

Basic Feature Engineering
This Blueprint touches upon three of the basic steps that may be taken through the feature engineering phase of an AI pipeline. These steps are treatment of missing values by utilising the various available imputation and filtering approaches, feature scaling that will make the features AI friendly especially for algorithms that are sensitive to scale and outliers treatment including detection and algorithms to remove or re-scale. The blueprint is mainly using tools provided by scikit-learn.
Let's start by importing all the modules that will be used during the blueprint.
import pandas as pd
import refinitiv.data as rd
import random
import copy
import numpy as np
from os.path import exists
from sklearn.impute import SimpleImputer, KNNImputer
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.ensemble import IsolationForest
from math import sqrt
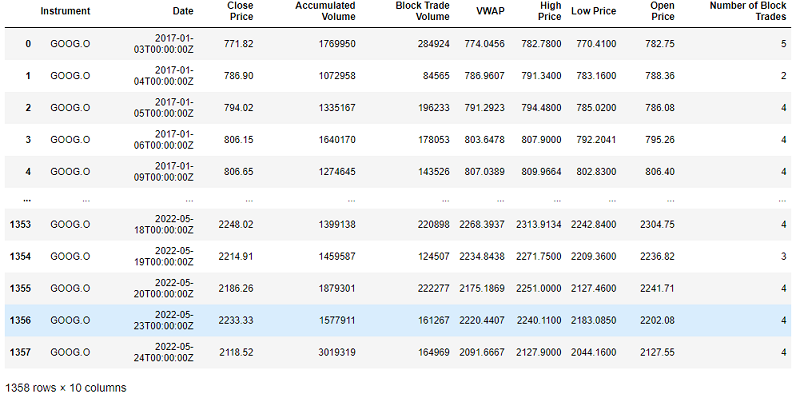
We will now use the Refinitiv Data library to ingest some historical data on the GOOG.O RIC. Specifically for the purposes of the blueprint we will be ingesting timestamps, close prices, accumulated volumes, block trade volumes, VWAP data, high and low price as well as number of block trades daily for the period of 2017-01-01 to 2022-05-24.
if not exists('../data/alphabet.csv'):
ek.set_app_key('DEFAULT_CODE_BOOK_APP_KEY')
df, err = ek.get_data(
instruments = ['GOOG.O'],
fields = ['TR.PriceCloseDate(Frq=D,SDate=2017-01-01,EDate=2022-05-24)',
'TR.CLOSEPRICE(Frq=D,SDate=2017-01-01,EDate=2022-05-24)',
'TR.ACCUMULATEDVOLUME(Frq=D,SDate=2017-01-01,EDate=2022-05-24)',
'TR.BLOCKTRADEVOLUME(Frq=D,SDate=2017-01-01,EDate=2022-05-24)',
'TR.TSVWAP(Frq=D,SDate=2017-01-01,EDate=2022-05-24)',
'TR.HIGHPRICE(Frq=D,SDate=2017-01-01,EDate=2022-05-24)',
'TR.LOWPRICE(Frq=D,SDate=2017-01-01,EDate=2022-05-24)',
'TR.OPENPRICE(Frq=D,SDate=2017-01-01,EDate=2022-05-24)',
'TR.NUMBEROFBLOCKTRADES(Frq=D,SDate=2017-01-01,EDate=2022-05-24)'
]
)
df.to_csv('../data/alphabet.csv', index=True)
else:
df = pd.read_csv('../data/alphabet.csv')
The code snippet above downloads the data and saves it in a .csv file so that you do not have to download the data every time you re-run your prototype. Let's have a look at the downloaded dataframe:
Imputation
Imputation is a process that can be used to deal with missing values. While deleting missing values is a possible approach to tackle the problem, it can lead to significant degrading of the dataset as it decreases the volume of available data. Imputation tries to fill in the missing values, categorical or numeric, and there are numerous techniques that can be used during the process. Let's randomly remove 5% of the records from the Number of Block Trades so we can explore some of the methodologies:
block_trades = copy.deepcopy(df['Number of Block Trades'])
ix_remove = [random.randrange(1, len(block_trades), 1) for i in range(int(0.1*len(block_trades)))]
block_trades.iloc[ix_remove] = np.nan
block_trades_nans = copy.deepcopy(block_trades)

The easiest way to impute missing value is to use a statistic generated through the series itself and replace all NaNs with it. Here's an attempt to use the mean as a replacement value. The median and mode is always another option that can be used.
block_trades_pandas = np.ndarray.flatten(block_trades.fillna(block_trades.mean()).to_numpy().reshape(-1, 1))
array([5. , 2. , 4.40243902, ..., 4. , 4. , 4. ])
Let's now turn into other possible methodologies and use the impute module within scikit-learn. The SimpleImputer is essentially the same with the pandas methodology and we can again ask for different imputation strategies.
block_trades_array_simp = block_trades_nans.to_numpy().reshape(-1, 1)
s_imp = SimpleImputer(missing_values=np.nan, strategy='median')
s_imp.fit(block_trades_array_simp)
block_trades_array_simp = np.ndarray.flatten(s_imp.transform(block_trades_array_simp))
array([5., 2., 4., ..., 4., 4., 4.])
While the SimpleImputer can only treat the feature as a disconnected series, IterativeImputer can leverage on other feature data to impute the missing values. Essentialy IterativeImputer can generate a function of the treated feature against the other available features. The IterativeImputer is only available as an experimental feature in sklearn. Let's impute the number of block trades taking into account the Block Trade Volume.
block_trades_array_iimp = block_trades_nans.to_numpy().reshape(-1, 1)
block_trade_volume_array = df['Block Trade Volume'].to_numpy().reshape(-1, 1)
i_imp = IterativeImputer()
i_imp.fit(block_trade_volume_array)
block_trades_array_iimp = np.ndarray.flatten(i_imp.transform(block_trades_array_iimp))
array([5.00000000e+00, 2.00000000e+00, 2.34793858e+05, ...,
4.00000000e+00, 4.00000000e+00, 4.00000000e+00])
Another interesting imputer available in sklearn.impute is the K Nearest Neighbor imputer. The methodology will first try to create feature clusters then use the mean of the cluster to impute the missing values.
block_trades_array_knnimp = block_trades_nans.to_numpy().reshape(-1, 1)
knn_imp = KNNImputer(n_neighbors=50)
knn_imp.fit(block_trades_array_knnimp)
block_trades_array_knnimp = np.ndarray.flatten(knn_imp.transform(block_trades_array_knnimp))
array([5. , 2. , 4.40243902, ..., 4. , 4. ,4. ])
We will now use the Root Mean Square Error (RMSE) and the more intuitive Mean Absolute Percentage Error (MAPE) to evaluate the different imputation methods we showcased and see which one performed the best in the specific use case. For the purposes of MAPE we write a small function.
def mape(actual, pred):
return np.mean(np.abs((actual-pred)/actual)* 100)
block_trades_actual = df['Number of Block Trades'].to_numpy()
rmse_pandas = sqrt(mean_squared_error(block_trades_actual, block_trades_pandas))
mape_pandas = mape(block_trades_actual, block_trades_pandas)
print(f'Pandas Imputation RMSE:{rmse_pandas}, MAPE:{mape_pandas}%')
rmse_simp = sqrt(mean_squared_error(block_trades_actual, block_trades_array_simp))
mape_simp = mape(block_trades_actual, block_trades_array_simp)
print(f'Median Imputation RMSE:{rmse_simp}, MAPE:{mape_simp}%')
rmse_iimp = sqrt(mean_squared_error(block_trades_actual, block_trades_array_iimp))
mape_iimp = mape(block_trades_actual, block_trades_array_iimp)
print(f'Iterative Imputation RMSE:{rmse_iimp}, MAPE:{mape_iimp}%')
rmse_knnimp = sqrt(mean_squared_error(block_trades_actual, block_trades_array_knnimp))
mape_knnimp = mape(block_trades_actual, block_trades_array_knnimp)
print(f'KNN Imputation RMSE:{rmse_knnimp}, MAPE:{mape_knnimp}%')
Pandas Imputation RMSE:0.6763511663087829, MAPE:3.965007373748259%
Median Imputation RMSE:0.6929053473051033, MAPE:3.4679266895761742%
Iterative Imputation RMSE:72083.10868837175, MAPE:603280.3480915561%
KNN Imputation RMSE:0.6763511663087829, MAPE:3.965007373748259%
We can see from the results that the iterative imputator failed to generate a good function estimate of block trades using block trade volume and that the best imputation approach on this case is the Median Imputation from the SimpleImpute module. There exist many more Imputation approaches and some can be more sophisticated like e.g. using Random Forests for Imputation.
Scaling
AI and machine learning algorithms can be very sensitive to the scale of the features. Two of the prevailing methodologies that are used in the industry are:
- Min-Max scaling: All numerical features are scaled in the range of 0 to 1.
- Standardisation: The features are scaled so that they are transformed into a distribution with a mean of 0 and variance 1.
Lets drop Instrument and Date for the purposes of the blueprint and apply the two methodologies to the remainder of the feature set.
df_to_scale = copy.deepcopy(df)
df_to_scale = df_to_scale.drop(['Instrument', 'Date'], axis=1)
mm_scaler = MinMaxScaler()
mm_scaler.fit(df_to_scale)
scaled_array = mm_scaler.transform(df_to_scale)
scaled_df = pd.DataFrame(scaled_array, columns = df_to_scale.columns)
std_scaler = StandardScaler()
std_scaler.fit(df_to_scale)
scaled_array = std_scaler.transform(df_to_scale)
scaled_df = pd.DataFrame(scaled_array, columns = df_to_scale.columns)
Outlier Detection
Unusual values can often be found in datasets for many reasons, these are called outliers. Outliers can bias AI models if not handled appropriately. Numerous approaches exist to handle the problem and amongst others we can:
- Remove the outlier records: This approach may reduce the number of available records for AI training and harm model performance.
- Replace outliers: We can handle outliers as missing data and follow all the relevant impute methods.
- Cap features: Establish acceptable feature maximums and minimums and replace outliers with those values
Regardless of the methodology that is followed and even if we need the outliers to remain in the dataset as they are, it is important to know the record indexes that hold these outliers. Some initial insight on the existence of outliers can be revealed through the boxplot of a feature. We will plot the boxplots of the scaled features as this will still reveal outliers but will be more easily visualised as the distributions remain the same.
scaled_df.boxplot()
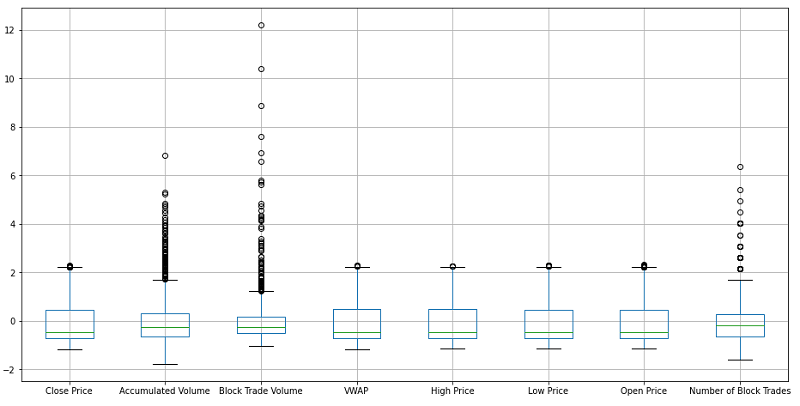
It is important to note that outlier detection through a boxplot can only be used for initial insight as the outliers are detected assuming features are disconnected from each other. Let's now use an isolation forest to detect the outliers within our feature set. Isolation forests will look into all the interconnections within the feature set provided:
outlier_model = IsolationForest(n_estimators=300, contamination=0.1)
outlier_model.fit(scaled_df)
outlier_predictions = outlier_model.predict(scaled_df)
outliers = scaled_df[outlier_predictions == -1]
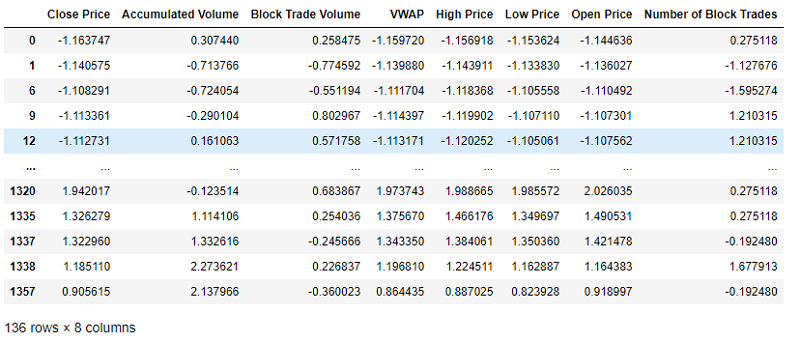
We can see that the algorithm detected 136 outlier points in our dataset. We will now write a small example to see the effect of removing the outlier data on a simple regressing AI trying to predict number of block trades on this dataset.
y = scaled_df['Number of Block Trades']
x = scaled_df.drop(['Number of Block Trades'], axis=1)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
regressor_model = RandomForestRegressor(n_estimators=50)
regressor_model.fit(x_train, y_train)
y_hat = regressor_model.predict(x_test)
rmse = sqrt(mean_squared_error(y_test, y_hat))
print(f'RMSE without outlier removal: {rmse}')
RMSE without outlier removal: 0.6661564163581338
Let's now train and evaluate the same model after outlier removal:
x_clean = x.drop(outliers.index.values.tolist())
y_clean = y.drop(outliers.index.values.tolist())
x_train, x_test, y_train, y_test = train_test_split(x_clean, y_clean, test_size=0.25)
regressor_model = RandomForestRegressor(n_estimators=50)
regressor_model.fit(x_train, y_train)
y_hat = regressor_model.predict(x_test)
rmse = sqrt(mean_squared_error(y_test, y_hat))
print(f'RMSE with outlier removal: {rmse}')
RMSE with outlier removal: 0.6217787493786675
We can see that the model performance has increased after removing the detected outliers from the Isolation Forest, therefore we could benefit if we removed those from the final feature set.
Conclusions
In this article we have explored several Blueprints regarding imputation, the process of interpolating missing values. We have looked into both baseline techniques as well as somewhat more sophisticated ones. We have also looked at Scaling methodologies to use when the AI is known to be sensitive during the modelling and evaluation phase. Finally, we explored outlier detection and have quantified its potential benefits through a simple Random Forest regression Blueprint.