
RDP News Metadata with JSON Viewer

Introduction
In this article I would like to talk about another way of looking at news.
It is no secret that Refinitiv provides unparalleled news coverage to the financial community. Refinitiv's financial news combines thousands of global sources with access to Reuters News and insight. Refinitiv Data Platform news service (RDP News) makes available headlines, stories, and analytics, that are easy to integrate programmatically, absorb visually, analyze, correlate, combine with various other content sets; many other uses are important to customers worldwide. RDP news features self-contained detailed description and categorization of the meaning of news (news metadata) that helps us understand news and make the fore-mentioned use cases, as well as many others, feasible.
Next, we are going to look at the metadata built into RDP news using Python, Jupyter Lab/Notebook and a JSON viewer.
Let us get started.
Credentials and Authentication
RDP services, of which RDP news is one, require authentication to RDP in order to gain access. In the companion example notebook (please see References) we are going to:
- Absorb valid RDP credentials, permissioned to access RDP news (that includes user id, password and client id,)
- Submit RDP credentials to RDP authentication endpoint and obtain a valid RDP access token
- All RDP news requests will make use of, and will be submitted to RDP news service, with the valid access token
- Once RDP token expires, a new token will need to be requested and submitted with the next RDP news requests
Requesting Multiple Headlines
Let us bein by defining a helper function for requesting multiple headlines as defined by query and return them as a pandas dataframe:
def getHeadlines(query, numLines, date_from='', date_to='', return_as_text=False):
news_category_URL = "/data/news"
headlines_endpoint_URL = "/headlines?query="
REQUEST_URL = base_URL + news_category_URL + RDP_version + headlines_endpoint_URL+ query +"&limit="+ str(numLines)
if date_from != '':
REQUEST_URL = REQUEST_URL + '&dateFrom='+date_from
if date_to != '':
REQUEST_URL = REQUEST_URL + '&dateTo='+date_to
accessToken = getToken();
print("Requesting: ",REQUEST_URL)
acceptValue = "*/*"
dResp = requests.get(REQUEST_URL, headers = {"Authorization": "Bearer " + accessToken, "Accept": acceptValue});
if dResp.status_code != 200:
print("Unable to get data. Code %s, Message: %s" % (dResp.status_code, dResp.text));
if dResp.status_code != 401: # error other then token expired
return("Error "+str(dResp.status_code))
accessToken = getToken(); # token refresh on token expired
dResp = requests.get(REQUEST_URL, headers = {"Authorization": "Bearer " + accessToken, "Accept": acceptValue});
if dResp.status_code == 200:
print("Resource access successful")
else:
print("Resource access successful")
if return_as_text:
return dResp.text
jResp = json.loads(dResp.text);
dfH = pandas.json_normalize(jResp,record_path =['data'])
return dfH
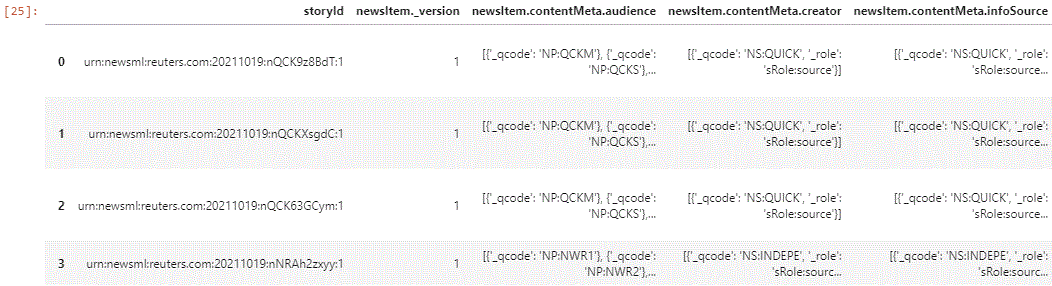
Requesting a Story
Requesting a story is a very common use case. An RDP story result comes complete with rich metadata. Let us define the request:
def getStory(storyId, jsonOrHtml):
news_category_URL = "/data/news"
story_endpoint_URL = "/stories"
REQUEST_URL = base_URL + news_category_URL + RDP_version + story_endpoint_URL+ "/" + storyId
accessToken = getToken();
print("Requesting: ",REQUEST_URL)
acceptValue = "application/json"
if jsonOrHtml != True:
acceptValue = "text/html"
dResp = requests.get(REQUEST_URL, headers = {"Authorization": "Bearer " + accessToken, "Accept": acceptValue});
if dResp.status_code != 200:
print("Unable to get data. Code %s, Message: %s" % (dResp.status_code, dResp.text));
if dResp.status_code != 401: # error other then token expired
return("")
accessToken = getToken(); # token refresh on token expired
else:
print("Resource access successful")
return dResp.text
The specific story that we request is determined by storyId parameter. RDP news allows to request one story at a time, and because a story comes complete with metadata, it can be quite substantial.
In order to request multiple stories, the request has to be run per number of the required stories, so we define a convenience function. The format of the returned story can be either be targeted to HTML display, with HTML tagging for convenient layout, or it can be JSON, that is best suitable for analysis. The helper function accepts a parameter defining the requested format.
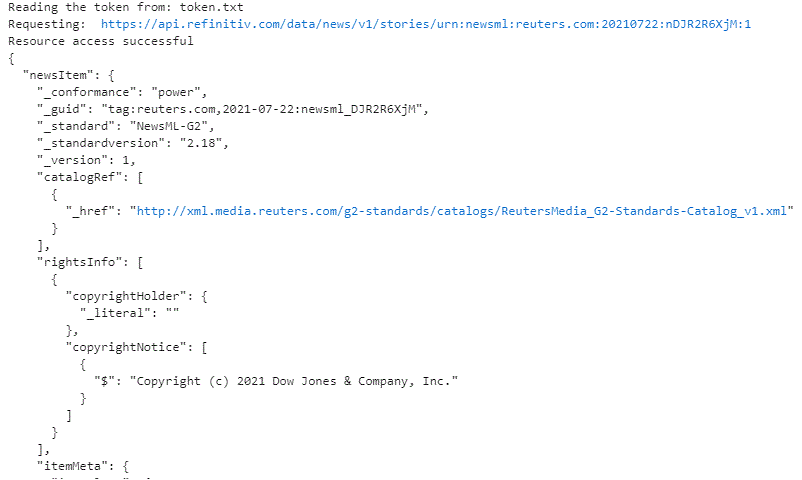
Let us first look at an example of requesting in JSON:
txt = getStory('urn:newsml:reuters.com:20210722:nDJR2R6XjM:1',True)
#txt = getStory('urn:newsml:reuters.com:20210811:nL1N2PI1YN:9')
#txt = getStory('urn:newsml:reuters.com:20210811:nTNF29sf:1', True)
jResp = json.loads(txt);
print(json.dumps(jResp, indent=2));
And next we look at requesting as HTML-tagged, for display:
txt = getStory('urn:newsml:reuters.com:20210722:nDJR2R6XjM:1', False)
print('********* story text')
print(txt)
print('********* story HTML')
from IPython.core.display import display, HTML
display(HTML(txt))
resulting in story HTML:

When the story is formatted and displayed it will look like this:


Request Stories Corresponding to Headlines by StoryID
Now, let us use the storyIds that were part of the retrieved headlines to conveniently request multiple stories and display them while applying HTML formatting:
dfHeadlines
for index, row in dfHeadlines.iterrows():
txt = getStory(row['storyId'], False)
display(HTML(txt))
However, requesting stories in JSON format, with metadata, is often preferred and allows for analysis. For example we are going to:
- Store the retrieved JSON stories with metadata into a list of dataframes
- For stories that were rated and include news sentiments we are going to parse out the sentiment part and store it with the headline
dfHeadlines
listDfStories = []
for index, row in dfHeadlines.iterrows():
fullJsonOut = getStory(row['storyId'], True)
if fullJsonOut == "":
break
jResp = json.loads(fullJsonOut);
print(json.dumps(jResp, indent=4));
# store storyJson with the headline
dfHeadlines.loc[index, 'storyJson'] = fullJsonOut;
# if ratings are available in metadata, parse them and store them with the headline
try:
content_meta = jResp['newsItem'].get('contentMeta')
if content_meta: #metedata exists
content_meta_ex_property = content_meta.get('contentMetaExtProperty')
if content_meta_ex_property:
for ex_property in content_meta_ex_property:
if 'hasSentiment' in ex_property['_rel']: #sentiment exists
dfHeadlines.loc[index, ex_property['_rel']] = ex_property['_value']
else:
dfHeadlines.loc[index, ex_property['_rel']] = 'No sentiment'
except:
print('&&&EXCEPTED&&& on item:')
print(json.dumps(jResp, indent=4));
# put json into dataframe
dfS = pandas.json_normalize(jResp)
# collect a list of story dataframes
listDfStories.append(dfS)
dfHeadlines
dfStories = pandas.concat(listDfStories) #turn into a dataframe
See which of the Stories Were Rated
As only a small subset of the stories get rated, and these are of most interest to us, we can start by determining which of the retrieved stories were rated, and include the sentiments:
pandas.set_option('display.max_rows', None)
dfHeadlines
dfHeadlines[['storyId','extCptRel:hasSentimentPositive','extCptRel:hasSentimentNegative','extCptRel:hasSentimentNeutral']]
resulting in:
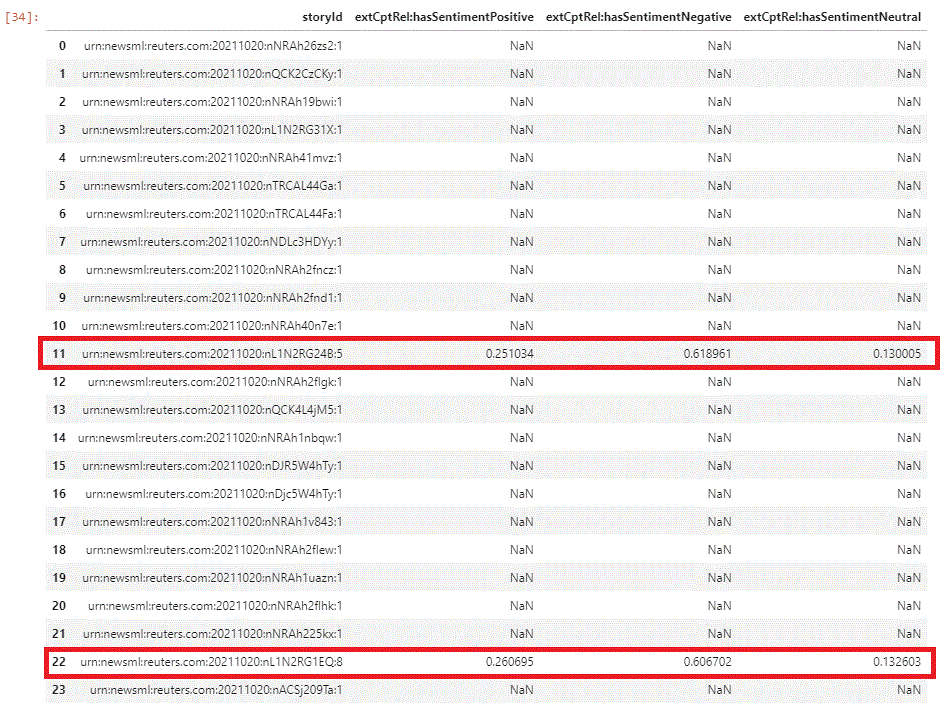
the metadata of the stories that were rated, includes more content and is of more interest to us to examine. We are going to come back to this point shortly...
Get Headlines with Parameters
A very handy and very commonly used parameters define the date interval for the requested headlines:
dfHeadlinesParam = getHeadlines('Google', 50, date_from='2019-10-01T00:00:00Z', date_to='2020-11-15T00:00:00Z')
dfHeadlinesParam
Convenient Retrieval with RDP Library
RDP library can be thought of as ease-of-use and quick-facilitation wrapper for RDP News API that we have the choice of using. It accepts parameters and handles the result pagination. This can be helpful, as the maximum retrieval per headlines request is 100 headlines, so when we need more we have to paginate through the result via next link. So if the request/results is large, it is very convenient to have RDP library python seamlessly handle the pagination aspect:
rdp.open_platform_session(
APP_KEY,
rdp.GrantPassword(
username = RDP_LOGIN,
password = RDP_PASSWORD
)
)
rdp.get_news_headlines(query = 'Google', count = 1000, date_from='2019-10-01', date_to='2020-11-15', sort_order='oldToNew' )
with result being structured consistently, so we can select RDP API or RDP Library for the handling of a specific use case:

Inspect Method Signature
When we wish to verify the parameters that are expected by a method, for example - get_news_headlines we can do so using signature module:
from inspect import signature
t = signature(rdp.get_news_headlines)
print(t)
Let us now see how we can take our review of metadata to the next level with a JSON Viewer.
JSON Viewer PyJSONViewer
We would like to suggest https://github.com/AtsushiSakai/PyJSONViewer
There are several excellent JSON Viewers available in the public space, with many visual interface viewers hosted as online tools, for example:
https://codebeautify.org/jsonviewer
The JSON viewer PyJSONViewer we would like to look at in the next steps is a library, has a simple logical visual representation, and is easily integrated via code.
Examine Single Story with JSON Viewer
We can examine one of the stories from the previously retrieved headlines. It is more interesting to examine one of the stories that were rated, for example, from our retrieved set, story in row 11 with storyId = 'urn:newsml:reuters.com:20211020:nL1N2RG24B:5'
import pyjsonviewer
txt = getStory('urn:newsml:reuters.com:20211020:nL1N2RG24B:5',True)
print(txt)
jResp = json.loads(txt);
pyjsonviewer.view_data(json_data=jResp)
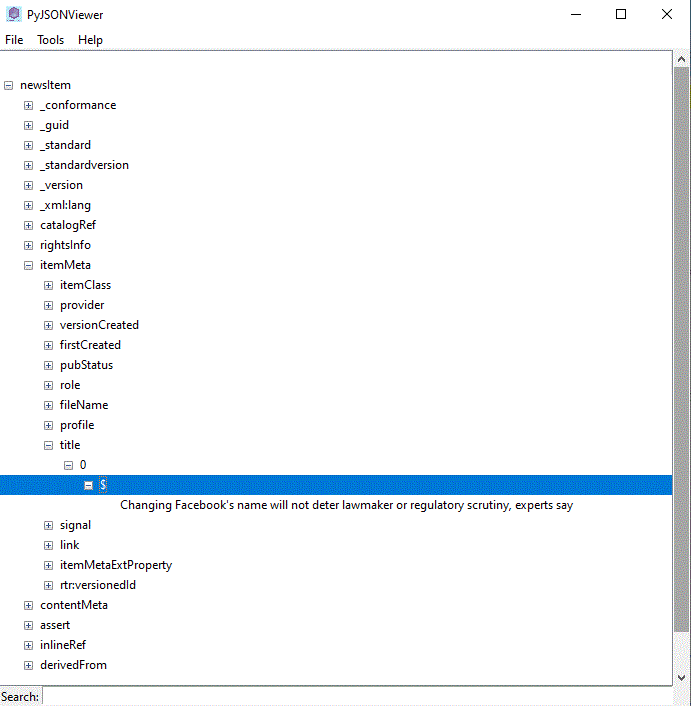
... we can just close the viewer before moving to the next steps
Examine Headlines with Relevant Stories Data with JSON Viewer
1. Convert headlines dataframe to JSON
2. Load JSON
3. Submit it to JSON Viewer
jsn = dfHeadlines.to_json(orient="records")
jsn.replace("\\\"", "\"").strip()
print(jsn)
jResp = json.loads(jsn);
import pyjsonviewer
pyjsonviewer.view_data(json_data=jResp)
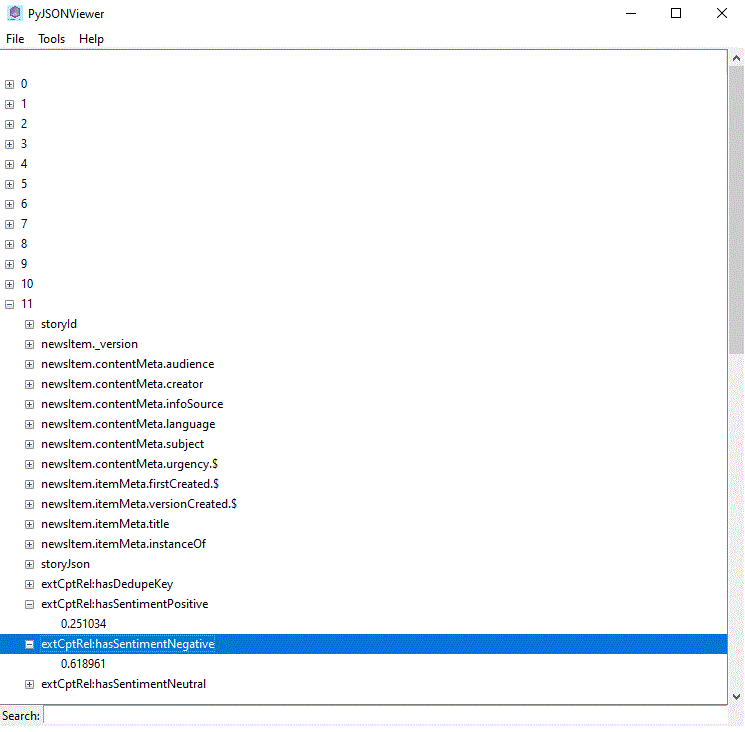
As we dive deeper into the headlines metadata by expanding and collapsing the hierarchical structure, we know exactly where to look for sentiments,
as we have determined in the prior step, in this specific example, they will be present with the headlines in rows 11, 22, and so on.
Examine Stories Metadata with JSON Viewer
In the same way, we can examine the dataframe of the stories we have created, with JSON Viewer.
jsn = dfStories.to_json(orient="records")
jResp = json.loads(jsn);
import pyjsonviewer
pyjsonviewer.view_data(json_data=jResp)
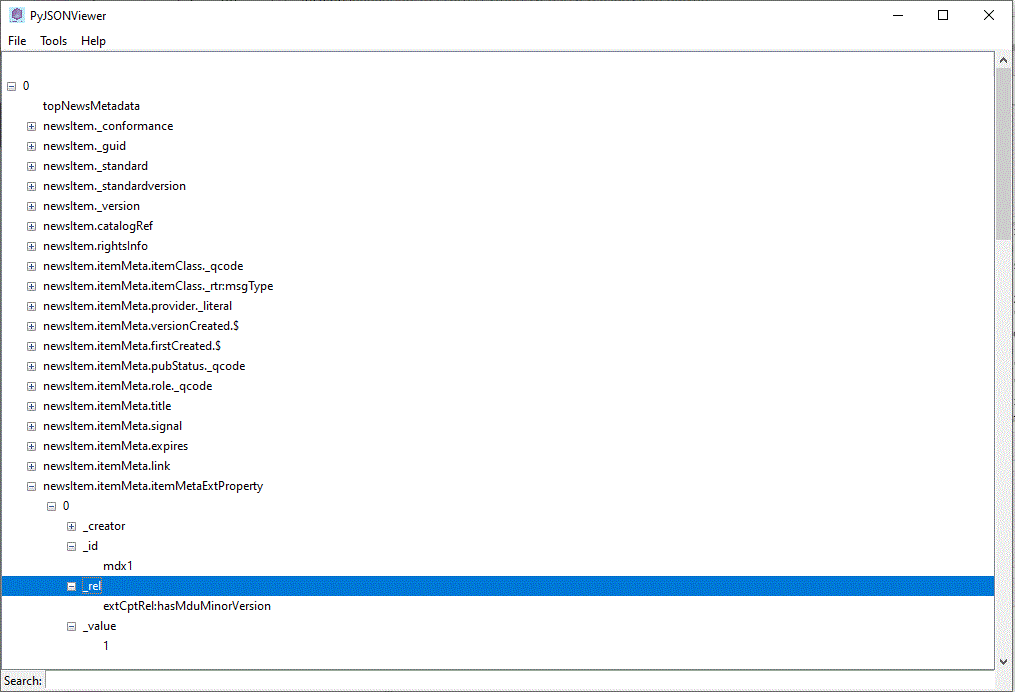
Often, when we are preparing to design a programmatic integration with RDP News, we need to fully understand the structure of the news content we integrate with. News metadata is the key to understanding the news, and JSON Viewer can be very helpful in understanding news metadata, which is often required prior to the programmatic integration and business requirements implementation, and saves time to lookup, as compared to reviewing the specification that is found in User and Design Guide or Reference.
References
- Companion code on GitHub:
https://github.com/Refinitiv-API-Samples/Article.RDP.Python.RDPNewsMetadataWithJsonViewer/
- RDP API News User and Design Guide:
- RDP Library Python
- RDP API Playground - RDP News Reference
- PyJSONViewer by Atsushi Sakai:
https://github.com/AtsushiSakai/PyJSONViewer