
Article
Leveraging Parallel Programming in Python for Optimized Server Data Retrieval


Overview
Concurrency and parallelism are two topics which can be challenging for beginners and sometimes even misunderstood by professionals. They are often used in relation to multi-threaded or parallel programming. Both may seem to refer to the same or similar concepts on the surface. However, they are typically used to specify different types of multi-threaded behavior.
This article will provide you a deep understanding on those topics, how they can be used in python and finally some practical samples using the Refinitiv Data Library.
Getting Started
For this analysis, we plan to utilize content available within LSEG's comprehensive data set. To programmatically access this content, the article assumes the user has a license for LSEG's Workspace desktop application using the Refinitiv Data (RD) Library for Python. However, the concepts can still be applied for users licensed to access data directly from the Refinitiv Data Platform.
Learn more
To learn more about the Refinitiv Data Library for Python please join the Refinitiv Developer Community. By registering and logging into the Refinitiv Developer Community portal you will have free access to a number of learning materials like Quick Start guides, Tutorials, Documentation and much more.
Getting Help and Support
If you have any questions regarding using the API, please post them on the LSEG Data Q&A Forum. The LSEG Developer Community will be happy to help.
Terminology
- CPU: Central Processing Unit – hardware used to execute code
- OS: Operation System – acts as the interface between your code and hardware to schedule tasks
- Process: A program as it is being executed
- Thread: A sub-task within a Process that can be scheduled to be executed within the CPU
- Mutex: Mutual Exclusion Object prevents multiple threads from accessing the same resource
- GIL: Global Interpreter Lock is a mutex that allows only one thread to execute at any point
Threading vs Multiprocessing
| Threading | Multiprocessing |
|---|---|
| A new thread is spawned within the existing process | A new process is started independent from the first process. |
Starting a thread is faster than starting a process. |
Starting a process is slower than starting a thread. |
Memory is shared between all threads. |
Memory is not shared between processes. |
Mutexes often necessary to control access to shared data. |
Mutexes not necessary (unless threading in the new process) |
One GIL (Global Interpreter Lock) for all threads (in Python) |
One GIL (Global interpreter Lock) for each process (in Python) |
Concurrency
Concurrency means that an application is running and managing multiple computations seemingly at the same time. Concurrency execution is often associated with a single processing unit or specifically, a single-core CPU. It is also associated with popular, single-threaded, scripting languages such as Python, JavaScript, TypeScript and R. However, these programming languages do provide the ability to execute multiple threads concurrently. Concurrency is achieved through the execution of multiple tasks one at a time but giving the appearance of executing tasks simultaneously. When considering performance, concurrency does shine when the multiple tasks are I/O-based. That is, if the tasks involve the execution of requests on a server, the processing on the server can run in parallel resulting in better performance. However, if the multiple tasks are heavy on CPU-based computations, concurrency can be less performant due to the nature of single execution coupled with the overhead of context switching.
This is illustrated in the image below.
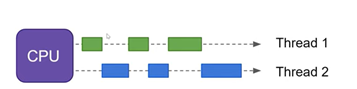
Whether we're working with a single-core CPU or dealing with a single-threaded language such as Python and its Global Interpreter Lock (GIL) the above provides a basic visual of how the execution of multiple threads are shared.
Parallelism
Parallelism means that an application is running and managing multiple computations simultaneously. Parallel execution is often associated with multi-core processors/CPUs as well as its use in popular, multi-threaded, programming languages such as C++, Java and C#/.Net. Parallelism is achieved through the execution of multiple tasks simultaneously or in parallel where you can truly do more than one thing at a time. When considering performance, parallelism shines in both I/O-based and CPU computations because of it ability to schedule work across multiple cores and threads executing simultaneously. It is also worth noting that while some single-threaded programming languages, like Python, cannot execute threads or tasks simultaneously, they do offer the ability to spawn multiple child processes through its multiprocessing module allowing for simultaneous execution across multiple GILs.
This is illustrated in the image below.
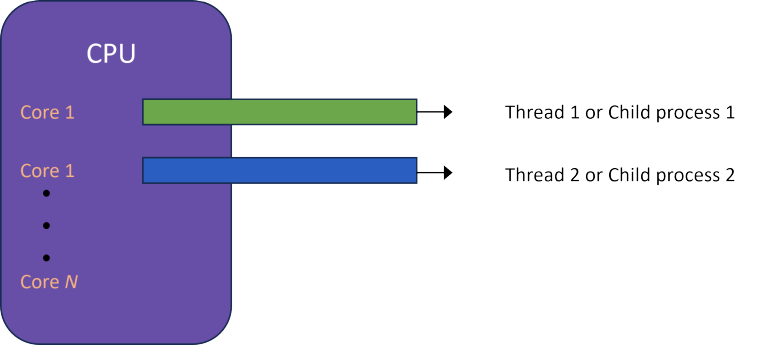
When working with multi-core CPUs, there is the potential to execute multiple tasks simultaneously. Although single-threaded scripting languages like Python are constrained by the Global Interpreter Lock (GIL) to execute only one task at a time, the language does provide the ability to launch multiple child processes and therefore multiple GILs executing tasks simultaneously.
Multiprocessing in Python
When a big task must be executed and will take a large amount of execution time, it makes sense to break this big task into subtasks. If those subtasks can be executed in parallel or concurrently, then the execution time may be reduced. Fortunately, python allows to do so very easily by providing thread pool-based execution with the ThreadPoolExecutor class and process pool-based execution with the ProcessPoolExecutor class. Both classes provides methods to execute calls asynchronously.
ThreadPoolExecutor: This executor uses a pool of at most max_workers to execute calls asynchronously. It is defined like this:
class concurrent.futures.ThreadPoolExecutor(max_workers=None, thread_name_prefix='', initializer=None, initargs=())
from concurrent.futures import ThreadPoolExecutor
...
def retrieve_data(params):
# Perform data retrieval using the params
return data
with ThreadPoolExecutor(max_workers=None) as executor:
# Code setup
...
for result in executor.map(retrieve_data, [p1, p2, .., pN])
# Process final results
Inside the executor context, you use the executor.map() function to apply the retrieve_data function to each element in the list [p1, p2, .., pN]. Each element in the list is treated as a separate task and is executed in a separate thread. The map() function returns an iterator that yields the results of the function as they become available. This is useful when the function is I/O bound and can run concurrently.
All threads enqueued to ThreadPoolExecutor will be joined before the interpreter can exit. If max_workers is None or not given, it will default to the number of processors or cores on the machine, multiplied by 5, assuming that ThreadPoolExecutor is often used to overlap I/O instead of CPU computations. ThreadPoolExecutor is the implementation of concurrent task execution.
ProcessPoolExecutor: This executor uses a pool of processes to execute calls asynchronously. It is defined like this:
class concurrent.futures.ProcessPoolExecutor(max_workers=None, mp_context=None, initializer=None, initargs=(), max_tasks_per_child=None)
from concurrent.futures import ProcessPoolExecutor
...
def retrieve_data(params):
# Perform data retrieval using the params
return data
with ProcessPoolExecutor(max_workers=None) as executor:
# Code setup
...
for result in executor.map(retrieve_data, [p1, p2, .., pN])
# Process final results
Inside the executor context, you use the executor.map() function to apply the retrieve_data function to each element in the list [p1, p2, .., pN]. Each element in the list is treated as a separate task and is executed in a separate process. The map() function returns an iterator that yields the results of the function as they become available. This is useful when the function is CPU-bound and can benefit from parallel execution.
If max_workers is None or not given, it will default to the number of processors on the machine. If max_workers is less than or equal to 0, then a ValueError will be raised. On Windows, max_workers must be less than or equal to 61. If it is not then ValueError will be raised. If max_workers is None, then the default chosen will be at most 61, even if more processors are available. mp_context can be a multiprocessing context or None. It will be used to launch the workers. If mp_context is None or not given, the default multiprocessing context is used. Using this mechanism when building pure Python-based applications, the __main__ module must be importable by worker subprocesses. ProcessPoolExecutor is the implementation of the pure parallel execution with the constraint that threads are replaced by processes.
Applications using the get_data() functionality within the data Library
To illustrate the above concepts, we will use the Data Library for Python and the popular get_data() data retrieval mechanism.
Use Case: A screening operation has brought a huge number of instruments. Several pricing data, fundamental data must be retrieved on every single stock and downloaded in an Excel sheet.
The screening results will be simulated with a file containing a huge list of RIC codes. The pricing data, the fundamental data will be retrieved through a column containing the fields to be requested.
We will apply the ‘normal’ or 'native' processing i.e synchronous process, the multi-threading, the multiprocessing and a hybrid of these two, then measure of the execution time. The tests will be done in Codebook environment which has the following characteristics:
- 2 Gb Hard Disk
- 8 Gb Ram
- CPU with 2 physical cores
Code and description
For the purposes of testing and to capture the nuances of multiple use cases, we have created a processing class called DataProcessor that performs data retrieval using the multitasking capabilities outlined above. Defined within the data_processing.py module, the class supports the following capabilities:
- native
Native library support with no explicit task intervention - a single task is used to request data
- thread
Utilizes the threading capabilities (ThreadPoolExecutor) to schedule multiple tasks to be executed concurrently - process
Utilizes the processing capabilities (ProcessPoolExecutor) to spawn multiple child processes to be executed in parallel - hybrid
A combination of 'thread' and 'process' to spawn multiple child processes where each process will schedule multiple tasks
Code setup
To easily follow along with the general processing, we've setup the code to simply import our data processing class, defined our fields of interest and loaded our instruments (RICs) used to test our data retrieval. To begin, we'll start with our imports:
# Basic Python libraries
import time
# The main processing class built to compare the different approaches
from data_processor import DataProcessor
Next, we setup the general constants used throughout our tests. Specifically the size of the batch of requests and the fields we wish to extract from the back-end.
# Maximum number of items a request to get data can retrieve.
MAX_ITEMS_PER_REQUEST_FOR_GET_DATA = 7500
# fields to request
data_columns = ["TR.CommonName", "TR.ISINCode", "TR.PriceClose.Currency", "TR.HeadquartersCountry",
"TR.TRBCEconomicSector", "TR.TRBCBusinessSector", "TR.PriceMainIndexRIC", "TR.FreeFloat",
"TR.SharesOutstanding", "TR.CompanyMarketCapitalization",
"TR.IssuerRating(IssuerRatingSrc=SPI,RatingScope=DMS)",
"TR.IssuerRating(IssuerRatingSrc=MIS,RatingScope=DMS)",
"TR.IssuerRating(IssuerRatingSrc=FDL,RatingScope=DMS)",
"TR.PriceClose", "TR.PricePctChg1D", "TR.Volatility5D", "TR.Volatility10D",
"TR.Volatility30D", "TR.RSISimple14D", "TR.WACCBeta", "TR.BetaFiveYear",
"TR.DivAnnouncementDate", "TR.DivExDate", "TR.DivPayDate", "TR.DivAdjustedGross",
"TR.DivAdjustedNet", "TR.RelValPECOmponent", "TR.RelValEVEBITDACOmponent",
"TR.RelValDividendYieldCOmponent", "TR.RelValEVSalesCOmponent",
"TR.RelValPriceCashFlowCOmponent", "TR.RelValPriceBookCOmponent", "TR.RecMean",
"TR.RecLabel", "TR.RevenueSmartEst", "TR.RevenueMean", "TR.RevenueMedian",
"TR.NetprofitSmartEst", "TR.NetProfitMean", "TR.NetProfitMedian", "TR.DPSSmartEst",
"TR.DPSMean", "TR.DPSMedian", "TR.EpsSmartEst", "TR.EPSMean", "TR.EPSMedian",
"TR.PriceSalesRatioSmartEst", "TR.PriceSalesRatioMean", "TR.PriceSalesRatioMedian",
"TR.PriceMoRegionRank", "TR.SICtryRank", "TR.EQCountryListRank1_Latest",
"TR.CreditComboRegionRank", "TR.CreditRatioRegionRank", "TR.CreditStructRegRank",
"TR.CreditTextRegRank", "TR.TRESGScoreGrade(Period=FY0)",
"TR.TRESGCScoreGrade(Period=FY0)", "TR.TRESGCControversiesScoreGrade(Period=FY0)"
]
To begin our processing, lets create an instance of our data processor. The DataProcessor is responsible for measuring all our tests comparing the different mechanisms in an effort to find the appropriate parameters using concurrent modules within Python.
*Note: The data_processor.py file utilizes both the ThreadPoolExecutor and ProcessPoolExecutor using the basic structure outlined above. It is left to the reader to peruse the specific details for a deeper understanding.
# Create our processor - opens a session
processor = DataProcessor()
As our last code setup, load our instrument codes (RICs):
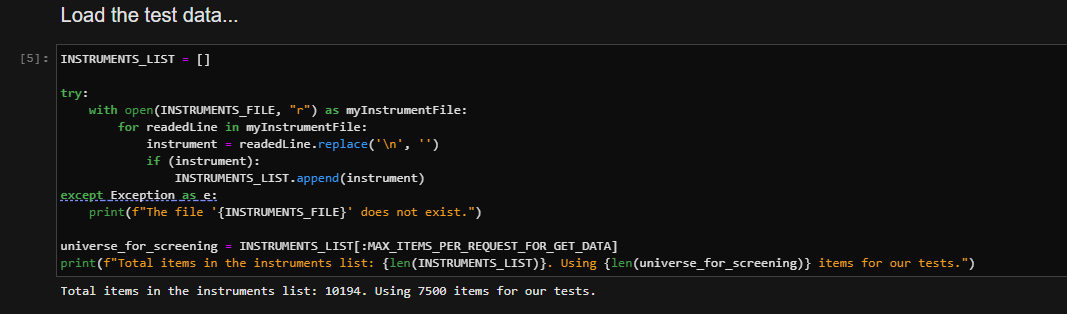
Run the tests
Once the universe for screening has been retrieved, it is now possible to run using the four approaches:
- The normal or native approach
- The pool of threads approach
- The pool of processes approach
- A hybrid of threads and processes
Normal approach
In the normal approach, the entire universe is retrieved by using the rd.get_data() of the RD library. This is performed by executing the internal_get_data function defined within the DataProcessor module. A timer allows to measure the whole execution time of this function.

With this test, we have sent the entire batch of items on the main thread for execution.
Multi-threading approach
In the multi-threading approach, the entire universe is retrieved by using the function threadpoolExecutor_rd.get_data() defined within the DataProcessor module. A timer allows to measure the whole execution time of this function.
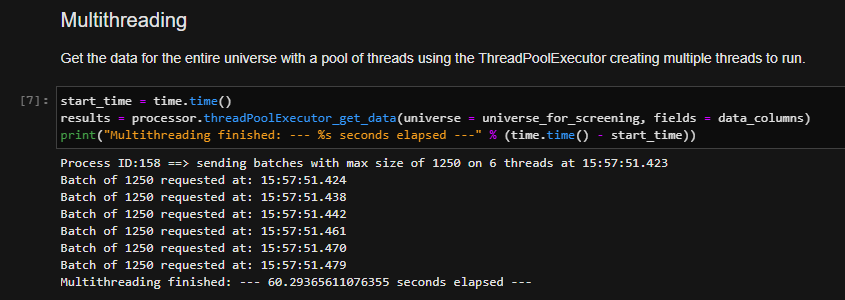
The above execution determines the number of threads to distribute the work based on the available number of processors on the target machine. You can see we have determined that we can distribute the load across 6 threads each carrying an equivalent batch size. Overall, we can immediately see improvements in the time of retrieval. Because our data requests are I/O-based, we can potentially achieve better overall performance.
Multiprocessing approach
In the multiprocessing approach, the entire universe is retrieved by using the function processPoolExecutor_get_data() defined within the DataProcessor module. A timer allows to measure the whole execution time of this function.
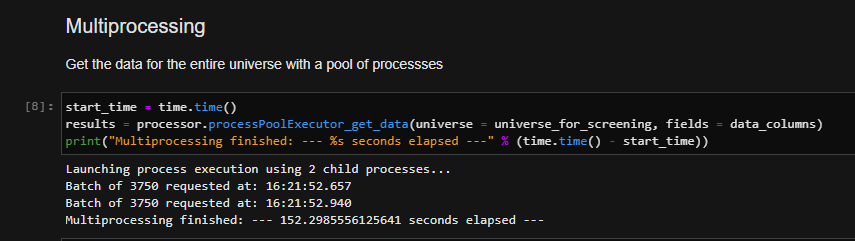
Here, we are distributing the entire batch of items within multiple child processes. When working with the Data Library for Python, each child process must establish a separate session into the platform. Because of this, the overall time will be affected due to the overhead of the connection mechanism. However, each process is truly running in parallel and can be managed simultaneously. While this may improve overall time, in many cases, the number of processes and the overhead of the connection mechanism may outweigh the benefits of distributing load across multiple processes. This approach may need additional tuning if there is a possibility of improvement.
*Note: The focus of this article is strictly running your requests within the desktop. However, this does not preclude the possibility of running the same type of requests directly to the platform. If this were the case, there is the issue of license management. That is, the present license ID mechanism when connecting into the platform is each ID can control only 1 session. If another session using the same ID attempts to connect into the platform, this will invalidate the existing license thus introduces issues with token refreshing for long-lived applications. It is encouraged to utilize the threading capabilities of Python to achieve performance boosts.
Hybrid approach
In the hybrid approach, the entire universe is retrieved by using the function hybridPoolExecutor_get_data() defined within the DataProcessor module. A timer allows to measure the whole execution time of this function.
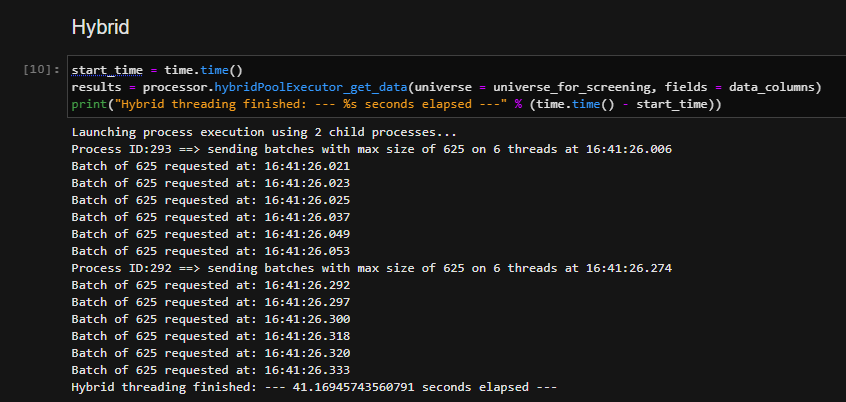
In our final test, we can see we performed well when balancing multiple child processes but leveraging the threading capabilities of Python. With this approach, as before, we chose 2 child processes but for each, distributed load across multiple threads in an attempt to offload the right balance of processing within our servers. You can see we achieved the best results.
*Note: As mentioned with our previous tests, we are facing the licensing challenges if we attempt to perform process-based tests when connecting to the platform. It is best to utilize the threading models instead.
Analyze the results
With these four approaches, we were able to pull a huge amount of data from Workspace. While results may slightly differ across multiple runs, largely due to general load on the servers, we can see there is an opportunity to take advantage of the concurrent modules offered within Python. Depending on your specific requirements, you may have varying results.
Because of this, we have built and packaged a useful utility that users can run on the command line that provides the ability to easily specify the type of algorithm to choose, the size of the overall batch, the minimum batch size within each thread, the number of child processes etc. The goal is to allow users to consider, test and take advantage of their own specific hardware and what it has to offer.
The next section will provide a brief overview of this test utility.
Testing Utility - tune criteria to suit your hardware
Packaged with the project contains the testing file called: Parallel_Programming.py. This is a self-contained program that utilizes the same DataProcessor class we used in the above tests but offers a simple command-line and menu facility to test specific criteria. In the above tests, we executed within a Jupyter Notebook module, using default parameters defined within the DataProcessor class. However, the methods offered within the DataProcessor class provide the ability to override default values. The tests will be done on a Windows laptop which has the following characteristics:
- 500 Gb Hard Disk
- 32 Gb Ram
- CPU with 8 physical cores; 16 logical processors (hyper-threading)
Launching the application from the command line:
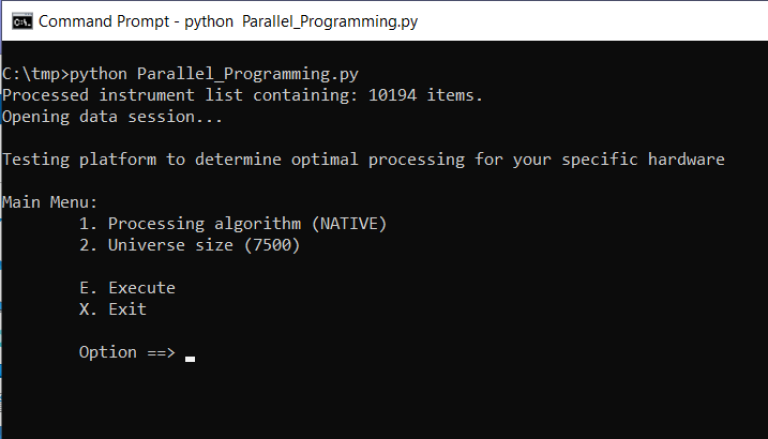
The tool presents a simple menu providing users the opportunity to select specific testing criteria. From choosing the algorithm to changing batch sizes in an effort to maximize performance. For example, if we choose to select the approach where we intend on optimizing performance using the threading capabilities within Python, let's select that algorithm:
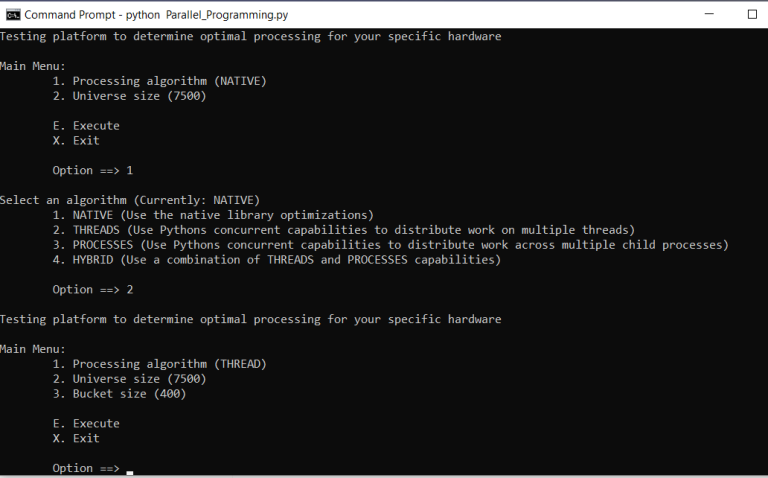
From here, we can see the preferred batch size for each thread. If we were to execute from here, we would generate ~19 threads. However, we can override this selection by increasing the batch size. For example, if we select each thread batch to be 1000, we can see how the request is generated:
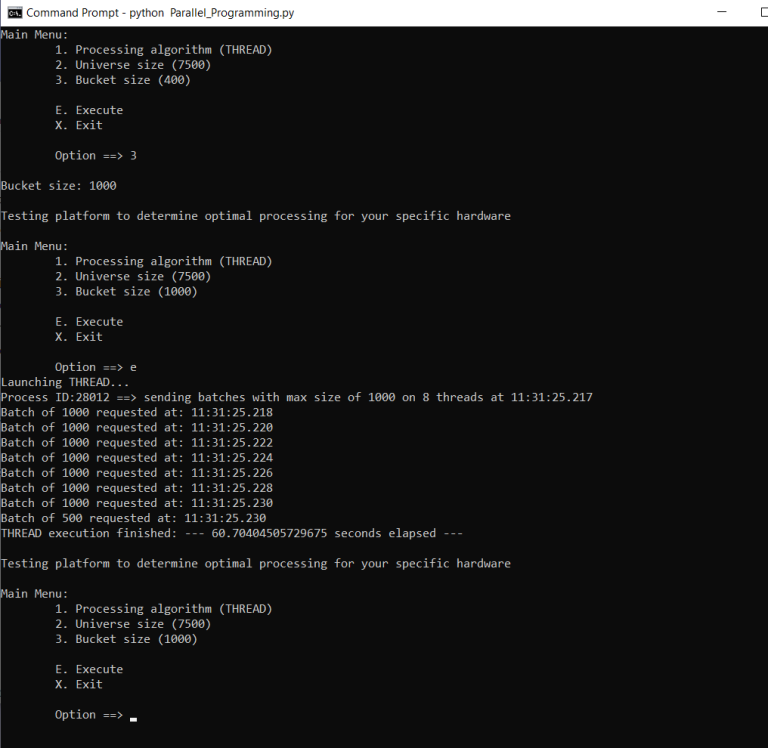
When executing, you can see how the distribution of threads has been created. From here, you can attempt to find the sweet spot by adjusting some of the numbers. If you feel the threading approach may not yield desired results, you can try a hybrid approach. For example, we randomly tried to execute threads on 3 child processes using the same batch size of 1000.
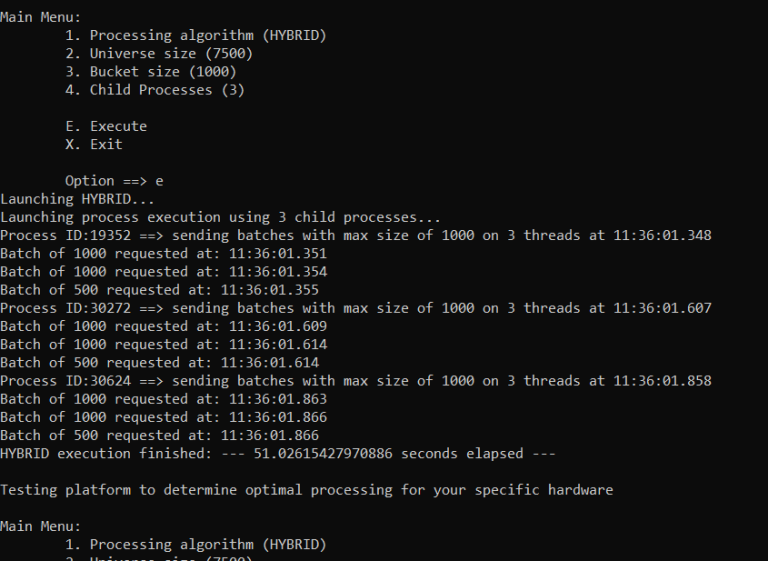
After setting and executing, we can see for this run, we had a slight performance boost. The point being, we can easily test multiple scenarios based on specific requirements and machine configuration.
Conclusion
When analyzing the execution time of getting data, we note the following points:
- Using the thread-pool or hybrid approach gives the best results
- Using the multiprocess approach generally gives poor results because starting a process is slower and each process requires the overhead of session connection establishment
- In some cases, depending on the number of child processes, the multiprocess approach can be worse than the normal behavior
Results, in general, largely depend on the type of underlying data request; the number of fields and the number of instruments requested. The goal is to provide some useful mechanisms to allow users to optimize requests. In CPython, threads execute concurrently but not in parallel with respect to Python bytecode: multiple threads may be active and scheduled, but only one executes Python code at any instant due to the GIL, so CPU‑bound Python code cannot utilize multiple cores within a single process. However, this limitation may not be impactful due to the nature of the requests. That is, the types of requests we're executing are all I/O-based. While the GIL can only execute one task at a time, most of the execution for each task is performed on the server and the only job of the GIL is to flip between each task to monitor and wait for the I/O operation to complete.
Finally, with the packaged testing utility, users now can easily tune and play with the configuration options available within the Python concurrent libraries. This will greatly increase your productivity and hopefully enable you to improve performance.
- Register or Log in to applaud this article
- Let the author know how much this article helped you