
Wasin Waeosri
Developer Advocate
Developer Advocate
Introduction
Last Update October 2025
For the Municipal Market Monitor (TM3) file users: There is an article aims for your TM3 bulk file available on the A Step By Step Guide for Getting Municipal Market Monitor (TM3) Bulk File Using C# article. I highly recommend you check it.
Important for Messenger Compliance External feeds users: On 28 April 2024, a new version of Messenger will be released in parallel with a new External Feeds offering, which will allow customers to retrieve their compliance files in JSON format using this Client File Store (CFS) API. For more details on support, refer to PCN208738.
The Client File Store (CFS) is a capability of Delivery Platform (RDP, previously known as Refinitiv Data Platform) that provides authorization and enables access to content files stored in publisher repositories. LSEG provides various content file domains (aka bucket) for consumers such as:
- CFS ESG data
- Green Revenue data
- Symbology data
- Tick History
- Starmine
- Municipal Market Monitor (TM3)
And much more.
The Client File Store (CFS) is a component of the RDP which let consumers access via a set of HTTP RESTful APIs. This article contains a step-by-step, generic workflow guide from the authentication and download the file for any buckets (ESG, Symbology, Green Revenue, etc). The example source code is written in Python and Jupyter environment. However, our APIs are the web-based API, so any programming langues can connect and consume data using the same concept.
If you are intetersted to use the File Notification Service combine with the CFS Service for more automation process, please check the part 2 article, How to use File Notification Message Distribution with the Client File Store (CFS) Service article.
What is Delivery Platform (RDP) APIs?
The Delivery Platform - (RDP) provide various LSEG data and content for developers via easy-to-use Web-based API.
RDP APIs give developers seamless and holistic access to all of the LSEG content such as Environmental Social and Governance (ESG), News, Research, etc, and commingled with their content, enriching, integrating, and distributing the data through a single interface, delivered wherever they need it. The RDP APIs delivery mechanisms are the following:
- Request - Response: RESTful web service (HTTP GET, POST, PUT or DELETE)
- Alert: delivery is a mechanism to receive asynchronous updates (alerts) to a subscription.
- Bulks: deliver substantial payloads, like the end-of-day pricing data for the whole venue.
- Streaming: deliver real-time delivery of messages.
This example project is focusing on the Request-Response: RESTful web service delivery method only.
For more detail regarding RDP, please see the following APIs resources:
- Quick Start page.
- Tutorials page.
What is CFS?
Client File Store (CFS) aka File Distribution is a capability of Delivery Platform (RDP) that provides authorization and enables access to content files stored in publisher-supplied repository. CFS defines content ownership that publisher are isolated. And subscribers can trust the source of content.
CFS is engineered as a self-service metadata tool intend for publishers and subscribers. CFS provides bucket and file-set to organize files to simplify the interaction with publishers or subscribers CFS doesn't store file directly. Actual files are store in publisher-supplied. AWS S3 only one type storage that supported by current CFS.
Bucket
CFS facilitates buckets for use by Publishers to organize file-sets and files. Buckets store metadata about the files stored in publisher-supplied repositories. Buckets align with subscriptions and can contain multiple file-sets and files.
Publishers are responsible for creating buckets with the CFS API. This is a one-time process. The resulting bucket is owned one or more Publishers and is assigned a unique name that cannot be assigned to another bucket. A Publisher can have multiple buckets if they provide more than one dataset.
Claims are used to control access to buckets, file-sets and files. CFS does not manage or create claims, CFS only enforces them. Claims must be created in AAA. Subscribers must have at least one of the claims on the bucket in order to access the bucket.
Attributes are used to allow Subscribers to filter and search for content. Attributes are one method that a Subscriber can use to find files and/or file-sets.
Packages
A package is an indivisible set of file-sets that are all delivered together. Packages can consist of multiple file-sets that a grouping of file-sets.
The publisher will define the metadata for each package of content available to subscribers in CFS. Publishers are responsible for creating Packages and assigning claims to them.
Publisher need to create package first and then publisher able to create file-sets into Packages.
Fileset
A file-set is an indivisible set of files that are all delivered together. They can consist of multiple files that make up one large file or a grouping of files that represent related content. A file-set can also contain a single file. The Publisher decides the appropriate organization of their file-sets.
Publishers are responsible for creating file-sets into Packages. A Publisher can have multiple file-sets in a bucket.
Once all files have been added to the file-set and are ready for download, the Publisher updates the file-set status to READY. This enables the Publisher to control the release of their files and sets expectations for when the files will be available to subscribers. File-sets with a status of READY cannot be updated or modified. Updates must be published as a new file-set.
To access a file-set, Subscribers must have access to the bucket in which the file-set resides and have all of the claims associate with the file-set.
Files
Subscribers can only access the files to which they are entitled. On AWS S3, Subscribers can access files using a signed URI that redirects to the file on AWS S3 for downloading.
Files are available for a defined period of time that is determined by the Publisher.
Please find more detail on the CFS API User Guide document.
Prerequisite
Before I am going further, there is some prerequisite, dependencies, and libraries that the project is needed.
Access to the RDP with the your desire CFS file permission
This project uses RDP access credentials with the CFS file permission. You need both RDP User-ID (email base) and Machine-ID (GE-A-XXXXX) user types.
- User-ID: Identifier for user allowing access to contracted content and APIs on the API Playground page (https://apidocs.refinitiv.com/Apps/ApiDocs) or Bulk UI via Workspace/Eikon Desktop. It normally is email address of user (example: sample@lseg.com).
- Machine ID: Identifier for machine allowing access and run this tool or any automate applications. It normally is a username with "GE-A-XXXXXXXX" format.
Please see more detail about how to setup your RDP User-ID and Machine-ID from the Getting Started with Data Platform article.
Please contact your LSEG representative to help you with the RDP account and the bucket permission.
Internet Access
This demonstration connects to RDP on AWS via a public internet.
Python and Jupyter Notebook.
This project uses Python and Jupyter environment.
The Python Anaconda or MiniConda distribution/package manager is recommended.
RDP APIs Application Workflow
Step 1: Authentication with RDP APIs
Let’s start with the authentication. The CFS APIs are considered protected resources and require that your application be authenticated before making a data call. This authentication and provisioning of access token is based on OAuth 2.0 specification. The first step of an application workflow is to get a token from RDP Auth Service, which will allow access to the protected resource, i.e. data REST API.
The API requires the following access credential information:
- Username: The username/machine-id.
- Password: Password associated with the username/machine-id.
- Client ID: This is also known as AppKey, and it is generated using an App key Generator. This unique identifier is defined for the user or application and is deemed confidential (not shared between users). The client_id parameter can be passed in the request body or as an “Authorization” request header that is encoded as base64.
- Grant Type password: This is for initial authentication request. An application does not have any token, so it requests new tokens using username/password combination.
The HTTP request for the RDP APIs Authentication service is as follows:
POST /auth/oauth2/v1/token HTTP/1.1
Accept: */*
Content-Type: application/x-www-form-urlencoded
Host: api.refinitiv.com:443
Content-Length: XXX
username=RDP_USERNAME
&password=RDP_PASSWORD
&client_id=RDP_APP_KEY
&grant_type=password
&takeExclusiveSignOnControl=true
&scope=trapi
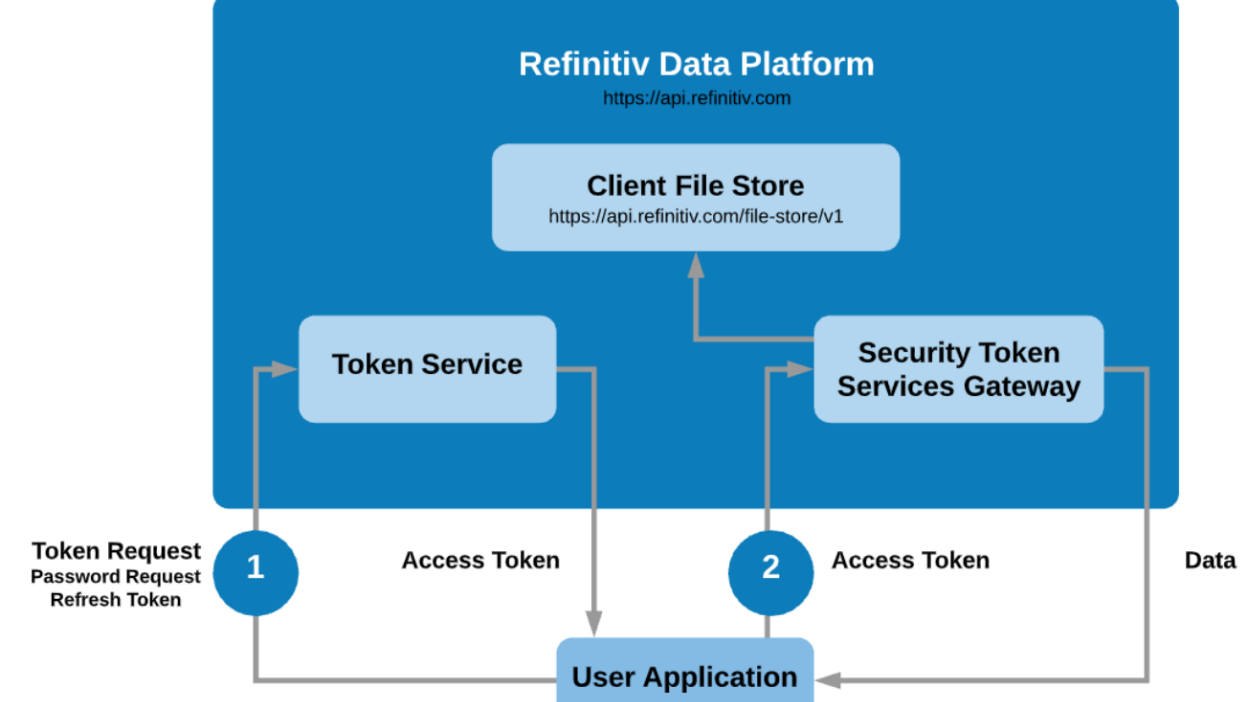
Once the authentication success, the function gets the RDP Auth service response message and keeps the following RDP token information in the variables.
- access_token: The token used to invoke REST data API calls as described above. The application must keep this credential for further RDP APIs requests.
- refresh_token: Refresh token to be used for obtaining an updated access token before expiration. The application must keep this credential for access token renewal.
- expires_in: Access token validity time in seconds.
Next, after the application received the Access Token (and authorization token) from RDP Auth Service, all subsequent REST API calls will use this token to get the data. Please find more detail regarding RDP APIs workflow in the following resources:
- RDP APIs: Introduction to the Request-Response API page.
- RDP APIs: Authorization - All about tokens page.
Example source code in Python:
import requests
username = 'your RDP Machine-ID'
password = 'your RDP Password'
clientId = 'your RDP APP Key'
RDP_HOST= 'https://api.refinitiv.com'
acccess_token = None
refresh_token = None
expires_in = 0
# Send HTTP Request
auth_url = f'{RDP_HOST}/auth/oauth2/v1/token'
payload = f'grant_type=password&username={username}&client_id={clientId}&password={password}&takeExclusiveSignOnControl=True&scope=trapi'
try:
auth_response = requests.post(auth_url,
headers = {'Content-Type':'application/x-www-form-urlencoded'},
data = payload,
auth = (clientId, '')
)
except requests.exceptions.RequestException as exp:
print(f'Caught exception: {exp}')
The next step is checking the authentication request result, then get the token information and assign them to local variables for the later use.
if auth_response.status_code == 200: # HTTP Status 'OK'
print('Authentication success')
access_token = auth_response.json()['access_token']
refresh_token = auth_response.json()['refresh_token']
expires_in = int(auth_response.json()['expires_in'])
if auth_response.status_code != 200:
print(f'RDP authentication failure: {auth_response.status_code} {auth_response.reason}')
print(f'Text: {auth_response.text}')
Now we have the access token information that can be used for further data requests.
Requesting Data from RDP APIs
That brings us to requesting the RDP APIs data. All subsequent REST API calls must include the Access Token via the Authorization HTTP request message header as shown below to get the data.
- Header:
- Authorization = Bearer <RDP Access Token>
Please notice the space between the Bearer and RDP Access Token values.
If the token is still valid and has appropriate scope, the request is allowed to access the data.
The application then creates a request message in a JSON message format or URL query parameter based on the interested service and sends it as an HTTP request message to the Service Endpoint. Developers can get RDP APIs the Service Endpoint, HTTP operations, and parameters from Delivery Platform's API Playground page - which is an interactive documentation site developers can access once they have a valid Delivery Platform account.
Step 2: Listing the packageIds using the Bucket Name
Important Note: If you already know your Package-ID (please contact your Account Manager), you can skip this step!!!
Now let me move on to the CFS APIs call. To request the CFS data, the first step is to send an HTTP GET request to the RDP /file-store/v1/packages?bucketName={bucket-name} endpoint to list all Package Ids under the input bucket-name.
The HTTP Request structure is as follows:
GET /file-store/v1/packages?bucketName={bucket-name} HTTP/1.1
Host: api.refinitiv.com
Authorization: Bearer <Access Token>
The example bucket names for RDP content set are as follows:
| Content | Bucket Name | Example of Package Id |
|---|---|---|
| Financial Markets Reference Data | bulk-FMRD | 4d48-d7ff-edcc3d38-8243-a4f7517962b8 |
| Symbology | bulk-Symbology | 4c80-73a0-fcef949b-bfde-2b9b8117cfb0 |
| ESG | bulk-ESG | 4288-ebb6-93372235-acb2-89882a826af1 |
| ESG - Point in Time | bulk-ESG | 4173-aec7-8a0b0ac9-96f9-48e83ddbd2ad |
| Tick History | TICKHISTORY_VBD_NO_EMBARGO | 4c01-ab9e-db594a31-a8f5-5b7852ec4638 |
| Green Revenue | bulk-GreenRevenue | Summary: 4e94-6d63-fea034dc-90e2-de33895bd4e9 |
| Green Revenue | bulk-GreenRevenue | Standard: 4316-d43b-81c40763-8e6a-0dbec8162ab1 |
| Starmine | STARMINE_PREDICTIVE_ANALYTICS_SMARTECON_LIVE | 40d4-1404-58533484-afe8-718650a4e0d4 |
| Municipal Market Monitor (TM3) | bulk-Custom | 4c5b-0f65-c57f5ae4-b548-2a1075ee725d |
Note: The bucket name is case-insensitive.
For the Municipal Market Monitor (TM3) file users: There is an article aims for your TM3 bulk file available on the A Step By Step Guide for Getting Municipal Market Monitor (TM3) Bulk File Using C# article. I highly recommend you check it.
If you cannot find the bucket name for your interested content set, please contact your LSEG representative. I am using the bulk-ESG as an example bucket name for the Python code.
# set Bucket Name, this notebook use bulk-ESG as an example
bucket_name = 'bulk-ESG'
#step 2 - list Package IDs from bucket name
CFS_url = f'{RDP_HOST}/file-store/v1/packages?bucketName={bucket_name}'
try:
packageID_response = requests.get(CFS_url, headers={'Authorization': f'Bearer {access_token}'})
except requests.exceptions.RequestException as exp:
print(f'Caught exception: {exp}')
if packageID_response.status_code == 200: # HTTP Status 'OK'
print('Receive list Package IDs from RDP APIs')
else:
print(f'RDP APIs: CFS request failure: {packageID_response.status_code} {packageID_response.reason}')
print(f'Text: {packageID_response.text}')
You can check the example data response to see the example of PackageIds from the following code:
#Example of the first entry of package IDs
print(json.dumps(packageID_response.json()['value'][0], sort_keys=True, indent=2, separators=(',', ':')))
Result:
{
"bucketNames":[
"bulk-ESG"
],
"contactEmail":"robin.fielder@refinitiv.com",
"created":"2021-11-11T07:54:04Z",
"modified":"2023-02-10T09:10:16Z",
"packageId":"4037-e79c-96b73648-a42a-6b65ef8ccbd1",
"packageName":"Bulk-ESG-Global-Symbology-Organization-v1",
"packageType":"bulk"
}
More on /file-store/v1/packages parameters
Beside the packageName query, the /file-store/v1/packages endpoint supports the following optional parameters:
- packageType: Return all packages that match the specified package type.
- bucketName:Return all packages that are associated with the specified bucket name.
- page: Filter results by a specific pagination index (If client has already specified this query parameter, the skipToken logic will be excluded)
- includedTotalResult: The total search result will be counting and added to the first response message.
- skipToken: A token to retrieve the next set of result that exceeds page size.
- pageSize: The number of packages that will be shown on one page. Default value is 25. Maximum is 100.
- includedEntitilementResult: CFS will perform a permission check on each package against the client permission.
Tips
It is recommended to call the endpoint with pageSize=100 parameter as follows:
GET /file-store/v1/packages?bucketName={bucket-name}&pageSize=100 HTTP/1.1
Host: api.refinitiv.com
Authorization: Bearer <Access Token>
Please find more detail on the CFS API User Guide document.
Step 3: Listing the FileSets using the Bucket Name and Package ID
Now we come to getting the FileSets information. The application needs to send an HTTP GET request to the RDP /file-store/v1/file-sets?bucket={bucket-name}&packageId={packageId} endpoint to list all FileSets under the input bucket-name and packageId.
The HTTP Request structure is as follows:
GET /file-store/v1/file-sets?bucket={bucket-name}&packageId={packageId} HTTP/1.1
Host: api.refinitiv.com
Authorization: Bearer <Access Token>
This article uses 4037-e79c-96b73648-a42a-6b65ef8ccbd1 packageId of the bulk-ESG bucket as an example.
If you cannot find the package Id for your interested content set, please contact your LSEG representative.
Python code:
# pick the packageId you need and set to the packageId variable
#packageId = response.json()['value'][0]['packageId']
packageId = '4037-e79c-96b73648-a42a-6b65ef8ccbd1'
#step 3 - list FileSets from bucket name and package Id
CFS_url = f'{RDP_HOST}/file-store/v1/file-sets?bucket={bucket_name}&packageId={packageId}'
try:
fileSet_response = requests.get(CFS_url, headers={'Authorization': f'Bearer {access_token}'})
except requests.exceptions.RequestException as exp:
print(f'Caught exception: {exp}')
if fileSet_response.status_code == 200: # HTTP Status 'OK'
print('Receive FileSets list from RDP APIs')
else:
print(f'RDP APIs: CFS request failure: {fileSet_response.status_code} {fileSet_response.reason}')
print(f'Text: {fileSet_response.text}')
The FileSets response message from the API is as follows:
{
"attributes":[
{
"name":"ContentType",
"value":"Symbology Organization"
}
],
"availableFrom":"2023-11-26T16:18:44Z",
"availableTo":"2023-12-10T16:18:44Z",
"bucketName":"bulk-ESG",
"contentFrom":"1970-01-01T00:00:00Z",
"contentTo":"2023-11-26T15:55:00Z",
"created":"2023-11-26T16:18:44Z",
"files":[
"4de0-ceda-25b5a1f1-9b7e-35c10b384078"
],
"id":"4646-6302-b810e622-8808-85367d798021",
"modified":"2023-11-26T16:18:49Z",
"name":"Bulk-ESG-Global-Symbology-Organization-v1-Jsonl-Init-2023-11-26T16:04:11.525Z",
"numFiles":1,
"packageId":"4037-e79c-96b73648-a42a-6b65ef8ccbd1",
"status":"READY"
}
The File ID is in the files array above. I am demonstrating with the 4c35-1775-c1a590ea-8376-ac6c1546b908 file id.
More on /file-store/v1/file-sets?bucket parameters
Beside the bucket and packageIdqueries, the /file-store/v1/file-sets?bucket endpoint supports the following optional parameters:
- name: The name of the file-set. Only exactly matched results are returned.
- packageId: Package ID
- status: Filter file-set by status (Ready/Pending)
- availableFrom: Return all file-sets that become visible to permissioned users after the specified Datetime.
- availableTo: Return all file-sets that is no longer visible to permissioned user after the specified Datetime.
- contentFrom: Filter results by the age of the content within the file-set.
- contentTo: Filter results by the age of the content within the file-set.
- createdSince: Return all file-sets that have a created date after the specified Datetime
- modifiedSince: Return all file-sets that have a modified date after the specified Datetime.
- attributes: Return a list of publisher-defined attributes of the file-sets.
- pageSize: The number of file-sets that will be shown on one page. Default value is 25. Maximum is 100.
- skipToken: A token to retrieve the next set of file-set result that exceeds page size.
The modifiedSince parameter can help an application to limit the returned File-Set only for the File-Set that has been modified after a specified time.
Tips
It is recommended to call the endpoint with pageSize=100 and modifiedSince parameters as follows:
GET /file-store/v1/file-sets?bucket={bucket-name}&packageId={packageId}&modifiedSince={datetime}&pageSize=100 HTTP/1.1
Host: api.refinitiv.com
Authorization: Bearer <Access Token>
Example:
GET /file-store/v1/file-sets?bucket=bulk-ESG&packageId=4288-ebb6-93372235-acb2-89882a826af1&pageSize=100&modifiedSince=2022-01-26T00:00:00Z HTTP/1.1
Host: api.refinitiv.com
Authorization: Bearer <Access Token>
Please find more detail on the CFS API User Guide document.
Step 3.1: Listing the packageId using the Bucket Name - Paging
My next point is the paging feature. By default, the /file-store/v1/file-sets?bucket={bucket-name} endpoint always returns 25 results per request. You can adjust the number of return results via the pageSize query parameter, the maximum number is 100.
GET /file-store/v1/file-sets?bucket={bucket-name}&pageSize={number}, HTTP/1.1
Host: api.refinitiv.com
Authorization: Bearer <Access Token>
Let's try with pageSize=2 query as an example.
Python Code:
#step 3.1 - list FileSets from bucket name and package Id - with pageSize 2
CFS_url = f'{RDP_HOST}/file-store/v1/file-sets?bucket={bucket_name}&pageSize=2'
try:
fileSet_response = requests.get(CFS_url, headers={'Authorization': f'Bearer {access_token}'})
except requests.exceptions.RequestException as exp:
print(f'Caught exception: {exp}')
if fileSet_response.status_code == 200: # HTTP Status 'OK'
print('Receive list Package IDs from RDP APIs')
else:
print(f'RDP APIs: CFS request failure: {fileSet_response.status_code} {fileSet_response.reason}')
print(f'Text: {fileSet_response.text}')
Now we get 2 entries per request from the API as we set via pageSize=2 parameter:
{
"value":[
{
"attributes":[
{
"name":"ContentType",
"value":"Symbology Organization"
}
],
"availableFrom":"2023-11-26T16:18:44Z",
"availableTo":"2023-12-10T16:18:44Z",
"bucketName":"bulk-ESG",
"contentFrom":"1970-01-01T00:00:00Z",
"contentTo":"2023-11-26T15:55:00Z",
"created":"2023-11-26T16:18:44Z",
"files":[
"4de0-ceda-25b5a1f1-9b7e-35c10b384078"
],
...
},
{
"attributes":[
{
"name":"ContentType",
"value":"Symbology Organization"
}
],
"availableFrom":"2023-12-03T16:16:37Z",
"availableTo":"2023-12-17T16:16:37Z",
"bucketName":"bulk-ESG",
"contentFrom":"1970-01-01T00:00:00Z",
"contentTo":"2023-12-03T15:55:00Z",
"created":"2023-12-03T16:16:37Z",
"files":[
"4823-5fb2-67ae60ab-bd45-1699a214c428"
],
...
}
]
}
There is a @nextLink node contains the URL for requesting the next page of results with the following HTTP request.
GET {@nextLink URL}, HTTP/1.1
Host: api.refinitiv.com
Authorization: Bearer <Access Token>
Example of Python code:
if '@nextLink' in response.json():
next_link = response.json()['@nextLink']
#step 3.5 - list Package IDs from bucket name - with pageSize 2 - navigate to next link
CFS_url = f'{RDP_HOST}{next_link}'
try:
fileSet_response = requests.get(CFS_url, headers={'Authorization': f'Bearer {access_token}'})
except requests.exceptions.RequestException as exp:
print(f'Caught exception: {exp}')
if fileSet_response.status_code == 200: # HTTP Status 'OK'
print('Receive list Package IDs from RDP APIs')
else:
print(f'RDP APIs: CFS request failure: {fileSet_response.status_code} {fileSet_response.reason}')
print(f'Text: {fileSet_response.text}')
Result:
{
"value":[
{
"attributes":[
{
"name":"ContentType",
"value":"Symbology Organization"
}
],
"availableFrom":"2023-11-26T16:18:44Z",
"availableTo":"2023-12-10T16:18:44Z",
"bucketName":"bulk-ESG",
"contentFrom":"1970-01-01T00:00:00Z",
"contentTo":"2023-11-26T15:55:00Z",
"created":"2023-11-26T16:18:44Z",
"files":[
"4de0-ceda-25b5a1f1-9b7e-35c10b384078"
],
...
},
{
"attributes":[
{
"name":"ContentType",
"value":"Symbology Organization"
}
],
"availableFrom":"2023-12-03T16:16:37Z",
"availableTo":"2023-12-17T16:16:37Z",
"bucketName":"bulk-ESG",
"contentFrom":"1970-01-01T00:00:00Z",
"contentTo":"2023-12-03T15:55:00Z",
"created":"2023-12-03T16:16:37Z",
"files":[
"4823-5fb2-67ae60ab-bd45-1699a214c428"
],
...
}
]
}
Then you can continue to send requests to URL in @nextLink node to get the next page results.
Note: The /file-store/v1/packages?bucketName={bucket-name} endpoint on the step 2 above also supports the Paging feature with the same pageSize query parameter and @nextLink node.
Let’s leave the paging feature there.
Step 4: Get the file URL on AWS S3
Now let me turn to getting the file URL on Amazon AWS S3 service with the RDP /file-store/v1/files/{file ID}/stream endpoint.
The HTTP Request structure is as follows:
GET /file-store/v1/files/{fileId}/stream?doNotRedirect=true HTTP/1.1
Host: api.refinitiv.com
Authorization: Bearer <Access Token>
Python code:
# pick file id in FileSets response
file_id = response.json()['value'][0]['files'][1] #'4c35-1775-c1a590ea-8376-ac6c1546b908`'
#step 4 - get file URL from file id
FileID_url = f'{RDP_HOST}/file-store/v1/files/{file_id}/stream?doNotRedirect=true'
try:
fileID_response = requests.get(FileID_url, headers={'Authorization': f'Bearer {access_token}'})
except requests.exceptions.RequestException as exp:
print(f'Caught exception: {exp}')
if fileID_response.status_code == 200: # HTTP Status 'OK'
print('Receive File URL from RDP APIs')
else:
print(f'RDP APIs: CFS request failure: {fileID_response.status_code} {fileID_response.reason}')
print(f'Text: {response.text}')
file_url = fileID_response.json()['url']
print(file_url)
The File URL is in the url attribute of the response message.
Result:
'https://a206464-bulk-esg.s3.amazonaws.com/Bulk-ESG-Global-Symbology-Organization-v1/2023/11/26/Bulk-ESG-Global-Symbology-Organization-v1-Init-2023-11-26T16%3A04%3A11.525Z.jsonl.gz?x-request-Id=e7658630-f8c6-4bd3-9443-4d87efa20b5c&x-package-id=4037-e79c-96b73648-a42a-6b65ef8ccbd1&x-client-app-id=b4842f3904fb4a1fa18234796368799086c63541&x-file-name=Bulk-ESG-Global-Symbology-Organization-v1-Init-2023-11-26T16%3A04%3A11.525Z.jsonl.gz&x-fileset-id=4646-6302-b810e622-8808-85367d798021&x-bucket-name=bulk-ESG&x-uuid=GESG1-178570&x-file-Id=4de0-ceda-25b5a1f1-9b7e-35c10b384078&x-fileset-name=Bulk-ESG-Global-Symbology-Organization-v1-Jsonl-Init-2023-11-26T16%3A04%3A11.525Z&x-event-external-name=cfs-claimCheck-download&X-Amz-Security-Token=IQoJb3JpZ2luX2VjEFAaCXVzLWVhc3QtMSJHMEUCIEzV%2BjWQVpI6MyZSaZ8SDQHlLPSsv8n50rxgWVDO6l%2F6AiEAu6f00kJgGFokGZxSWXicGqPbiL2X1SwEI16MlBgrMQwqowIIuP%2F%2F%2F%2F%2F%2F%2F%2F%2F%2FARAEGgw2NDIxNTcxODEzMjYiDBu3pKa9FpE%2Fi14VMCr3AQDhdsrjQAR4YmsEBme6RolP2AlZSYOhk8cH5xRqqus1fYhG0jIxx5Rj0t5n7%2Fcy5fq7TX9ygoR4JJDjRKpHhS4weeTn2oqcEPEyGlegGJuktEjmWrRFqANR3vSzFQQbUECxDSC%2FnHAuIUz2X130j30SC31aNihaF1XNWJEGcxGYVNWKPslvVe3Ohg1euVup4kvH3YpIhfAGHnPHhyAHoK7M8K417rAMqkuSP05XGyf%2BD%2BuPSiS9n2EM66XnHZUthf5nkm70bk1%2B%2FpA%2BC5opQIRfhE7kHMg29qKWpPiyJJCtvmj9N79AeEwnfm%2FD%2BXlV5ZM%2BVx8cHGkw5YPLqwY6nQFj%2BbHSvw088XgcKLEde1RJdKZ9E1t39X%2FT3m765zf8I94m8skLdLd9tSJalzFnQbq%2BWx4zABO5VKm1xJ9Z%2FFyRklKzTX8B6fmV4ioEqbvauMn0OT4Lcn2BQLDoLefsZc0WaUQd5p1N8UVSfgVzcv3yNR4%2FHCFmXhKPMT%2F8MNWjlwG438YlrNRVCrWZpl2Eogx7shza%2Bl99v0rLdtF4&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20231208T071237Z&X-Amz-SignedHeaders=host&X-Amz-Expires=21600&X-Amz-Credential=ASIAZLA4M7GHBJJLJVV4%2F20231208%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Signature=8f67fbf45259c2830f7e2578d03e7e546832ef34fba37b769b951e071ad08175'
More on /file-store/v1/files/ parameters
Beside the file_id query, the /file-store/v1/files/ endpoint supports the following optional parameters:
- createdSince: Return all files that have a created date after the specified Datetime.
- modifiedSince: Return all files that have a modified date after the specified Datetime.
- pageSize: The number of files that will be shown on one page. Default value is 25.
- skipToken: A token to retrieve the next set of file result that exceeds page size
Please find more detail on the CFS API User Guide document.
Step 5: Downloading the file
That brings us to download the file. You can download the bulk file using that S3 URL (as is). Do not alter or make any changes to the URL text string. It will cause unable to download or signature mismatch error.
Note:
- If you cannot download the file, please wait for a while and then retry download the file from the URL. Please do not flush the download requests.
- The code below set verify = False property in a requests library call to workaround LSEG's beloved ZScaler blocks a download request message. Do not set verify = False in a Production.
I am demonstrating with the polling2 library.
Python code:
#step 5 - Download file
import polling2
try:
print(f'Downloading File from {file_url} ...')
bulkFile_response = polling2.poll(lambda: requests.get(file_url, verify= False),
step = 10,
poll_forever = True,
check_success= lambda r: r.status_code == 200)
except requests.exceptions.RequestException as exp:
print(f'Caught exception: {exp}')
Now you have downloaded the CFS bulk file stream in an application level. You can choose to save that file with whatever name you want.
If you need an actual file name of the file, it is available in S3 URL as follows:
https://XXXX.s3.amazonaws.com/XXX/YEAR/MONTH/DATE/{file_name}?x-request-Id={signature}
Examples:
- https://a206464-bulk-esg.s3.amazonaws.com/Bulk-ESG-Global-Symbology-Organization-v1/2023/11/26/Bulk-ESG-Global-Symbology-Organization-v1-Init-2023-11-26T16%3A04%3A11.525Z.jsonl.gz?x-request-Id=signature (an actual file name is Bulk-ESG-Global-Symbology-Organization-v1-Init-2023-11-26T16_04_11.525Z.jsonl.gz)
- https://a206464-bulk-custom.s3.amazonaws.com/GE-11328/2025/06/12/TM3_SIFMAIndex2025-06-12T14%3A00%3A00.000-04%3A00?x-request-Id=signature (an actual file name is TM3_SIFMAIndex2025-06-12T14_00_00.000-04_00)
The actual file name has been replace a _ (underscore) with %3A escape character, so an application needs to replace the escape character %3A with _ (underscore) character to get an actual file name.
# Save the file locally.
if bulkFile_response.status_code == 200: # HTTP Status 'OK'
zipfilename = file_url.split("?")[0].split("/")[-1].replace("%3A","_")
print('Download File Successfully')
open(zipfilename, 'wb').write(bulkFile_response.content)
print(f'{zipfilename} Saved')
else:
print(f'RDP APIs: Request file failure: {bulkFile_response.status_code} {bulkFile_response.reason}')
print(f'Text: {bulkFile_response.text}')
Result:
Receive File Successfull
Bulk-ESG-Global-Symbology-Organization-v1-Init-2023-11-26T16_04_11.525Z.jsonl.gz Saved
Now you get the CFS file that you can extract and read the file.
That covers how to download the CFS file via the RDP APIs.
Step 6: Refresh Token with RDP APIs
Before the session expires (based on the expires_in parameter, in seconds) , an application needs to send a Refresh Grant request message to RDP Authentication service to get a new access token before further request data from the platform.
The API requires the following access credential information:
- Refresh Token: The current Refresh Token value from the previous RDP Authentication call
- Client ID: This is also known as AppKey, and it is generated using an App key Generator. This unique identifier is defined for the user or application and is deemed confidential (not shared between users). The client_id parameter can be passed in the request body or as an “Authorization” request header that is encoded as base64.
- Grant Type refresh_token: This is for getting a new Access Token.
The HTTP request for the RDP APIs Authentication service is as follows:
POST /auth/oauth2/v1/token HTTP/1.1
Accept: */*
Content-Type: application/x-www-form-urlencoded
Host: api.refinitiv.com:443
Content-Length: XXX
refresh_token={current_refresh_token}
&grant_type=refresh_token
&client_id=RDP_APP_KEY
Once the authentication success, the function gets access_token, refresh_token, and expires_in from the RDP Auth service response message the same as the previous RDP Authentication call. An application must keep those value for the next Refresh Token call.
Caution: API Limit
The RDP Authentication service has the API limit described on the RDP APIs: Limitations and Guidelines for the RDP Authentication Service article. If the application flushes the authentication request messages (both password and refresh_token grant_type) beyond the limit, the account will be blocked by the API Gateway.
Python code:
#step 6 - Refreshing Token
# Send HTTP Request
auth_url = f'{RDP_HOST}/auth/oauth2/v1/token'
payload = f'grant_type=refresh_token&client_id={clientId}&refresh_token={refresh_token}'
auth_response = None
try:
auth_response = requests.post(auth_url,
headers = {'Content-Type':'application/x-www-form-urlencoded'},
data = payload,
auth = (clientId, '')
)
except requests.exceptions.RequestException as exp:
print(f'Caught exception: {exp}')
if auth_response.status_code == 200: # HTTP Status 'OK'
print('Refresh Token success')
access_token = auth_response.json()['access_token']
refresh_token = auth_response.json()['refresh_token']
expires_in = int(auth_response.json()['expires_in'])
if auth_response.status_code != 200:
print(f'RDP authentication failure: {auth_response.status_code} {auth_response.reason}')
print(f'Text: {auth_response.text}')
Step 7: Revoke Token to ending the session.
This revocation mechanism allows an application to invalidate its tokens if the end-user logs out, changes identity, or exits the respective application. Notifying the authorization server that the token is no longer needed allows the authorization server to clean up data associated with that token (e.g., session data) and the underlying authorization grant.
The API requires the following HTTP Header and Credential parameter information:
- Header:
- Authorization = Basic <App Key+":" in Base64 format>
- Body parameter
- token: The current Access Token value from the previous RDP Authentication call
Please be noticed
- The ":" string after the App Key.
- the space between the Basic and App Key+":" in Base64 values.
The HTTP request for the RDP APIs Authentication service is as follows:
POST /auth/oauth2/v1/revoke HTTP/1.1
Accept: */*
Content-Type: application/x-www-form-urlencoded
Host: api.refinitiv.com:443
Authorization: Basic <App Key+":" in Base64>
Content-Length: XXX
token={current_Access_token}
Note:
- Please be noticed ":" string after the App Key.
- The /revoke endpoint does not use the password in a Basic Authorization, so we need to send empty password in AppKey: format.
I am demonstrating with the Python requests library. We can use the auth(clientid,'')* to the requests.post function, and the library handles the base64 conversion for us.
If you are using other languages or libraries (like C#), you may need to convert the App-Key: to based64 ascii string by your self.
Python code:
#step 7 - Revoking Token
# Send HTTP Request
auth_url = f'{RDP_HOST}/auth/oauth2/v1/revoke'
payload = f'token={access_token}'
auth_response = None
try:
auth_response = requests.post(auth_url,
headers = {
'Content-Type':'application/x-www-form-urlencoded'
},
data = payload,
auth = (clientId, '')
)
except requests.exceptions.RequestException as exp:
print(f'Caught exception: {exp}')
if auth_response.status_code == 200: # HTTP Status 'OK'
print('Revoke Token success')
if auth_response.status_code != 200:
print(f'RDP authentication failure: {auth_response.status_code} {auth_response.reason}')
print(f'Text: {auth_response.text}')
That’s all I have to say about the CFS API workflow.
How to run the demo application
The first step is to unzip or download the example project folder into a directory of your choice, then set up Python or Postman environments based on your preference.
Run the demo application
1. Open Anaconda Prompt and go to the project's folder.
2. Run the following command in the Anaconda Prompt application to create a Conda environment named CFS for the project.
(base) $>conda create --name CFS python=3.10
3. Once the environment is created, activate a Conda CFS environment with this command in Anaconda Prompt.
(base) $>conda activate CFS
4. Run the following command to the dependencies in the CFS environment
(CFS) $>pip install -r requirements.txt
5. Once the dependencies installation process is success, run the following command to start the Jupyter Lab application.
(CFS) $>jupyter lab
6. Open a RDP-Generic-CFS.ipynb file and run each cell to learn the RDP CFS File workflow step by step.
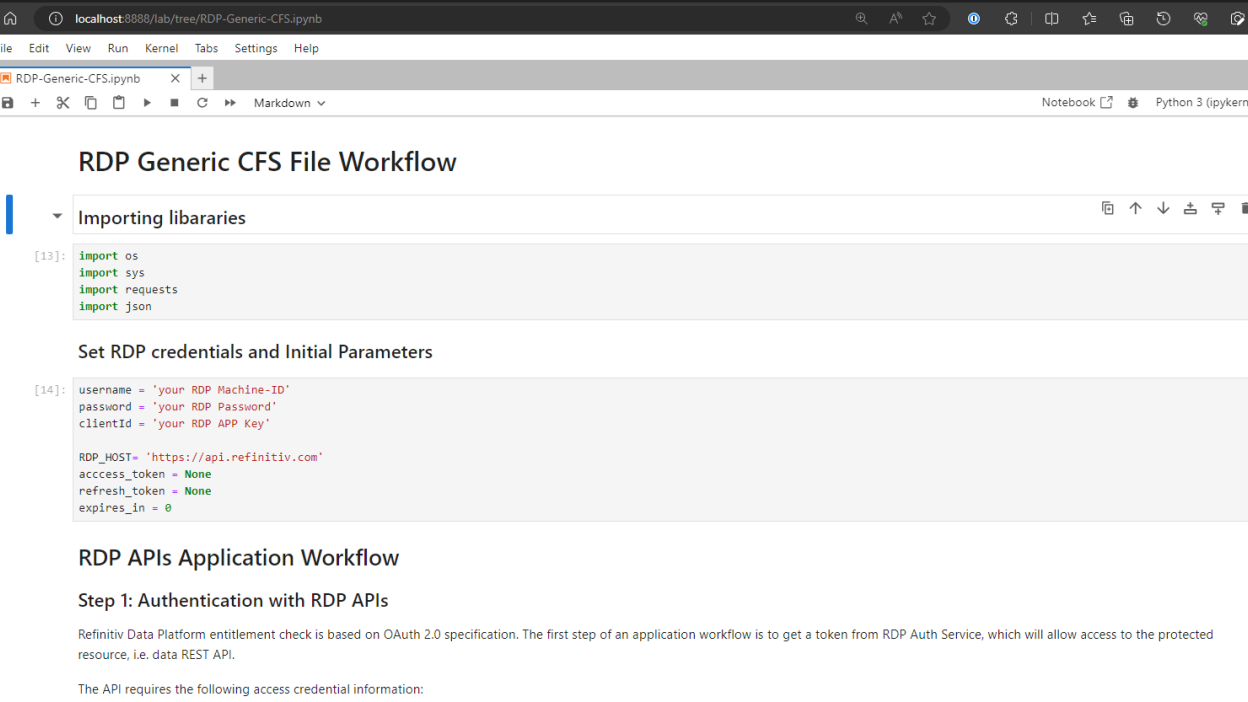
That completes how to run an example Jupyter Lab notebook application.
Run the Postman LSEG CFS API Workspace
Now let me turn to the Postman collection. The RDP CFS API Postman Workspace is a public workspace in Postman that demonstrates how to use CFS API. It contains the following collection and environment:
- RDP CFS API Collection: This collection contain all HTTP requests with the RDP CFS file API. The requests are in ordered from Step 1 to Step 5.
- RDP CFS API Environment: This environment contains all parameters consumers need for requesting data with the requests in RDP CFS API Collection (including the credential).
Users can fork these Postman items to their own workspaces. Please follow these five steps to fork the RDP CFS Postman Workspace to a Postman workspace.
1. Create a new Postman workspace
Firstly, open the Postman application and then sign in to the Postman and create a new workspace.
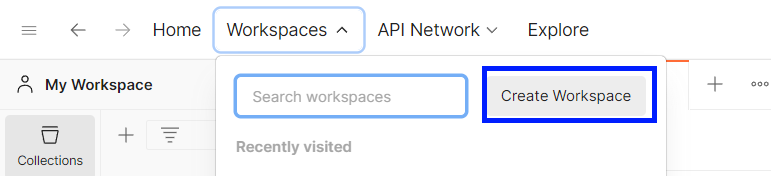
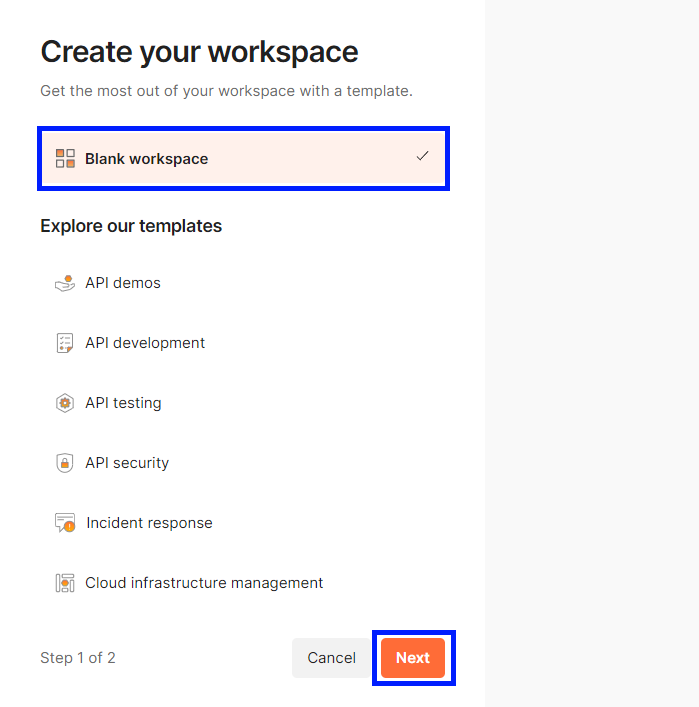
Choose a Blank workspace, and click the Next button.
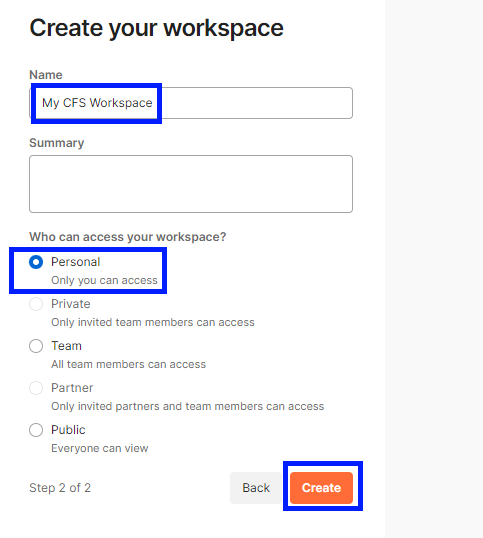
Set a workspace name, such as “My CFS Workspace”, set the Visibility to Personal, and then click the Create button.
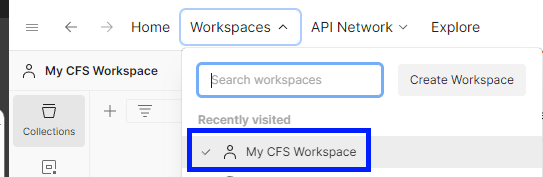
The new workspace will appear on the list.
2. Open the LSEG CFS API Workspace
The LSEG CFS API Workspace is in the public workspace so you can search it in Postman by clicking on “Search Postman”.
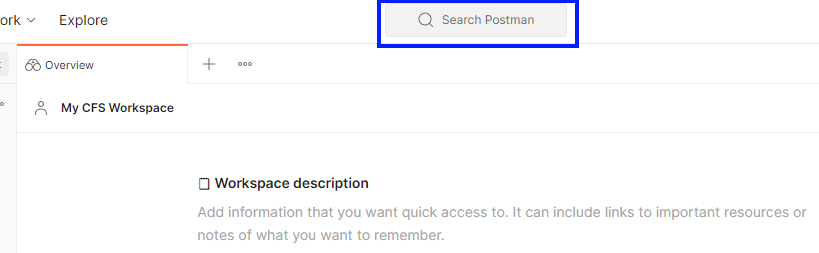
And then, enter “LSEG CFS API”.
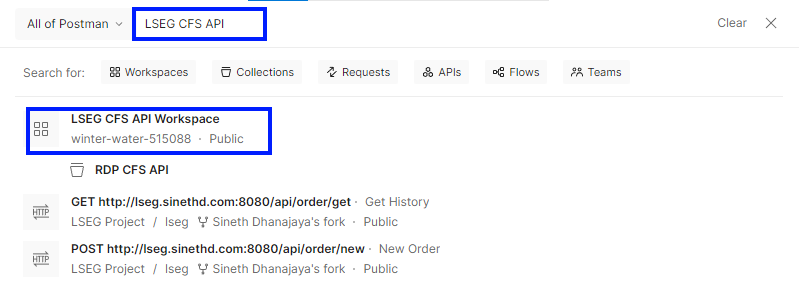
Click on the LSEG CFS API to open the workspace.

This LSEG CFS API workspace will be added to the workspace list.
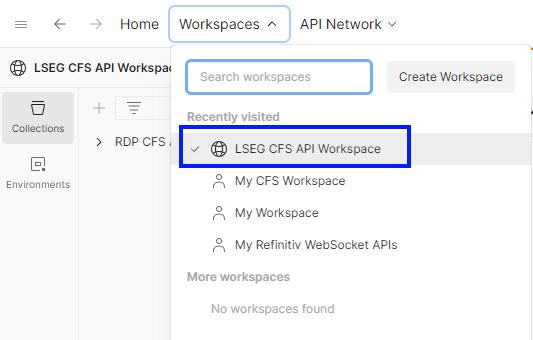
3. Fork the RDP CFS API Collection
Select the LSEG CFS API workspace from the workspace list, and then select “...” menu of the RDP CFS API collection and choose the "Create a fork" command to fork this collection.
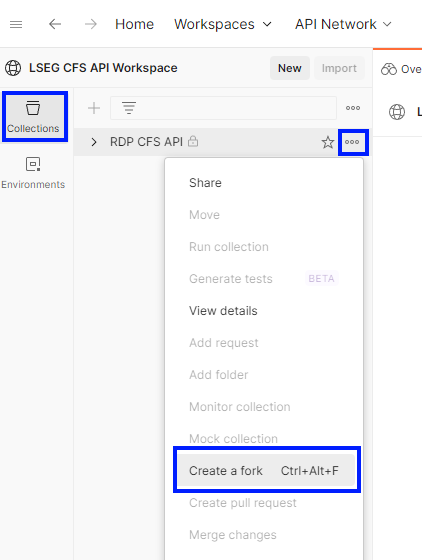
Then, enter the fork label, select the workspace (My CFS Workspace) created in the first step, uncheck “Watch original collection”, and then click on the Fork Collection button.
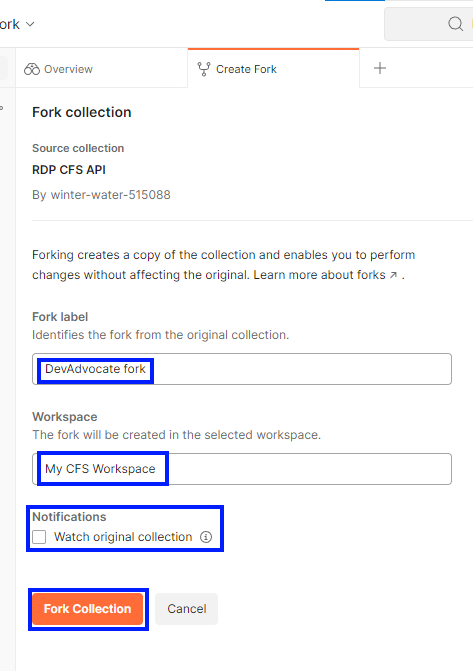
The forked collection will be created in the selected workspace.
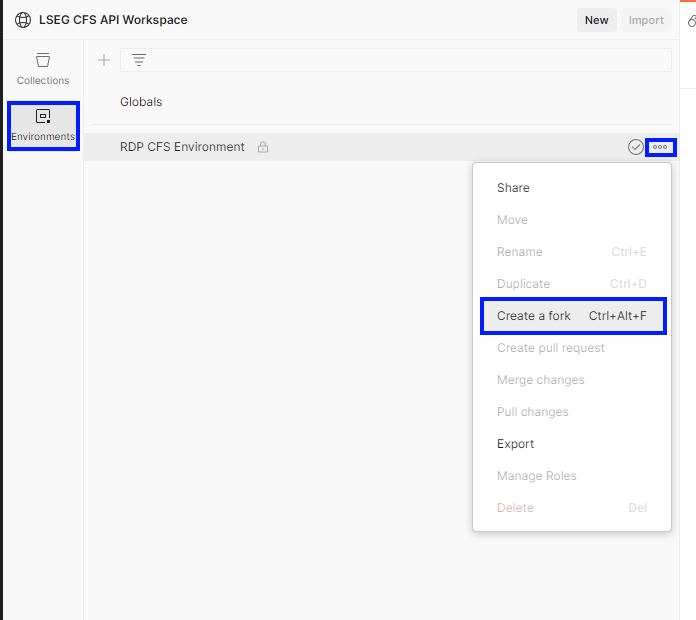
4. Fork the Environment
Select the LSEG CFS API workspace from the workspace list, and then select “...” menu of the RDP CFS Environment and choose the "Create a fork" command to fork this environment.
Then, enter the fork label, select the workspace (My CFS Workspace) created in the first step, and then click on the Fork Environment button.
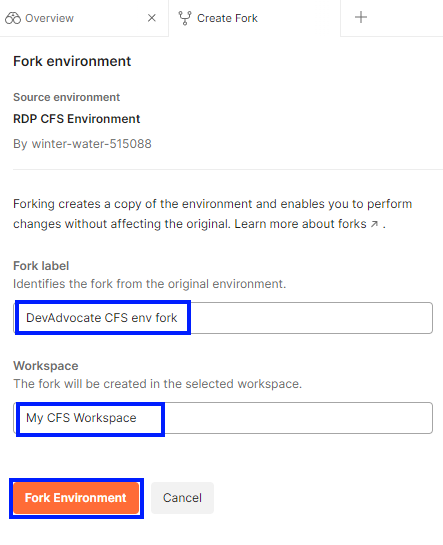
The forked environment will be created in the selected workspace. Input the USERNAME, PASSWORD, APP_KEY, and BUCKET_NAME variables with your RDP credential detail.
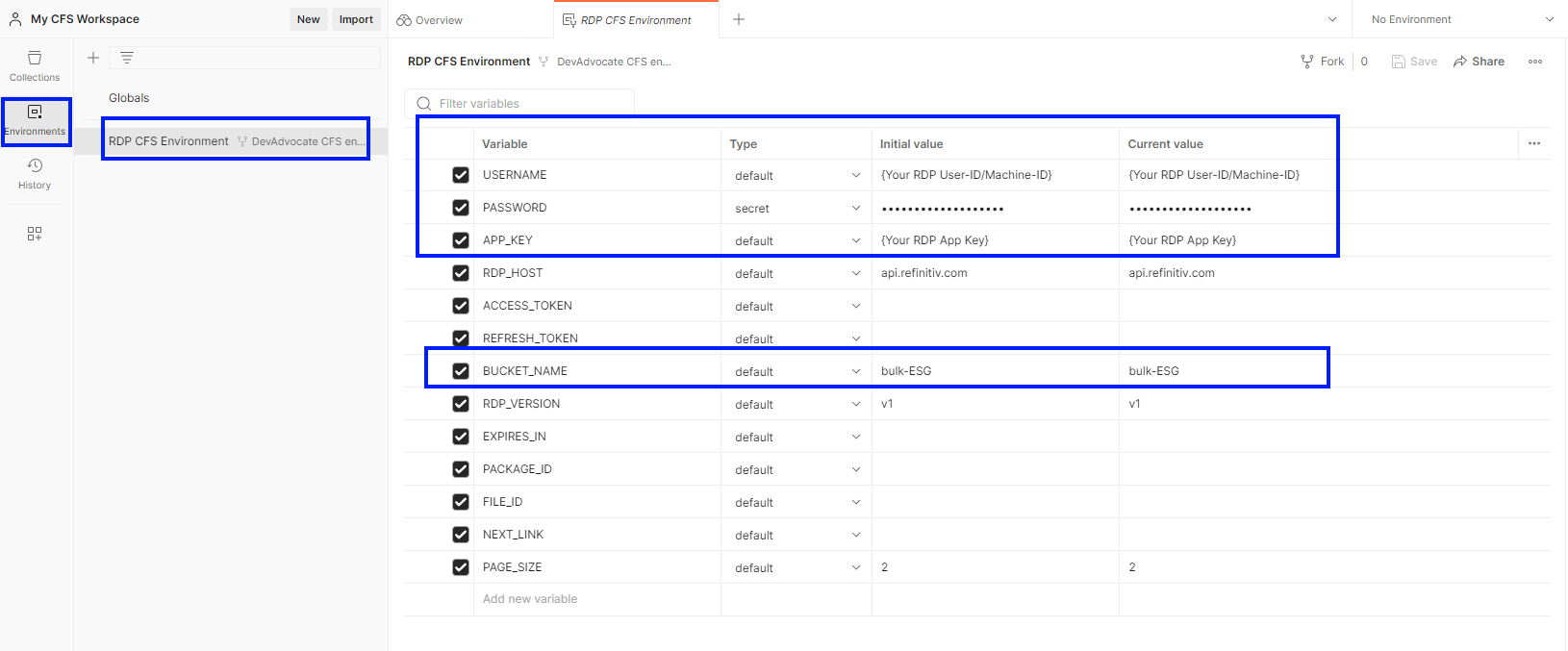
5. Running Postman Collection
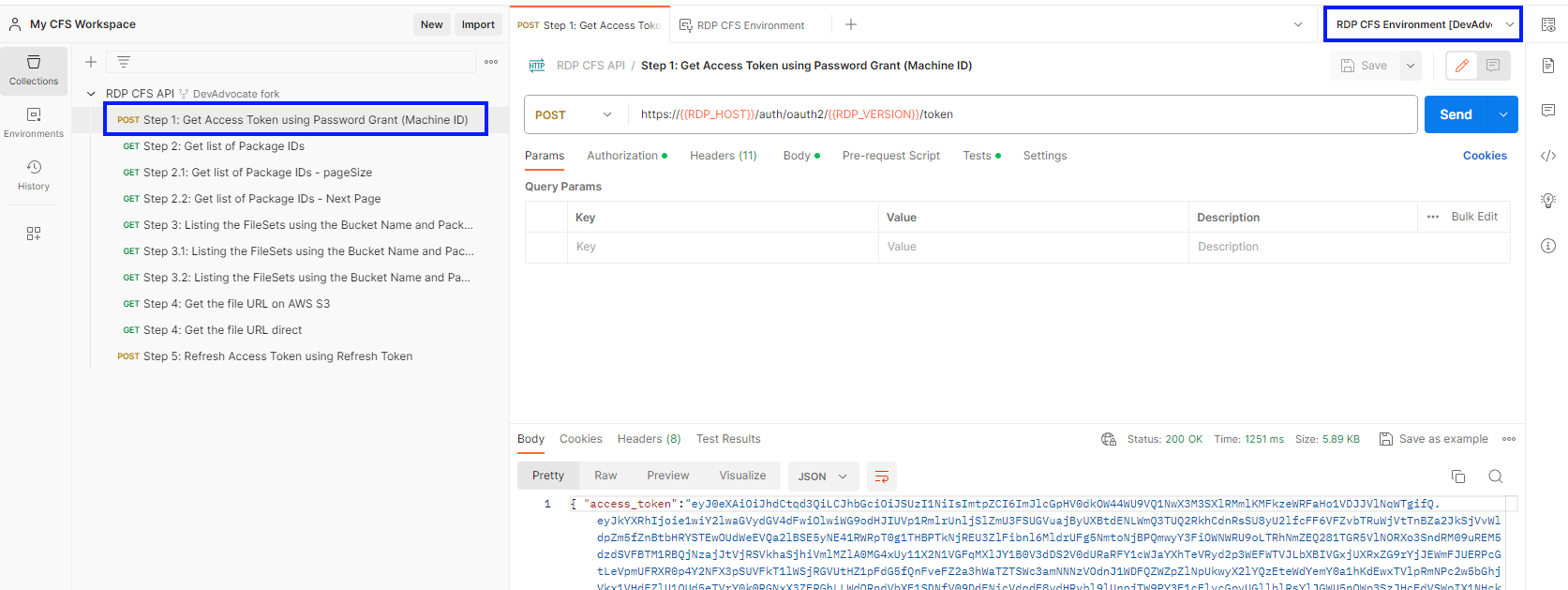
The first step is run the "Step 1" Get Access Token using Password Grant (Machine ID)" request, please make sure that the environment on the top right corner is pointed to the RDP CFS Environment.
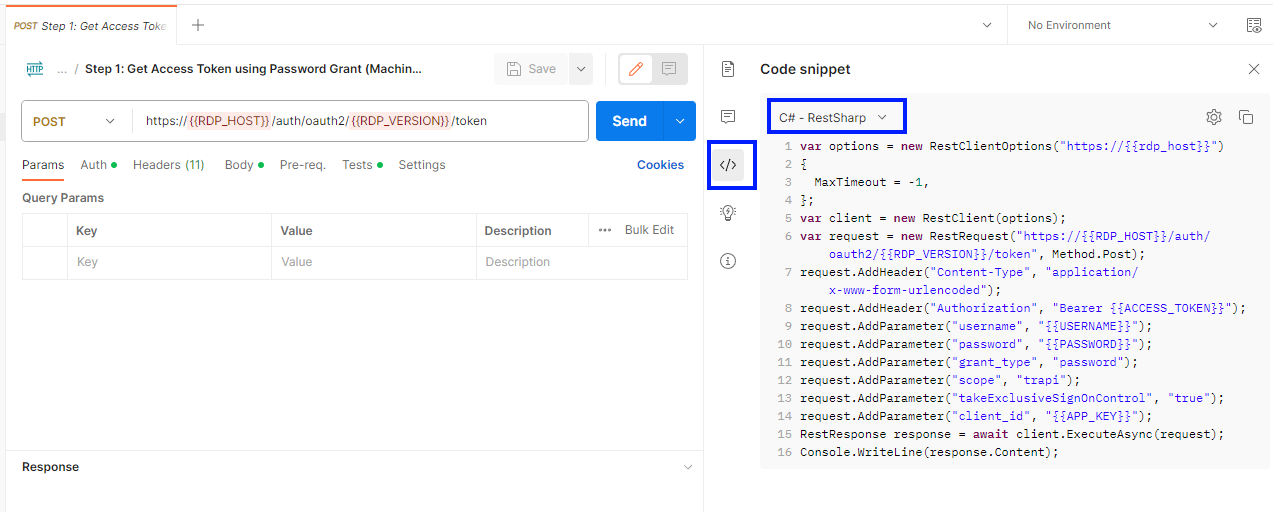
You can generate the source code from this Postman request by clicking the </> button and choose prefer language.
Once the Once authentication is successful, run the requests from step 2 to step 4
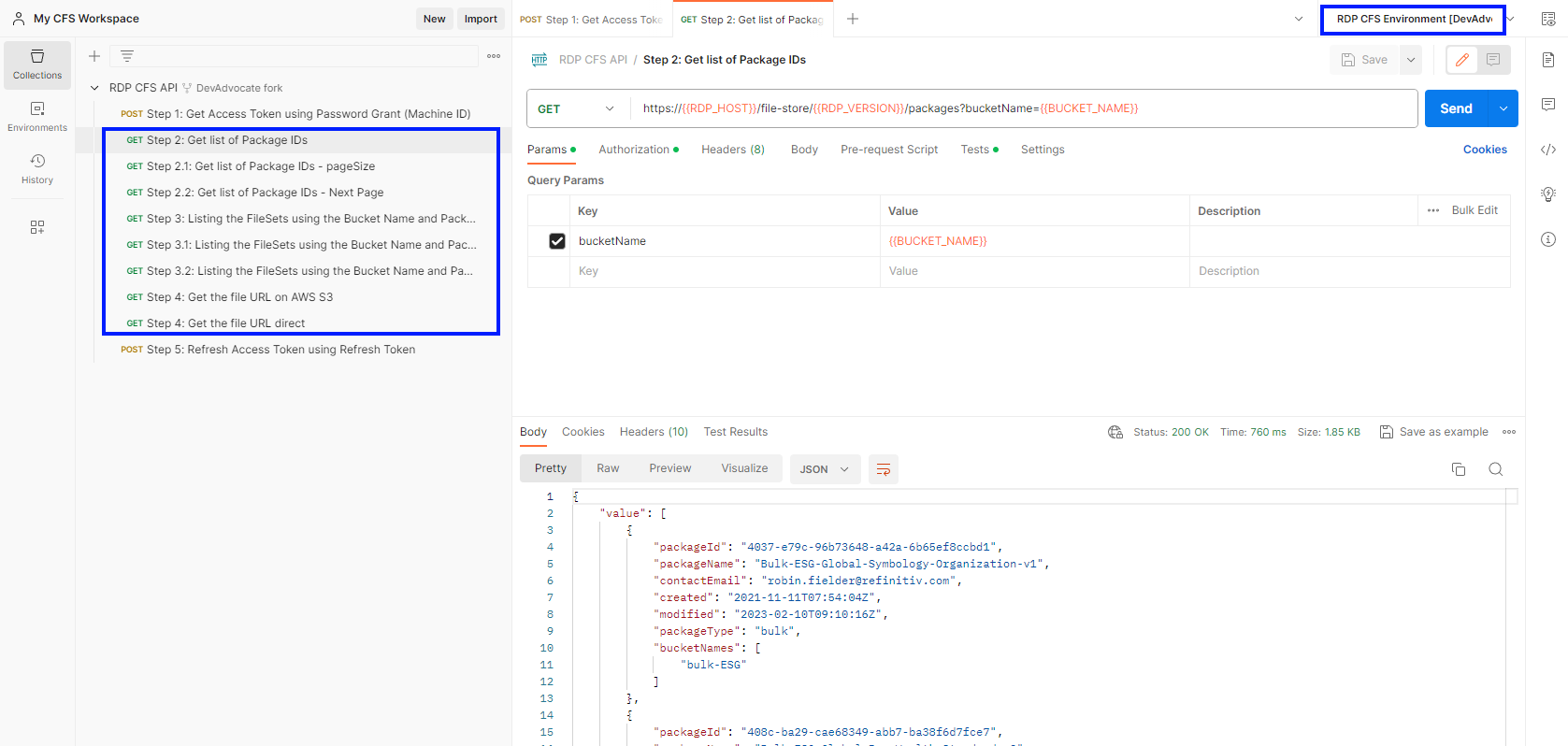
You can generate the source code from these Postman requests by clicking the </> button and choose prefer language on each request too.
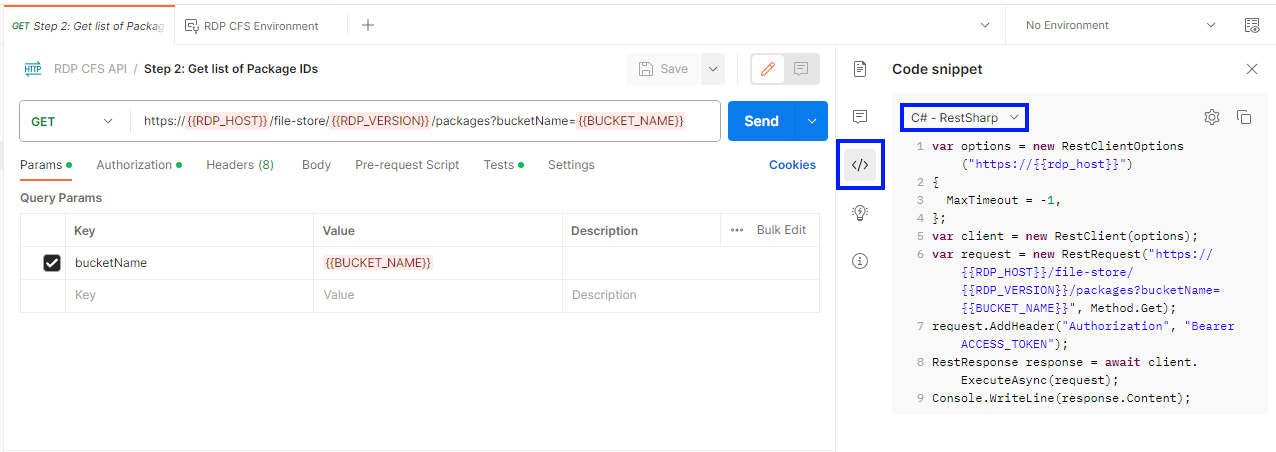
If the Access Token is expired, the RDP CFS API requests return "token expired" error message as follows:
You need to refresh the Access Token by requesting "Step 5: Refresh Access Token using Refresh Token", then you can re-run the requests in step 2-4 again.
That covers how to run an example Postman collection.
Next Steps
That brings me to the end of this CFS API workflow project. The CFS API is a powerful API that allows developers to download the content file dynamically via a straightforward sequence of HTTP RESTful API calls. The demonstration code is written in Python but the concept of the API calls steps are the same for other programming languages.
At the same time, the Delivery Platform (RDP) APIs provide various LSEG data and content for developers via an easy-to-use Web-based API. The APIs are easy to integrate into any application and platform that supports the HTTP protocol and JSON message format.
You may interested in the following resources for more detail about the CFS data usage:
- How to use File Notification Message Distribution with the Client File Store (CFS) Service article.
- Find environmental footprint of your bond portfolio article
- RDP APIs Green Revenues CFS file Workflow - a dedicate Green Revenue CFS workflow
- RDP APIs ESG CFS file Workflow - a dedicate ESG CFS workflow
And much more on the Developer Portal website.
References
For further details, please check out the following resources:
- Delivery Platform (RDP) APIs page on the LSEG Developer Community website.
- RDP APIs Playground page.
- RDP APIs: Introduction to the Request-Response API.
- RDP APIs: Authorization - All about tokens.
- Limitations and Guidelines for the RDP Authentication Service article.
- Getting Started with Data Platform article.
- CFS API User Guide.
For any questions related to Delivery Platform APIs, please use the RDP APIs Forum on the Developers Community Q&A page.
Get In Touch
Related Articles
-
A Step By Step Guide for Getting Municipal Market Monitor (TM3) Bulk File Using CSharp
-
Limitations and Guidelines for the RDP Authentication Service
-
Getting Started with Delivery Platform
-
Find environmental footprint of your bond portfolio
-
Introduction to Client File Store (CFS) - Python
-
How to use File Notification Message Distribution with the CFS Service
Related APIs
Source Code
Request Free Trial
Call your local sales team
Americas
All countries (toll free): +1 800 427 7570
Brazil: +55 11 47009629
Argentina: +54 11 53546700
Chile: +56 2 24838932
Mexico: +52 55 80005740
Colombia: +57 1 4419404
Europe, Middle East, Africa
Europe: +442045302020
Africa: +27 11 775 3188
Middle East & North Africa: 800035704182
Asia Pacific (Sub-Regional)
Australia & Pacific Islands: +612 8066 2494
China mainland: +86 10 6627 1095
Hong Kong & Macau: +852 3077 5499
India, Bangladesh, Nepal, Maldives & Sri Lanka:
+91 22 6180 7525
Indonesia: +622150960350
Japan: +813 6743 6515
Korea: +822 3478 4303
Malaysia & Brunei: +603 7 724 0502
New Zealand: +64 9913 6203
Philippines: 180 089 094 050 (Globe) or
180 014 410 639 (PLDT)
Singapore and all non-listed ASEAN Countries:
+65 6415 5484
Taiwan: +886 2 7734 4677
Thailand & Laos: +662 844 9576