
This article is intended for software users who developing Refinitiv Real-Time SDK (formerly known as Elektron SDK) - Java consumer i.e. Enterprise Message API (EMA, formerly known as Elektron Message API), ValueAdd Enterprise Transport API (ValueAdd ETA) or Enterprise Transport API (ETA, formerly known as Elektron Transport API) Java consumer. It is going to explain how to parse page-based data using these APIs. Anyway, the general concepts outlined below could be applied to any of real-time streaming APIs i.e. WebSocket API, ETA C++ and EMA C++.
Page-based data
Page-based data contains text or numbers for over-the-counter traded instruments and emerging markets. The data are delivered through Real-time feed row by row, each row is identified by a unique field. The page length is limited to a specific size identified by field that data is delivered on. For example, the ROW64_1 field is defined to have 64 maximum characters and it is the first row while ROW64_2 field is the second row which has 64 maximum characters. Normally, a Real-time data feed publishes the following page:
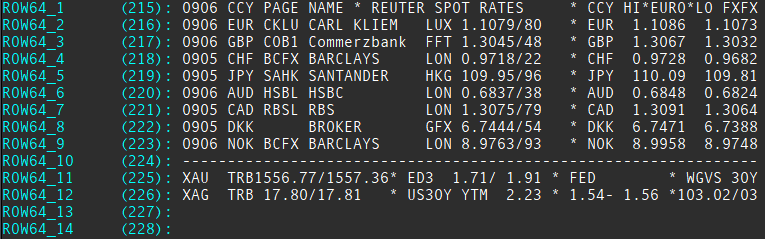
- 64 columns X 14 rows page which contains ROW64_1 field (field id 215) till ROW64_14 (field id 228). The below is a sample RIC named FXFX.
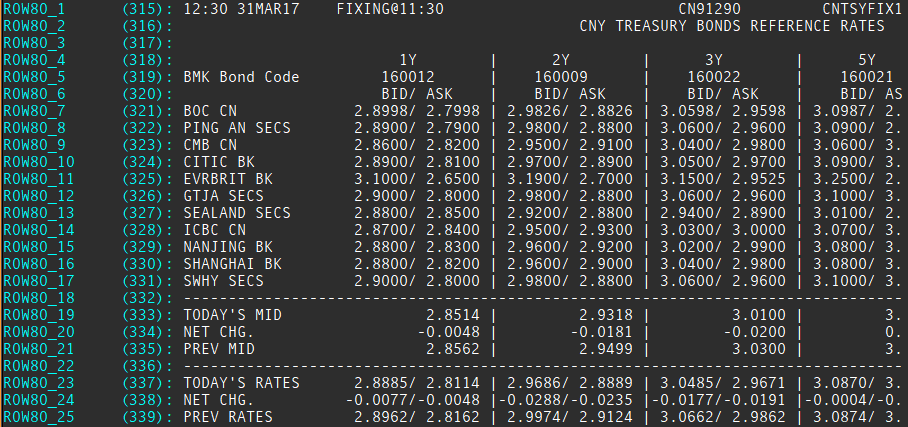
- 80 columns X 25 rows page which contains ROW80_1 field (field id 315) till ROW80_25 (field id 339). The below is a sample RIC named CNTSYFIX1.
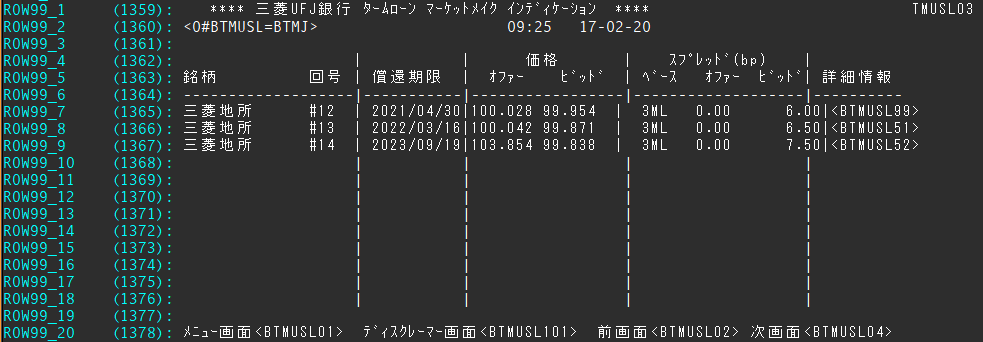
- 99 columns X 20 rows page which contains ROW99_1 field (field id 1359) till ROW99_20 (field id 1378). The below is a sample RIC named BTMUSL03.
Page update
The page row will be updated independently through a field’s update because each row of the page is provided in a specific field. There are two update types as list below:
1. Full update
If page row is totally changed, the update row can be received in plain text. The values of the update will replace all existing values in the row.
2. Partial field update
Normally, updates to specific fields would be accomplished by sending the whole data field (Full update). However, with some large fields this can be inefficient when only a few characters within the data field are to be updated. In such cases the publishing application sends an intra-field positioning sequence within the data field so that the minimum number of characters are transmitted to effect a change.
The syntax of an intra-field positioning sequence is as follow:
<CSI>n<HPA>
where:
- <CSI> is the control sequence introducer (this can be a one or two-byte sequence, either Hex 9B or Hex 1B5B)
- n is an ASCII numeric string representing the cursor offset position relative to the start of the field. Counting begins with the first byte position being number 0 (zero).
- <HPA> is the Horizontal Position Adjust character which terminates the intra-field position sequence (Hex 60 whichis an ASCII “ ‘ ”).
For example:
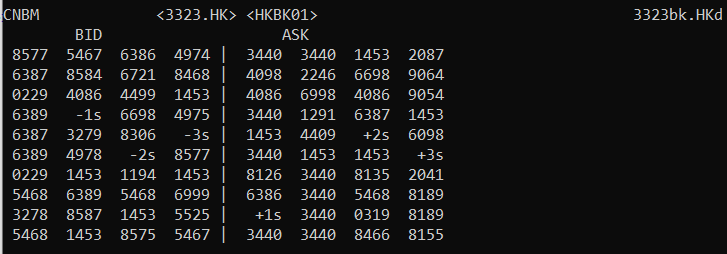
Below is the initial value received for ROW80_7 field of RIC named 3323bk.HKd:
ROW80_7: " 6387 -1s 6698 4975 | 1453 4409 2087 9054"
Offset 0123456789012345678901234567890123456789012345678901234567890123
1 2 3 4 5 6
The update received contains 2 sets of sequence characters. The first set replaces the row at offset 33 with “1291 63” string. The second set replaces the row at offset 47 with “6” string.
The folloiwng is partial update value:
ROW80_7: <CSI>33<HPA>1291 63<CSI>47<HPA>6
After applying the partial update value, the updated row is:
ROW80_7: " 6387 -1s 6698 4975 | 1453 1291 6387 9064"
Offset 0123456789012345678901234567890123456789012345678901234567890123
1 2 3 4 5 6
Implementation
This section explains how Real-Time SDK Java application interprets full update and partial update fields to display the up-to-date page.
EMA Java
EMA provides RmtesBuffer.apply(OmmRmtes data) function which handles both full and partial field update. The function will cache the all values when the field is full updates. When the field is partial field update, the interface will apply the field on the earlier cached values based on the offset positions.
The snipped source code based on example120__MarketPrice__FieldListWalk consumer example:
Iterator <FieldEntry> iter = fieldList.iterator();
FieldEntry fieldEntry;
while (iter.hasNext())
{
fieldEntry = iter.next();
//page 64x14 or 80x25
if ((fieldEntry.fieldId() >= 215 && fieldEntry.fieldId() <= 228) ||
(fieldEntry.fieldId() >= 315 && fieldEntry.fieldId() <= 339)) ||
(fieldEntry.fieldId() >= 1359 && fieldEntry.fieldId() <= 1378)) {
//if the field id does not exist in the map, create new RmtesBuffer object
if (!pageMap.containsKey(fieldEntry.fieldId())) {
pageMap.put(fieldEntry.fieldId(), EmaFactory.createRmtesBuffer());
}
//call apply() to interpret the full update and the partial update
pageMap.get(fieldEntry.fieldId()).apply(fieldEntry.rmtes());
}
}
ValueAdded ETA and ETA
Both provides RmtesDecoder.RMTESApplyToCache(..) function which applies the buffer's partial update and full update data to the RmtesCacheBuffer. Then, you can use RmtesDecoder.RMTESToUCS2(..) function converts the given RmtesCacheBuffer into UCS2 Unicode and stores the data into the RmtesBuffer to display page later. For more details, please refer to section 11.2.9 RMTES Decoding in ETA Java Developers Guide.
The below is an example snipped source code in MarketPriceHandler.java of Consumer example to apply partial update and full update of a received field.
TreeMap <Integer, RmtesCacheBuffer> pageMapRMTES = new TreeMap <Integer, RmtesCacheBuffer> ();
private RmtesDecoder rmtesDecoder = CodecFactory.createRmtesDecoder();
...
case DataTypes.RMTES_STRING:
//page 64x14 or 80x25
if ((fEntry.fieldId() >= 215 && fEntry.fieldId() <= 228) ||
(fEntry.fieldId() >= 315 && fEntry.fieldId() <= 339))
(fEntry.fieldId() >= 1359 && fEntry.fieldId() <= 1378)) {{
RmtesCacheBuffer row;
//the first time, create RmtesCacheBuffer
if (!pageMapRMTES.containsKey(fEntry.fieldId())) {
row = CodecFactory.createRmtesCacheBuffer(bufferlen);
} //get the cached value according to field id
else
row = pageMapRMTES.get(fEntry.fieldId());
//perform full or partial update using rmtesDecoder.RMTESApplyToCache(..) method
if (rmtesDecoder.RMTESApplyToCache(fEntry.encodedData(), row) == CodecReturnCodes.SUCCESS)
{ //cache the whole update in the map
pageMapRMTES.put(fEntry.fieldId(), row);
} else
//if not success, return failure code
ret = CodecReturnCodes.FAILURE;
}
After all fields in the data message are applied from the source code above, the application prints the fields to display page.
//print rmtes fields(page data) only
for (Integer fieldId : pageMapRMTES.keySet())
{
RmtesBuffer rmtesBuffer = CodecFactory.createRmtesBuffer(bufferlen);
//Converts the given RmtesCacheBuffer into UCS2 Unicode and stores the data into the RmtesBuffer.
if (rmtesDecoder.RMTESToUCS2(rmtesBuffer, pageMapRMTES.get(fieldId)) == CodecReturnCodes.SUCCESS)
{
//display each row
byte[] array = new byte[rmtesBuffer.length()];
rmtesBuffer.byteData().get(array, 0, rmtesBuffer.length());
System.out.println(new String(array, Charset.forName("UTF-16")));
} else
System.out.println("Failed converting");
}
You can download the complete source code files of all examples above from Github.
The example output from 3323bk.HKd page is shown below:
Summary
The article explains what page-based data is. The page update types can be full or partial field update. How you can use Real-Time SDK Java i.e. EMA, ValueAdded ETA and ETA to update page-based data for both update types with the sample source code.