
Filtering Realtime News with RDP Filters

Introduction to News Filtering
In this article we would like to discuss how to design and implement filtering of realtime Machine Readable News (MRN) using Refinitiv Data Platform (RDP) news filtering expressions.
Let us first look at an example of an RDP filtering expression:

Let us note how:
- Each stanza of filtering can be either present or absent in the expression
- The filtering stanzas are combined with logical ANDs and ORs as well as round parenthesis
And we are ready to put together a simple map:
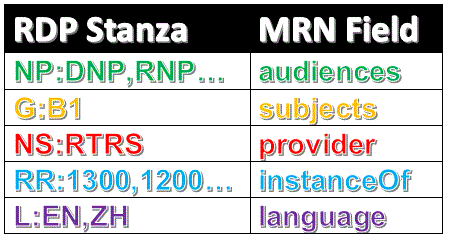
consequently our design approach on receipt of a new tagged realtime story will be:
1. Processing of filtering stanzas against the story:
a) Find each filtering stanza in the filtering expression
b) Identify the corresponding field to be filtered in realtime news
c) Apply filtering to filtering stanza based on the contents of the field - resolve it into True or False conclusion
2. Replace the results into the original filtering expression
3. Use python regular expression module resolve the expression into a single True or False conclusion
4. Present the result as the output. Consequently, the results of the filtering can be processed per application requirement at hand, for example, only stories that pass the filtering can be propagated to the business tier for presentation.
Now let us take a more detailed look at the implementation of this approach:
Building up from the Existent RDP Examples
When working on this example, we have started with RDP Market Price Service discovery example https://github.com/Refinitiv/websocket-api/tree/master/Applications/Examples/RDP/python and
Example of outputting Machine Readable News JSON data using Websockets https://github.com/Refinitiv-API-Samples/Example.WebSocketAPI.Python.MRN/tree/ERT-in-Cloud,
next building up as https://github.com/Refinitiv-API-Samples/Example.WebsocketAPI.RealtimeNewsStreamingOptimizedWealth.Python and adding the filtering option in:
https://github.com/Refinitiv-API-Samples/Example.WebsocketAPI.MRNRDPGwServiceDiscoveryFilter.Python
Please note that Refinitiv Data Platform is an actively growing, evolving and improving product, and so is RDP news. Consequently, the specifics of filtering that are discussed next may also change and improve over time.
In the next sections, we are going to focus on new filtering.
Applyting Filtering
At the point when a story is assembled out of fragments and decompressed is when we apply the filtering criteria to determine the content of the story:
news_decompressed = json.loads(decompressed_data)
print("News = "+json.dumps(news_decompressed, indent=2, separators=(',', ':')))
sys.stdout.flush()
print("<<<verify RDP filter result>>>= " +
str(self.verifyNewsAgainstFilter(news_decompressed,filter_expression)))
Filtering Audiences
Audiences filtering stanza can be parenthesized or not, and in the former case, there can be nested parenthesis. We take the approach of evaluating audiences filtering stanza against the audiences field in news as a whole, from the first to the last parenthesis, if required:
# audience there can be single NP, comma-separated = OR, explicit OR or AND or combo
audience_begin = filter_expr_.find('NP:')
if audience_begin !=-1:
print('\t~~~Audience filtering:~~~')
if filter_expr_.find('(') != -1 and filter_expr_.find('(') < audience_begin:
audience_begin = filter_expr_.find('(')
audience_end = filter_expr_.find('AND',audience_begin + 2)
if audience_end != -1:
additional_audience_begin = filter_expr_.find('NP:',audience_end + 3)
while additional_audience_begin != -1 and audience_end != -1:
audience_end = filter_expr_.find('AND',additional_audience_begin + 2)
additional_audience_begin = filter_expr_.find('NP:',audience_end + 3)
if audience_end == -1:
audience_end = len(filter_expr_)
else:
audience_end = len(filter_expr_)
filter_expr_audience = filter_expr_[audience_begin:audience_end]
audience_res = self.audienceCheck(str(news_['audiences']), filter_expr_audience)
filter_expr_ = filter_expr_.replace(filter_expr_[0:audience_end],str(audience_res)+' ')
current_pos = audience_end + 1
and we are going to define helper function audienceCheck to handle the audience verification, that can potentially be called recursively:
def audienceCheck(self, _audiences_stanza, filter_expr_audience):
filter_expr_audience = filter_expr_audience.replace(","," OR NP:")
filter_expr_audience = filter_expr_audience.replace("&"," AND ")
if filter_expr_audience.find('AND') == -1: #only ORs or single - quick shortcut
orAudiences = filter_expr_audience.split(' OR ')
if 'True' in orAudiences:
return True
elif any(x in _audiences_stanza for x in orAudiences):
print('<TRUE> for audiences')
return True
else:
# print('<FALSE> for audiences')
return False
elif filter_expr_audience.find('OR') == -1: #only ANDs - quick shortcut
andAudiences = filter_expr_audience.split(' AND ')
if 'False' in andAudiences:
return False
elif all(x in _audiences_stanza for x in andAudiences):
print('<TRUE> for audiences')
return True
else:
# print('<FALSE> for audiences')
return False
else: #it's a parenthesis with OR and AND, for example (NP:RNP OR NP:DNP) AND NP:M, mixed always with parenthesis
parent_begin = filter_expr_audience.find('(')
while parent_begin != -1: #evaluate parenthesis
parent_end = filter_expr_audience.find(')')
filter_sub_expr_audience = filter_expr_audience[(parent_begin+1):(parent_end-1)]
parentheses_result = str(self.audienceCheck(_audiences_stanza, filter_sub_expr_audience))
filter_expr_audience = filter_expr_audience.replace(filter_expr_audience[parent_begin:parent_end+1],str(parentheses_result))
parent_begin = filter_expr_audience.find('(')
NP_begin = filter_expr_audience.find('NP:')
while NP_begin != -1: #evaluate individual NPs
NP_end = filter_expr_audience.find(' ', NP_begin)
filter_sub_expr_audience = filter_expr_audience[(NP_begin):(NP_end)]
if NP_end == -1:
NP_end = len(filter_expr_audience)
NP_result = str(self.audienceCheck(_audiences_stanza, filter_sub_expr_audience))
filter_expr_audience = filter_expr_audience.replace(filter_expr_audience[(NP_begin):(NP_end)],str(NP_result))
NP_begin = filter_expr_audience.find('NP:')
filter_expr_audience = filter_expr_audience.replace('OR','or').replace('AND','and')
return eval(filter_expr_audience) #python eval loglcal and and or mix
return True
Filtering Subjects
Filtering subjects is much more straightforward, and we take the uniform approach:
subjects_begin = filter_expr_.find('G:')
if subjects_begin !=-1:
print('\t^^^Subjects filtering:^^^')
subjects_end = self.findStanzaEndPos("AND|OR",filter_expr_,subjects_begin)
filter_expr_subjects = filter_expr_[subjects_begin:subjects_end]
print('\t\tFound in news: '+ str(news_['subjects']))
print('\t\tRequired in filter: ' + filter_expr_subjects)
subjects_res = self.simpleCheck(str(news_['subjects']), filter_expr_subjects, ' OR G:')
print('\t^^^Subjects result = '+str(subjects_res)+'^^^')
# replace subjects in the expression
filter_expr_ = filter_expr_.replace(filter_expr_[subjects_begin:subjects_end],str(subjects_res)+' ')
print('\t^^^Filtering expression progressed = '+filter_expr_+'^^^')
defining a helper function simpleCheck to be used in the verification of subjects, provider, instanceOf and language filtering stanzas:
def simpleCheck(self, _subjects_stanza, filter_expr_subjects, replaceForComma):
#use for subjects and provider instanceOf check
filter_expr_subjects = filter_expr_subjects.replace(",",replaceForComma)
# always OR
orSubjects = filter_expr_subjects.split(' OR ')
if any(x in _subjects_stanza for x in orSubjects):
return True
else:
return False
Filtering Provider
Is done in s similar way:
provider_begin = filter_expr_.find('NS:')
if provider_begin !=-1:
print('\t***Provider filtering:***')
provider_end = self.findStanzaEndPos("AND|OR|\)",filter_expr_,provider_begin)
filter_expr_provider = filter_expr_[provider_begin:provider_end]
print('\t\tFound in news: '+ str(news_['provider']))
print('\t\tRequired in filter: ' + filter_expr_provider)
provider_res = self.simpleCheck(str(news_['provider']), filter_expr_provider, ' OR NS:')
print('\t***Provider result = '+str(provider_res)+'***')
# replace provider in the expression
filter_expr_ = filter_expr_.replace(filter_expr_[provider_begin:provider_end],str(provider_res)+' ')
print('\t***Filtering expression progressed = '+filter_expr_+'***')
Filtering Named Items
We look for the beginning of the filtering stanza and the end of it the same way:
instanceOf_begin = filter_expr_.find('RR:')
if instanceOf_begin !=-1:
print('\t+++instanceOf filtering:+++')
instanceOf_end = self.findStanzaEndPos("AND|OR|\)",filter_expr_,instanceOf_begin)
filter_expr_instanceOf = filter_expr_[instanceOf_begin:instanceOf_end]
print('\t\tFound in news: '+ str(news_['instancesOf']))
print('\t\tRequired in filter: ' + filter_expr_instanceOf)
instanceOf_res = self.simpleCheck(str(news_['instancesOf']), filter_expr_instanceOf, ' OR RR:')
print('\t+++instanceOf result = '+str(instanceOf_res)+'+++')
# replace instanceOf in the expression
filter_expr_ = filter_expr_.replace(filter_expr_[instanceOf_begin:instanceOf_end],str(instanceOf_res)+' ')
print('\t+++Filtering expression progressed = '+filter_expr_+'+++')
Language Filtering
Language filtering uses the same approach with a slight caveat as some replacement may be required prior to bring the language filtering stanza to the uniform regular expression required:
language_begin = filter_expr_.find('&language=')
if language_begin != -1:
filter_expr_ = filter_expr_.replace('&language=','AND L:')
language_begin = language_begin + 4
if language_begin == -1:
language_begin = filter_expr_.find('L:')
if language_begin != -1:
print('\t===Language fitering:===')
filter_expr_language = filter_expr_[language_begin:len(filter_expr_)]
filter_expr_language = filter_expr_language.lower()
print('\t\tFound in news: '+ str(news_['language']))
print('\t\tRequired in filter: ' + filter_expr_language)
language_res = self.simpleCheck(str(news_['language']), filter_expr_language[2:], ' OR ')
print('\t===language result = '+str(language_res)+'===')
# replace language in the expression
filter_expr_ = filter_expr_.replace(filter_expr_[language_begin:len(filter_expr_)],str(language_res)+' ')
filter_expr_ = filter_expr_.replace('OR','or').replace('AND','and')
Putting It All Together
This part is very simple and I find it elegant- we use Python's capability to evaluate the resulting regular expression:
return eval(filter_expr_)
this gives us the answer of whether the news story received has fully passed the filtering requiriments specified by RDP filter expression.
I would like to include here examples of RDP filtering expressions that can be used for testing:
"--filter_expression",
"NP:DNP,RNP,MF,CDS AND ((G:B1 AND NS:RTRS) OR (RR:1300,1200,1105,850,321,347,529,266,1554,1536,1697,2096,1255,1728,1680,2123,2224,2266,1908,846) AND L:EN,ZH",
"--filter_expressionN",
"NP:RNP OR NP:DNP OR NP:MF",
"--filter_expression",
"NP:U AND NP:MNI",
"--filter_expression",
"(NP:RNP OR NP:DNP)&NP:M ",
"--filter_expression",
"NP:U",
"--filter_expression",
"NP:DNP,RNP,MF,OMXN,NBD,OE,BL,BXB,CZS,DA,FN,FA,GER,GNG,HX,I,N,NW,PX,P,RDN,SP,SW,SWF,SWI,TS,UKI,RX AND (G:4,1F,4R,8B,7N,85,8R,8M,9Y,1W,8T,2E,19,90,5M,3D,6A,46,6I,5J,6X,7M,4G,3N,5Y,A3,2Z,1C,55,6V,30,8Z,7J,4H,38,71 AND NS:RTRS)&language=en",
"--filter_expression",
"NP:DNP,RNP,MF,J AND ((G:41 AND NS:RTRS) OR (RR:1561,1707,1716,2810,2796,1263,2543,2796,2803)) AND L:JA",
"--filter_expression",
"NP:DNP,RNP,MF AND ((G:2V AND NS:RTRS) OR (RR:1200,1300,1105,850,321,347,529,266,1558,654,1538,647,1547,646)) AND L:EN,ES"
References
Example code on GitHub: https://github.com/Refinitiv-API-Samples/Example.WebsocketAPI.MRNRDPGwServiceDiscoveryFilter.Python
Other relevant examples:
https://github.com/Refinitiv/websocket-api/tree/master/Applications/Examples/RDP/python and
https://github.com/Refinitiv-API-Samples/Example.WebSocketAPI.Python.MRN/tree/ERT-in-Cloud,
Refinitiv Websocket API information: https://developers.refinitiv.com/en/api-catalog/refinitiv-real-time-opnsrc/refinitiv-websocket-api
Introduction to Machine Readable News with WebSocket API artcile: