your data requests.
- How your code is written.
Please refer to this separate article, which discusses in detail how you can further try to optimize download performance.
Conclusions
Here is a brief summary of our findings:
- The AWS download feature can significantly boost the performance of Tick History data downloads.
- The improvement factor is low or nil for small data sets, but rapidly increases for medium to large ones.
- Download performance from DataScope and AWS servers vary depending on your location.
Get In Touch
Related Articles
Related APIs
Request Free Trial
Call your local sales team
Americas
All countries (toll free): +1 800 427 7570
Brazil: +55 11 47009629
Argentina: +54 11 53546700
Chile: +56 2 24838932
Mexico: +52 55 80005740
Colombia: +57 1 4419404
Europe, Middle East, Africa
Europe: +442045302020
Africa: +27 11 775 3188
Middle East & North Africa: 800035704182
Asia Pacific (Sub-Regional)
Australia & Pacific Islands: +612 8066 2494
China mainland: +86 10 6627 1095
Hong Kong & Macau: +852 3077 5499
India, Bangladesh, Nepal, Maldives & Sri Lanka:
+91 22 6180 7525
Indonesia: +622150960350
Japan: +813 6743 6515
Korea: +822 3478 4303
Malaysia & Brunei: +603 7 724 0502
New Zealand: +64 9913 6203
Philippines: 180 089 094 050 (Globe) or
180 014 410 639 (PLDT)
Singapore and all non-listed ASEAN Countries:
+65 6415 5484
Taiwan: +886 2 7734 4677
Thailand & Laos: +662 844 9576