

Wasin Waeosri
Developer Advocate
Developer Advocate
Update: Nov 2025
This article shows how to get each News Analytics (TRNA) field data from Machine Readable News (MRN) message. The example application consumes TRNA data from Real-Time Distribution System (Real-Time Advanced Data Hub and Real-Time Advanced Distribution Server) via Machine Readable News (MRN) domain via the Websocket API connection.
Update (As of December 2021): The example now supports the Real-Time -- Optimized (RTO - formerly known as ERT in Cloud) connection.
- The RTO (Authentication V1 - Machine) examples:
- mrn_trna_console_rto.py console application file.
- Alternatively, please check my colleague's LSEG-API-Samples/Example.WebSocketAPI.Python.MRN.RTO GitHub Repository.
- mrn_trna_notebook_app_rto.ipynb notebook file.
- The deployed LSEG Real-Time Distribution System (RTDS) examples are mrn_console_app.py console application and mrn_notebook_app.ipynb notebook files.
The RTO examples are based on the Version 1 Authentication (Machine-ID). If you want to use the Version 2 Authentication (Service-ID), please check the following resources:
- Real-Time WebSocket API: The Real-Time Optimized Version 2 Authentication Migration Guide.
- Migrating the WebSocket Machine Readable News Application to Version 2 Authentication.
WebSocket API Overview and Prerequisite
The WebSocket API is direct access that enables easy integration into a multitude of client technology environments such as scripting and web. This API runs directly on your Real-Time Distribution System infrastructure or the on the cloud and presents data in an open (JSON) readable format.
This example is focusing on the Machine Readable News (MRN) data processing only. I highly recommend you check the Websocket API tutorials pages if you are not familiar with WebSocket API.
The Tutorials page provides a step-by-step guide (connect, log in, request data, parse data, etc) for developers who are interested in developing a WebSocket application to consume real-time data from Real-Time. The Tutorials also cover both Real-Time Optimized (formerly known as ERT in Cloud) and deployed Real-Time Distribution System infrastructure connection scenarios.
News Analytics Overview
Machine Readable News Analytics (TRNA) provides real-time numerical insight into the events on multiple news sources, in a format that can be directly consumed by algorithmic trading systems. TRNA enables algorithms to exploit the power of news to seize opportunities, capitalize on market inefficiencies, and manage event risk.
TRNA is published via the Real-Time Platform as part of Machine Readable News (MRN) data model. MRN is an advanced service for automating the consumption and systematic analysis of news. It delivers deep historical news archives, ultra-low latency structured news, and news analytics directly to your applications.
MRN Data Behavior
MRN is published over the Real-Time Platform using an Open Message Model (OMM) envelope in News Text Analytics domain messages. The Real-time News content set is made available over MRN_STORY RIC. The content data is contained in a FRAGMENT field that has been compressed and potentially fragmented across multiple messages, to reduce bandwidth and message size.
A FRAGMENT field has a different data type based on a connection type:
The data goes through the following series of transformations:
- The core content data is a UTF-8 JSON string
- This JSON string is compressed using gzip
- The compressed JSON is split into several fragments (BUFFER or Base64 ASCII string) which each fit into a single update message
- The data fragments are added to an update message as the FRAGMENT field value in a FieldList envelope
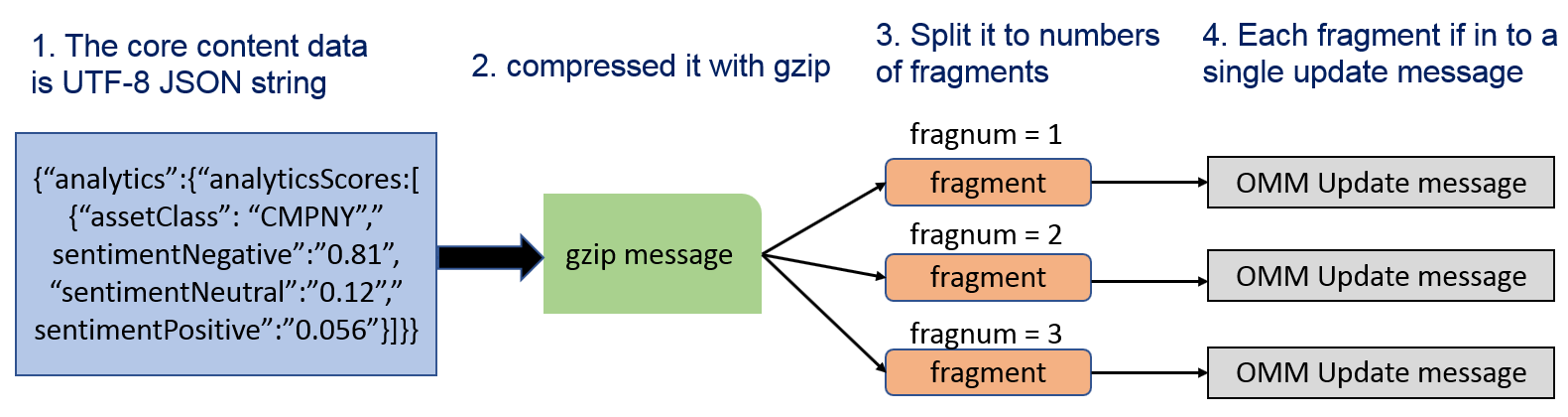
Therefore, to parse the core content data, the application will need to reverse this process. The WebSocket application also needs to convert a received Base64 string in a FRAGMENT field to bytes data before further process this field. This application uses Python base64 and zlib modules to decode Base64 string and decompress JSON string.
How to consume, assemble, and decode MRN data with WebSocket API.
Please visit Introduction to Machine Readable News with WebSocket API article which gives you a full explanation of MRN Data processing topics:
- Webinar Recording: Introduction to Machine Readable News
- Introduction to Machine Readable News (MRN) with Enterprise Message API (EMA).
- MRN Data Models and Real-Time SDK Implementation Guide.
- Introduction to Machine Readable News with WebSocket API.
The above article explains MRN with Python language for MRN Real-time News data (MRN_STORY RIC) , but the main concept for consuming and assembling MRN data are the same for all technologies and all MRN-specific RIC names.
How to get News Analytics fields from MRN JSON message WebSocket API.
The example application is available at GitHub page. Please check the README.md file in the project for more detail regarding how to run the application.
The Notebook application connects to Real-Time Distribution System via the WebSocket connection, then consumes TRNA Data as MRN data domain. When the Notebook receives TRNA data from Real-Time Distribution System, it assembles, decodes MRN textual News Analytics messages and keeps them in _trna_messages list variable. You can get each TRNA JSON message and associate analytics fields from this variable.
News Analytics Data Model Overview
After assembly and decompression, the News Analytics data appears as JSON message in UTF-8 encoding. You can find the full description of News Analytics Data Models and Fields data in User Guide document section of News Analytics Product page.
The News Analytics JSON message has three top-level items:
- id: The value of this field is in [feedFamilyCode]:[sourceId] format (see more detail in below section).
- analytics: Analytics Groups sub-group containing the analytics scores
- newsItem: This group contains metadata sourced directly from the STORY item, in contrast to the newsItem group also inside the analytics group that contains data derived from the TRNA scoring.
News Item Group (Top-Level Group)
The News Analytics feed contains two news item groups. This top-level group (trna_json_message['newsItem']) contains values that are contained within the news item being processed; the other group within the analytics group contains values derived from the news item by the analytics system.
Because the fields below are sourced from the incoming news item data and mapped to the below fields, those mappings can vary by the feedFamilyCode value.
Example Fields:
- dataType: The broad type of data the news item belongs to. One of "News", "Social"
- feedFamilyCode: A code that identifies the family of feeds the news item came from. Thomson Reuters feeds = "tr"
- headline: The headline text of the news item.
- sourceTimestamp: UTC timestamp of this news item. Millisecond precision. The source of this data varies by the feedFamilyCode value.
- provider: Identifier for the organization which provided the news item. The source of this data varies by the feedFamilyCode value.
- "tr": from provider field
- "mrvr": from sourceName or publisher field
- urgency: Differentiates story types.
- 1: alert
- 3: article
Example Code:
news_item = _trna_messages[0]["newsItem"]
print("dataType: ", news_item["dataType"])
print("Headline: ", news_item["headline"])
print("Regional Timestamp: ", news_item["sourceTimestamp"])
print("feedFamilyCode: ", news_item["feedFamilyCode"])
print("provider: ", news_item["provider"][3:]) # news_item["provider"] == NS:RTRS
print("urgency: ", news_item["urgency"], " : ", (lambda item_type: "alert" if 1 else "article")(news_item["urgency"]))
Example Output:
dataType: News
Headline: Nomad Technologies Holdings Ltd - Monthly Return of Equity Issuer on Movements in Securities for the month ended 29 February 2020(with URL)
sourceTimestamp: 2020-03-03T09:05:29.828Z
feedFamilyCode: tr
provider: HIIS
urgency: 3 : alert
Analytics Score Group
Each analytics score group contains all the analytics information derived from the news item for a specific asset as a simple group of named values.
Example Fields for this group:
- assetClass: The broad class that the asset belongs to. Also describes the type of TRTS sentiment engine used in the scoring.
- Either "CMPNY" for a company or "COM" for a commodity.
- Set to "CMPNY" for document-level scores because of use of the same scoring engine as used for company-level scores.
- assetCodes: List of prefixed codes, in conjunction with assetId field below, which identify the asset within various symbologies.
- If assetClass value is "CMPNY": "P:" prefix for PermID and "R:" for RIC. Can contain multiple RICs for a single company, including the primary one and those tagged to the news item.
- If assetClass value is "COM": "N2" prefix for the topic code.
- assetId: Primary identifier for the asset. PermID for company and topic code for commodity. Please see more detail regarding each topic code for commodity in Appendix 2 "Commodity & Energy Code Coverage" section of News Analytics Data Models document.
- assetName: A human readable name for the asset, used as an identifier for unknown entity scoring.
- firstMentionSentence: The first sentence, starting with the headline, in which the scored asset is mentioned. Thus, a value of 1 denotes the headline, 2 the first sentence of the story body, 3 the second sentence, etc.
- relevance: A decimal number indicating the relevance of the news item to the asset. It ranges from 0 to 1.
- sentimentClass: This field indicates the predominant sentiment class for this news item with respect to this asset. The indicated class is the one with the highest probability.
- 1: Positive
- 0: Neutral
- -1: Negative
- sentimentNegative: The probability that the sentiment of the news item was negative for the asset.
- sentimentNeutral: The probability that the sentiment of the news item was neutral for the asset.
- sentimentPositive: The probability that the sentiment of the news item was positive for the asset.
Example Code:
asset_class = None
asset_codes = None
sentiment_class = {-1: 'Negative', 0: 'Neutral', 1: 'Positive'}
def get_permid(asset_codes):
for code in asset_codes:
if code[:2] == "P:":
return code[2:]
def get_company(asset_codes):
company = [code[2:] for code in asset_codes if code[:2] == "R:"]
return " ".join(company)
def get_topic_code(asset_codes):
topic = [code[3:] for code in asset_codes if code[:3] == "N2:"]
return " ".join(topic)
analytic_scores_group = _trna_messages[0]["analytics"]["analyticsScores"]
for analytic_score in analytic_scores_group:
if analytic_score["assetClass"]:
asset_class = analytic_score["assetClass"]
asset_codes = analytic_score["assetCodes"]
print("assetClass: ", asset_class)
print("assetCodes: ", asset_codes)
if asset_class == "CMPNY":
print("PermID: ", get_permid(asset_codes))
print("Co: ", get_company(asset_codes))
elif asset_class == "COM":
print("Topic Codes: ", get_topic_code(asset_codes))
print("assetId: ", analytic_score["assetId"])
print("assetName: ", analytic_score["assetName"])
print("relevance: ",analytic_score["relevance"])
print("sentimentClass: ", analytic_score["sentimentClass"],
":", sentiment_class[analytic_score["sentimentClass"]] )
print("sentimentPositive: ", analytic_score["sentimentPositive"])
print("sentimentNeutral: ", analytic_score["sentimentNeutral"])
print("sentimentNegative: ", analytic_score["sentimentNegative"])
Example Output:
assetClass: CMPNY
assetCodes: ['P:5066556859', 'R:8645.HK']
PermID: 5066556859
Co: 8645.HK
assetId: 5066556859
assetName: Nomad Technologies Holdings Ltd
relevance: 1.0
sentimentClass: 0 : Neutral
sentimentPositive: 0.158962
sentimentNeutral: 0.740094
sentimentNegative: 0.100944
Example Output 2:
assetClass: COM
assetCodes: ['N2:MTAL', 'N2:MTAL08']
Topic Codes: MTAL MTAL08
assetId: MTAL
assetName: Non-Ferrous Metals
relevance: 0.707107
sentimentClass: 1
sentimentPositive: 0.399518
sentimentNeutral: 0.343445
sentimentNegative: 0.257036
Windowed Count Group
The windowed count group is used to associate a count with the window of time it relates to. It is used for the noveltyCounts and volumeCounts analytics properties.
Novelty Counts
The novelty of the content within a news item on a particular asset is calculated by comparing it with the asset-specific text over a cache of previous news items that contain the asset.
The comparison between items is done using a linguistic fingerprint. If the news items are similar, they are termed as being "linked". As a result, a content item can "link" only to an item of the same language.
Five historical periods are used in the comparison. The default periods are 12 hours, 24 hours, 3 days, 5 days, and 7 days prior to the news item’s timestamp.
Volume Counts
The volume of news for each asset is calculated. A cache of previous news items is maintained and the number of news items that mention the asset within each of five historical periods is calculated. The cache is language-specific, e.g., a volumeCount on an English-language item measures the number of other English-language items in that historical period.
By default, the historical periods are 12 hours, 24 hours, 3 days, 5 days and 7 days prior to the news item’s timestamp and are the same used in the novelty calculations. Thus, direct comparisons between similar and total items within the historical periods can be achieved.
Example Fields:
- itemCount: Number of items
- window: Length of time the count covers nH (for hours) or nD (for days). Default values are "12H", "24H", "3D", "5D", and "7D".
Example Code:
def windowsed_count_group(group):
for item in group:
print("itemCount: ", item["itemCount"])
print("window: ", item["window"])
analytic_scores_group = _trna_messages[0]["analytics"]["analyticsScores"]
for analytic_score in analytic_scores_group:
print("Novelty Counts:\n")
windowsed_count_group(analytic_score["noveltyCounts"])
print("--------------------------------------------------------")
print("Volumn Counts:\n")
windowsed_count_group(analytic_score["volumeCounts"])
print("--------------------------------------------------------")
Example Output:
Novelty Counts:
itemCount: 1
window: 12H
itemCount: 1
window: 24H
itemCount: 1
window: 3D
itemCount: 1
window: 5D
itemCount: 1
window: 7D
--------------------------------------------------------
Volumn Counts:
itemCount: 1
window: 12H
itemCount: 1
window: 24H
itemCount: 1
window: 3D
itemCount: 1
window: 5D
itemCount: 1
window: 7D
--------------------------------------------------------
Linked Id Group
The linked id group is used to associate an id with its position in a longer list of ids. It is used for the linkedIds. This group is not populated for document-level scores, since novelty is not calculated.
Example Fields:
- idPosition: Position of the linkedId in the complete list of linked Ids. 0 is the first/oldest, and the largest/most recent is the 7-day itemCount minus 1.
- linkedId: id of the item at this position
Example Code:
linked_id_group = None
analytic_scores_group = _trna_messages[0]["analytics"]["analyticsScores"]
for analytic_score in analytic_scores_group:
print("Linked Id Group: ")
linked_id_group = analytic_score["linkedIds"]
if linked_id_group:
for linked_id in linked_id_group:
print("idPosition: ", linked_id["idPosition"])
print("linkedId: ", linked_id["linkedId"])
Example Output:
Linked Id Group:
idPosition: 0
linkedId: tr:HKS8b3CTf_2003032QCbnadsx97vfj84CPVr+wZf+s//2WLKx1mGvf
News Item Group (Analytics Sub-group)
The TRNA feed contains two news item groups. This group (trna_json_message["analytics"]["newsItem"]), within the analytics group, contains values derived from the news item by the analytics system.
Example Fields:
- companyCount: The number of companies explicitly listed in the news item in the subjects field
- exchangeAction: One of "IMBALANCE", "HALT", "RESUME", "BLOCK TRADE", "INDICATION", "UNDEFINED".
- Set to "UNDEFINED" for all Japanese-language scores.
- marketCommentary: Indicator that the item is discussing general market conditions, such as "After the Bell" summaries.
- sentenceCount: The total number of sentences in the news item.
- wordCount: The total number of lexical tokens (words and punctuation) in the news item.
Example Code:
news_item_groups = _trna_messages[0]["analytics"]["newsItem"]
print("companyCount: ", news_item_groups["companyCount"])
print("exchangeAction: ", news_item_groups["exchangeAction"])
print("marketCommentary: ", news_item_groups["marketCommentary"])
print("sentenceCount: ", news_item_groups["sentenceCount"])
print("wordCount: ", news_item_groups["wordCount"])
Example Output:
companyCount: 1
exchangeAction: UNDEFINED
marketCommentary: False
sentenceCount: 9
wordCount: 116
Next Steps
Once the application can retrieve each News Analytics field data from Refinitiv Real-Time, the application needs to implement business logic to collect and analyze those data based on interested Analytics asset. Please see the examples of how to use each asset below:
- Sentiment: Positive sentiment typically leads to asset price rise, negative sentiment to a decline
- Relevance: Filter out News Analytics records with low relevance
- Novelty: Filter out News Analytics records that are similar to more than 0 or 1 recent news items
- Volume: A sudden spike in overall news volume often leads to increased trading volume and volatility
For more detail regarding each asset usage and information, please check News Analytics Product page..
References
For further details, please check out the following resources:
- LSEG Real-Time products family page on the LSEG Developers Community website.
- WebSocket API page.
- Developer Webinar Recording: Introduction to Electron WebSocket API.
- News Analytics Product page.
- Introduction to Machine Readable News with WebSocket API.
- Introduction to Machine Readable News (MRN) with Enterprise Message API (EMA).
- MRN Data Models and Real-Time SDK Implementation Guide.
- MRN (Real-Time News) WebSocket Python example on GitHub.
- MRN (Real-Time News) WebSocket Python Console example on GitHub
- MRN WebSocket JavaScript example on GitHub.
- MRN WebSocket C# NewsViewer example on GitHub.
- Real-Time WebSocket API: The Real-Time Optimized Version 2 Authentication Migration Guide.
- Migrating the WebSocket Machine Readable News Application to Version 2 Authentication.
For any question related to this example or WebSocket API, please use the Developer Community Q&A Forum.
Get In Touch
Related Articles
Related APIs
Source Code
Request Free Trial
Call your local sales team
Americas
All countries (toll free): +1 800 427 7570
Brazil: +55 11 47009629
Argentina: +54 11 53546700
Chile: +56 2 24838932
Mexico: +52 55 80005740
Colombia: +57 1 4419404
Europe, Middle East, Africa
Europe: +442045302020
Africa: +27 11 775 3188
Middle East & North Africa: 800035704182
Asia Pacific (Sub-Regional)
Australia & Pacific Islands: +612 8066 2494
China mainland: +86 10 6627 1095
Hong Kong & Macau: +852 3077 5499
India, Bangladesh, Nepal, Maldives & Sri Lanka:
+91 22 6180 7525
Indonesia: +622150960350
Japan: +813 6743 6515
Korea: +822 3478 4303
Malaysia & Brunei: +603 7 724 0502
New Zealand: +64 9913 6203
Philippines: 180 089 094 050 (Globe) or
180 014 410 639 (PLDT)
Singapore and all non-listed ASEAN Countries:
+65 6415 5484
Taiwan: +886 2 7734 4677
Thailand & Laos: +662 844 9576