Authors:

Introduction
Traditional corporate bond selection strategies frequently rely on credit ratings to assess issuer risk. While these ratings provide a useful benchmark for evaluating creditworthiness, they may not adequately capture interconnected risks arising from supply chain dependencies. This analysis proposes a more nuanced risk management approach by integrating supply chain relationships into the evaluation process for corporate bond issuers.
By analyzing shared suppliers and potential bottlenecks within the value chain, investors can identify hidden risks that credit ratings might overlook. This method allows for improved diversification and risk mitigation within corporate bond portfolios by reducing exposure to systemic supply chain disruptions that could affect multiple issuers simultaneously.
The specific process we will be implmeneting in this notebook is to identify all value chain conflicts within a defined depth (suppliers, suppliers of suppliers etc) - these conflicts are then evalauted with the following risk formula.
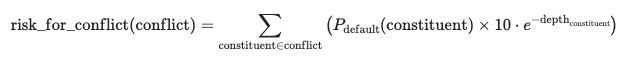
This formula is a simplified approach, evaluating risk by using depth as a proxy for risk attenuation scaled by the probability of default for the common supply chain ancestor. It assumes that greater distance from the ancestor default allows the chain to absorb defaults (represented in the exponential decay in the e term); however, it is worth noting that it is possible that the bullwhip effect actually exacerbates the risk implications. Additionally, this formula does not consider factors such as the availability of substitute suppliers or potential response times. The decision to omit these considerations stems from their unpredictable nature, which would likely require a considerable machine learning solution to estimate reasonably.
Overall portfolio risk is evaluated as the sum of risks from all conflicts:

To illustrate the real world effectiveness of this approach, we will use the SPDR corporate bond portfolio as our diversification candidate. This portfolio has been rated 3 stars by Morningstar, indicating it is "fairly valued."
Imports
Starting off we import the necessary libraries. Here we use the LSEG Data Libraries to retrieve the data. The code is built using Python 3.9. We also define two variables used throughout the code here for simplicity. We also initialise our refinitive data sesssion.
import lseg.data as ld
import copy
import random
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import networkx as nx
import matplotlib.patches as mpatches
from lseg.data.discovery import Suppliers
from datetime import timedelta
from queue import Queue
#import matplotlib.patches as mpatches
ld.get_config()['http.request-timeout'] = 180
significant_conflict_size = 2 # Denotes minimum number of members with common ancestor deemed impermissible
max_depth = 2 # Depth traversed in supply chain to identify number of conflicts in Portfolio
ld.open_session()
Simulated SPBO Corporate Bond Portfolio
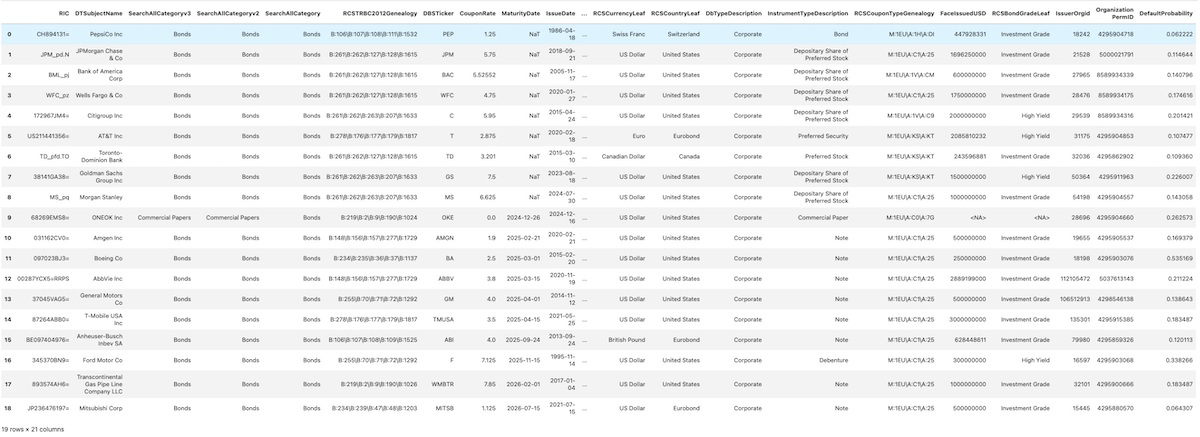
This portfolio is a simulation of the SPBO (S&P U.S. Corporate Bond Index) to demonstrate the real-world applicability of the proposed risk mitigation tool. Here we also migrate from identifying issuers with RICs to with their Organization Permanent IDs, this ensures that the companies themselves are evaluated, rather than the specified bond holdings - and privately traded companies can still be traversed through.
# Generate Example Portfolio, diversified through stratified sampling from different sectors 10 of each from ['Utilities', 'Financials', 'Academic & Educational', 'Healthcare', 'Industrial', 'Real Estate', 'Energy', 'Technology', 'Institutions, Associations & Organisations' ]
for _ in range(3):
try:
Portfolio = ld.discovery.search(
view = ld.discovery.Views.GOV_CORP_INSTRUMENTS,
top = 20,
group_by="IssuerOrgid",
group_count=1,
filter = "(DbType eq 'CORP' and IsActive eq true and ((IssuerOrgid eq '16597' or IssuerOrgid eq '21528' or IssuerOrgid eq '27965' or IssuerOrgid eq '106512913' or IssuerOrgid eq '28476' or IssuerOrgid eq '15445' or IssuerOrgid eq '19655' or IssuerOrgid eq '112105472' or IssuerOrgid eq '18242' or IssuerOrgid eq '31175' or IssuerOrgid eq '54198' or IssuerOrgid eq '79980' or IssuerOrgid eq '29539' or IssuerOrgid eq '135301' or IssuerOrgid eq '27965' or IssuerOrgid eq '18198' or IssuerOrgid eq '32101' or IssuerOrgid eq '28696' or IssuerOrgid eq '50364' or IssuerOrgid eq '32036')))",
select = "RIC, EJVAssetID,DTSubjectName,BusinessEntity,PI,SearchAllCategoryv3,SearchAllCategoryv2,SearchAllCategory,RCSTRBC2012Genealogy, DBSTicker,CouponRate,MaturityDate,IssueDate,ISIN,RCSCurrencyLeaf,RCSCountryLeaf,DbTypeDescription,InstrumentTypeDescription,RCSCouponTypeGenealogy,FaceIssuedUSD,RCSBondGradeLeaf,IssuerOrgid"
)
except Exception as e:
print('Failed to pull Bonds:', e)
print('Retrying...')
# Create lookup-table to both enforce Organization PermID referencing (over instrument), and later remapping back onto bonds in portfolio
for _ in range(3):
try:
portfolio_keys = ld.get_data(universe=(Portfolio['RIC'].tolist()), fields=['TR.OrganizationID']).set_index('Organization PermID')['Instrument'].to_dict()
# Create alternate dictionary with key value pairs swapped
ric_indexed_keys = {v: k for k, v in portfolio_keys.items()}
# Turn the Organization IDs into list format in preparation for the supply chain traversal function
portfolio_orgs = list(portfolio_keys.keys())
# Add Organization PermID to each constituent in portfolio
Portfolio['Organization PermID'] = Portfolio['RIC'].map(
lambda ric: ric_indexed_keys.get(ric)
)
except Exception as e:
print('Failed to pull Permanent Organisation IDs:', e)
print('Retrying...')
Attaching Default probabilities
As part of this process we also define a function to traverse a universe and return a dictionary of all associated default probabilities. Note that <NA> values are filled with the mean values.
"""
Function to query for probability of default for a list of organisations and returns a dictionary of organisations to associated default probability
"""
def find_default_probabilities(universe):
# Add all keys to the queue
heads_queue = Queue()
heads_queue.put(universe)
default_prob_dict = {}
# Attempt to retrieve default probabilities with a queuing system
while not heads_queue.empty():
heads = heads_queue.get()
step = 0
while step < 2:
try:
# Call the API with the current heads
temp_default_probabilities = ld.get_data(universe=heads, fields=['TR.CreditComboCPD'])
# Generate average and fill <NA> values with average
default_probability_average = temp_default_probabilities['Credit Combined PD (%)'].mean()
temp_default_probabilities['Credit Combined PD (%)'].fillna(default_probability_average, inplace=True)
# Update default probabilities with found values
default_prob_dict.update(temp_default_probabilities.set_index('Instrument')['Credit Combined PD (%)'].to_dict())
break
except Exception as e:
print(f"Retrieval Error: Attempts = {step + 1}\n{'Retrying...' if step < 1 else ''}")
# Retrieval failed, split heads and add each half to the queue
if step >= 1:
print(f"Failed to pull Universe: {heads}")
if len(heads) > 1: # Only split if there is more than one head
print("Splitting heads and retrying")
mid_index = len(heads) // 2
heads_queue.put(heads[:mid_index])
heads_queue.put(heads[mid_index:])
else:
default_prob_dict[heads[0]] = np.mean(list(default_prob_dict.values())) # Fill with mean value
print(f"Single head {heads[0]} failed after 2 attempts. Skipping...")
break # Exit the retry loop after splitting
step += 1
return default_prob_dict
default_probabilities = find_default_probabilities(list(portfolio_keys.keys()))
Portfolio['DefaultProbability'] = Portfolio['Organization PermID'].map(
lambda ric: default_probabilities.get(ric)
)
Portfolio
Function Declarations for Value Chain Traversal
The following functions take a list of Permanent IDs for bond issuers in the original portfolio and generate a hierarchical tree of suppliers (or ancestors) within their respective value chains. The output is structured as a dictionary, where each key represents an organization ID, and its corresponding value is another dictionary containing its suppliers. This recursive structure, combined with constant-time lookup, enables efficient navigation and identification of common suppliers or value chain bottlenecks.
A queue-based approach is implemented in the API_call function to manage cases where a large universe of suppliers is requested. When an error occurs, the universe is recursively split into smaller subsets. This strategy is essential because the number of suppliers for each "head" is unknown, and the backend call could involve a significantly larger universe than initially anticipated, necessitating the breakdown of queries. A maximum retry attempt of two has been set, under the assumption that "bad" calls can occur, but they often happen consecutively due to specific problematic members of the "heads" list.
"""
Driver function for value chain exploration
"""
def traverse_value_chains(direction, chains, max_depth):
chain_dict = initialize_chain_dict(chains)
visited_dict = {}
for depth in range(max_depth):
# Retrieve Data and prune unlikely relationships
sdf = retrieve_data(direction, chains)
if sdf.empty:
print("Error Retrieving Data: Exiting")
return chain_dict
sdf = sdf[sdf['Value Chains Relationship Confidence Score'] > 0.5]
chains = []
# Process dataframe to update global data-structures
sdf.apply(lambda row: process_record_deep(row, chain_dict, chains), axis=1)
print(f"Finished layer {depth} Traversal")
return chain_dict
"""
Helper functions for driver
"""
def initialize_chain_dict(chains):
# Return appropriately structured dictionary
return {root[-1]: {} for root in chains}
def process_record_deep(row, chain_dict, chains):
row_chain = row['chain']
newPermID = row['Related OrganizationID']
temp_dict = chain_dict
# Add new constituent to value chain dictionary
for permID in row_chain[:-1]:
temp_dict = temp_dict[permID]
temp_dict[row_chain[-1]][newPermID] = {}
# Add chain to chains array
new_chain = row_chain + [newPermID]
chains.append(new_chain)
def retrieve_data(direction, chains):
sdf = pd.DataFrame()
# Split data into chunks for separate query and concatenate results into main dataframe
for chunk in chunks(chains, 100):
head_and_chain = {chain[-1]: chain for chain in chunk}
sdf = pd.concat([sdf, API_call(direction, head_and_chain)], axis=0)
return sdf
def API_call(direction, head_and_chain):
# Initialize queue with the initial set of heads
head_queue = Queue()
head_queue.put(list(head_and_chain.keys()))
result_df = pd.DataFrame()
while not head_queue.empty():
heads = head_queue.get()
print(f"Processing {len(heads)} heads...")
value_constituents = direction(heads)
step = 0
while step < 2:
try:
# Attempt to retrieve data
value_constituents.get_data()
# Map chains to instruments and append the results
value_constituents.df['chain'] = value_constituents.df['Instrument'].map(head_and_chain)
result_df = pd.concat([result_df, value_constituents.df], ignore_index=True)
break # Exit the retry loop upon successful data retrieval
except Exception as e:
print(f"Retrieval Error: Attempts = {step + 1}\n{'Retrying...' if step < 2 else ''}")
if step >= 1:
print(f"Failed to pull Universe: {heads}")
# On fail, split the list into halves and add them to the queue
if len(heads) > 1: # Only split if there is more than one head
print(f"Splitting heads and retrying")
mid_index = len(heads) // 2
head_queue.put(heads[:mid_index]) # Add the first half to the queue
head_queue.put(heads[mid_index:]) # Add the second half to the queue
else:
print(f"Single head {heads[0]} failed after 2 attempts. Skipping...")
break # Exit the retry loop after splitting
step += 1
return result_df
# chunks function from __Examples__/09.Banking/Analysing_Value_chains.ipynb
def chunks(l, n):
for i in range(0, len(l), n):
yield l[i:i + n]
Generate Data Structure for Supply Chains
Execute the previously defined function traverse_value_chains to generate the supply chain data structure.
portfolio_orgs_chained = [[x] for x in portfolio_orgs]
supply_chains = traverse_value_chains(Suppliers, portfolio_orgs_chained, max_depth)
Processing 19 heads...
Finished layer 0 Traversal
Processing 95 heads...
Processing 96 heads...
Processing 100 heads...
Processing 100 heads...
Processing 98 heads...
Processing 40 heads...
Finished layer 1 Traversal
Weak Point Identification Function (Given Supply Chain Data Structure)
We define a recursive function to traverse the value chains using the provided supply chain data structure. Each unique organization is assigned a key in a lookup dictionary, termed loop_dict, where the value is a list of all bond issuers from the original portfolio that have this organization within their supply chain. This approach ensures an O(n) time complexity for traversing and analyzing the supply chain data.
"""
Recursive function which uses dictionary from traverse_value_chains to identify common anccestors in value chain
"""
def loop_identification(chain_dict, loop_dict=None, source='', depth=0):
# Initialize loop_dict if it's None
if loop_dict is None:
loop_dict = {}
# Base case
if not chain_dict:
return loop_dict
for x in chain_dict.keys():
# Flag to continue recursion (if location unvisited)
traversal = True
if depth == 0:
source = x
# Organisation already visited (from either same source or different source)
if x in loop_dict:
# Check if visited from the same source (update distance if distance from current path smaller)
for y in loop_dict[x]:
if y[0] == source:
traversal = False
if y[1] > depth:
loop_dict[x] = [(source, depth)] # Update the entry
break
else:
break
# Add conflict if visited from the same source
if (traversal):
loop_dict[x].append((source, depth))
# If unvisited, add organization to loop dictionary
else:
if depth != 0:
loop_dict[x] = [(source, depth)]
# Recursive case
if traversal:
loop_identification(chain_dict[x], loop_dict, source, depth + 1)
return loop_dict
Function: `isk_calc
The risk_calc function is designed to assess the risk associated with a bond portfolio by evaluating the contribution of individual portfolio constituents to overall risk, as well as the magnitude of specific conflict scenarios.
Parameters:
- Supply_chains: A data structure representing the relationships between various entities in the supply chain, which can influence risk propagation.
- associated_portfolio: A Pandas DataFrame containing details about the bond portfolio, including organization identifiers and default probabilities.
Description:
This function performs the following key operations:
1. Conflict Identification: It identifies conflicts within the supply chain using the loop_identification function, which captures interdependencies between entities.
2. Pruning Conflicts: The function filters out non-relevant conflicts by retaining only those that meet a specified significant_conflict_size, ensuring that only meaningful conflicts are analyzed.
3. Risk Calculation:
- For each identified conflict, it calculates the risk associated with each offender (i.e., portfolio constituent) by leveraging their default probability and a risk propagation model that includes an exponential decay factor based on the conflict's depth.
- It aggregates the risks at both the individual offender level and the overall conflict level, providing a detailed score for each conflict.
4. Outputs:
- The function returns three values:
- total_risk: The cumulative risk for the entire bond portfolio.
- individual_offender_scores: A dictionary containing the total risk attributed to each offender in the portfolio.
- conflict_scores: A list of tuples, each containing a conflict identifier and its associated risk score.
Purpose:
This function serves as a vital tool for risk assessment in bond portfolios, using conflict supply chain depth as a proxy for risk propagation attenuation and leveraging default probabilities to inform risk metrics. It provides insights into the relative contributions of individual portfolio constituents to overall risk, allowing for informed decision-making and risk management strategies.
def risk_calc(supply_chains, loop_dict, default_probs_dict):
# Check if input dictionaries are None
if supply_chains is None or loop_dict is None or default_probs_dict is None:
raise ValueError("One or more input dictionaries are None.")
# initialise return variables
individual_offender_scores = {}
total_risk = 0
conflict_scores = []
# Iterate through conflicts and update risk recordings
for conflict, offenders in loop_dict.items():
if conflict in default_probs_dict:
offender_default_probability = default_probs_dict[conflict]
else:
offender_default_probability = None
# Use high default probability if None found
if offender_default_probability is None:
offender_default_probability = 1
conflict_score = 0
for offender in offenders:
# Calculate risk contribution by bond issuer
offender_risk = offender_default_probability * 10 * np.exp(-offender[1])
# Update risk recordings
total_risk += offender_risk
conflict_score += offender_risk
if offender[0] in individual_offender_scores:
individual_offender_scores[offender[0]] += offender_risk
else:
individual_offender_scores[offender[0]] = offender_risk
conflict_scores.append((conflict, conflict_score))
# Turn the individual scores into an array so they can be ordered by magnitude
individual_array_scores = [(indv, score if not pd.isna(score) else 0) for indv, score in individual_offender_scores.items()]
individual_array_scores.sort(key=lambda x: x[1])
return total_risk, individual_array_scores, conflict_scores
Generate Dictionary for Identified Weak Points and Corresponding Bonds
Execute the loop_identification function, followed by pruning the resulting dictionary to eliminate conflicts of significant magnitude.
loop_dict = loop_identification(supply_chains)
# Remove non-Point-of-Failure Value Chain Constituents
pruned_loop_dict = {k: v for k, v in loop_dict.items() if (lambda x: len(x) >= significant_conflict_size)(v)}
# Update global default probabilities dictionary with new conflicts
unknown_default_probs = [key for key in list(pruned_loop_dict.keys()) if key not in default_probabilities]
default_probabilities.update(find_default_probabilities(unknown_default_probs))
# Calculate risk
total_risk, individual_offender_scores, conflict_scores = risk_calc(supply_chains, pruned_loop_dict, default_probabilities)
conflict_scores.sort(key=lambda x: x[1])
Graph Example Points of Failure from Portfolio From Each Risk Level
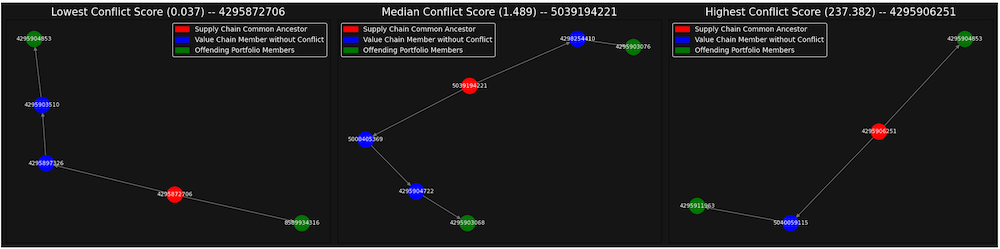
Using networkx and matplot we can visualise a given conflict quite easily. here we can contexualised relative constituents to risk by graphing the lowest risk collision, median risk collision and highest risk collision.
"""
Recursive supply chain dictionary search function to generat
"""
def construct_path(current_dict, destination, path):
if (destination in current_dict) or (current_dict == {}):
return path + [destination]
else:
for x in current_dict.keys():
test_path = construct_path(current_dict[x], destination, path + [x])
if test_path[-1] == destination:
return test_path
return path
def generate_conflict_graph(ax, conflict, loop_dict, risk_level):
# Function call to idenitfy relevant conflict
offenders = [off[0] for off in loop_dict[conflict[0]]]
# Initialise variables for node and edge construction
nodes_to_add = offenders.copy()
edges_to_add = []
# Identify full relevant supply chains from offending portfolio constituents to common ancestor
for offender in offenders:
path = construct_path(supply_chains[offender], conflict[0], [offender])
edges_to_add += [[path[x], path[x-1]] for x in range(1, len(path))]
nodes_to_add += [x for x in path if x not in nodes_to_add]
# Setup Graph
DG = nx.DiGraph()
DG.add_nodes_from(nodes_to_add)
DG.add_edges_from(edges_to_add)
# Update node colours based on supply chain status
node_colors = [
'red' if node == conflict[0]
else 'green' if node in offenders
else 'blue'
for node in DG.nodes()
]
# Draw graph and add stylings
nx.draw_networkx(
DG,
with_labels=True,
node_color=node_colors,
edge_color='grey',
font_color='white',
node_size=500,
font_size=8,
ax=ax
)
ax.set_facecolor('#151515')
ax.set_title(f'{risk_level} Conflict Score ({round(conflict[1], 3)}) -- {conflict[0]}', fontsize=15, color='white')
red_patch = mpatches.Patch(color='red', label='Supply Chain Common Ancestor')
blue_patch = mpatches.Patch(color='blue', label='Value Chain Member without Conflict')
green_patch = mpatches.Patch(color='green', label='Offending Portfolio Members')
ax.legend(
handles=[red_patch, blue_patch, green_patch],
facecolor='#151515',
edgecolor='white',
fontsize=10,
labelcolor='white'
)
# Generate the figure with subplots
fig, axes = plt.subplots(1, 3, figsize=(20, 5))
# Generate and plot each graph on its respective subplot
generate_conflict_graph(axes[0], conflict_scores[0], pruned_loop_dict, "Lowest")
generate_conflict_graph(axes[1], conflict_scores[len(conflict_scores)//2], pruned_loop_dict, "Median")
generate_conflict_graph(axes[2], conflict_scores[-1], pruned_loop_dict, "Highest")
fig.patch.set_facecolor('#151515')
for ax in axes:
ax.set_facecolor('#151515')
plt.tight_layout()
plt.show()
Split Portfolio into Remaining Bonds and Bonds to be Reselected
Using the individual offender scores, we can identify the largest contributors to overall portfolio risk and isolate the top offenders based on a specified percentage of the total risk we aim to eliminate. It’s important to note that attempting to eliminate all risk could result in selecting very small contributors, which might inadvertently introduce additional risk into the portfolio.
tot = 0
index = -1
target_risk_removal = 0.8 # Change to be whatever percentage you wish
diversified_permIDs = []
while tot < total_risk * target_risk_removal:
offender = individual_offender_scores[index]
if offender[1] < (total_risk * 0.03):
break
else:
diversified_permIDs.append(offender[0])
tot += offender[1]
index -= 1
diversified = Portfolio[Portfolio['Organization PermID'].isin(diversified_permIDs)]
remaining = Portfolio[~Portfolio['Organization PermID'].isin(diversified_permIDs)]
# Remove diversified bonds from supply chain dictionary
for org in diversified_permIDs:
del supply_chains[org]
DataFrames of 'insecure' Bonds
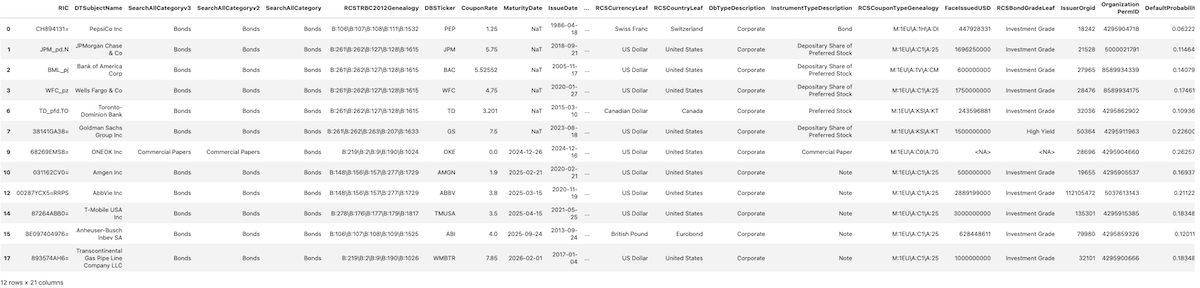
diversified

DataFrame of 'Secure' Bonds
remaining
Query for Replacement Bond Suggestions
For each bond identified for replacement, candidate alternatives can be generated by querying the Refinitiv Data API. Filters will be applied to ensure that the replacement bonds align closely with the attributes of the original bond, including sector, coupon rate, and maturity date. This methodology establishes a targeted search space, consisting of a set of bonds, from which replacements can be selected to minimize supply chain conflicts.
# Domain expansion hyperparameters
coupon_allowance_range = 1
maturity_date_allowance_range = 30
"""
Row-wise function to construct query for similar bonds
"""
def construct_query(row, attempts, filters):
coupon = row['CouponRate']
# Constructing the base query
query = (f"(DbType eq 'CORP' and IsActive eq true and InstrumentTypeDescription xeq 'Bond' "
f"and CouponRate ge {abs(coupon - (attempts + 1) * coupon_allowance_range)} and "
f"CouponRate le {coupon + (attempts + 1) * coupon_allowance_range}")
# Adding sector filter if available
sector = row['RCSTRBC2012Genealogy']
if pd.notna(sector):
sector = '(\'' + "' '".join(sector.split('\\')) + '\')'
query += f" and RCSTRBC2012Genealogy in {sector}"
# Adding maturity date filter if available
maturity = row['MaturityDate']
if pd.notna(maturity):
input_date = maturity.date()
start_date = (input_date - timedelta(days=maturity_date_allowance_range * (attempts + 1))).strftime("%Y-%m-%d")
end_date = (input_date + timedelta(days=maturity_date_allowance_range * (attempts + 1))).strftime("%Y-%m-%d")
query += (f" and MaturityDate ge {start_date} and MaturityDate le {end_date}")
query += ')'
# Append the constructed query to filters
filters.append(query)
"""
Construction of DataFrame for Bond Diversification suggestions
"""
def bond_replacement_generation(replacements_dataframe):
# Skip empty dataframes
if replacements_dataframe.empty:
return replacements_dataframe
attempts = 1
replacement_candidates = pd.DataFrame()
while attempts < 3:
try:
# Instantiate empty set of filters to query for new bond replacements
filters = []
# For each record (bond) to replace, generate relevant filter/query
replacements_dataframe.apply(lambda row: construct_query(row, attempts, filters), axis=1)
# Make API call with reference to bond it attempts to replace
for x in range(replacements_dataframe.shape[0]):
ndf = ld.discovery.search(view=ld.discovery.Views.GOV_CORP_INSTRUMENTS, top=30, filter=filters[x],
select="RIC,EJVAssetID,DTSubjectName,BusinessEntity,PI,SearchAllCategoryv3,SearchAllCategoryv2,SearchAllCategory,"
"DBSTicker,CouponRate,MaturityDate,IssueDate,ISIN,RCSCurrencyLeaf,RCSCountryLeaf,"
"DbTypeDescription,InstrumentTypeDescription,RCSCouponTypeGenealogy,FaceIssuedUSD,RCSBondGradeLeaf,"
"RCSTRBC2012Leaf,IndustrySubSectorDescription,RCSCouponCurrencyLeaf,RCSCurrency,RCSTRBC2012Genealogy")
# If no replacement bonds, keep original
if ndf.shape[0] == 0:
pd.concat([ndf, replacements_dataframe.iloc[x]])
else:
ndf = ndf[~ndf['RIC'].isin(Portfolio['RIC'].tolist())]
ndf['Replacee'] = replacements_dataframe.iloc[x]['RIC']
replacement_candidates = pd.concat([replacement_candidates, ndf])
# Make Replacee the first column
columns = ['Replacee'] + [col for col in replacement_candidates.columns if col != 'Replacee']
replacement_candidates = replacement_candidates[columns]
break
except ld.errors.RDError as e:
replacement_candidates = pd.DataFrame()
retry = "\nRetrying..." if attempts < 3 else ''
print(f"Retrieval Error: Attempts = {attempts}{retry}")
print(e)
attempts += 1
# Remove records with erroneous or missing data
replacement_candidates = replacement_candidates.drop_duplicates(subset=['RIC'])
replacement_candidates = replacement_candidates.dropna(subset=['RIC'])
return replacement_candidates
# Generate bond replacements for each priority level
replacement_candidates = bond_replacement_generation(diversified)
Append 'Organization PermID' Column for Portfolio Optimization Methods
By appending each organization's Permanent ID (PermID) to the corresponding record, each bond can be uniquely indexed and efficiently queried. This step ensures that portfolio optimization methods can accurately track and analyze each issuer throughout the optimization process.
def add_PermIDs(replacement_candidates):
# Return nothing if empty
if replacement_candidates.empty:
return replacement_candidates
# Query for replacementIds
for _ in range(3):
try:
replacee_keys = ld.get_data(universe=(replacement_candidates['RIC'].tolist()), fields=['TR.OrganizationID']).set_index('Instrument')['Organization PermID'].to_dict()
replacement_candidates['Organization PermID'] = replacement_candidates['RIC'].map(
lambda ric: replacee_keys.get(ric)
)
except Exception as e:
print('Failed to pull Permanent Organisation IDs:', e)
print('Retrying...')
return replacement_candidates
replacement_candidates = add_PermIDs(replacement_candidates)
# Filter out rows where Organization PermID is in exclusions or original portfolio
replacement_candidates = replacement_candidates[~replacement_candidates['Organization PermID'].isin(Portfolio['Organization PermID'])]
Resultant DataFrames
'Replacee' column denotes bond in original portfolio which is suggested to change. Each record then denotes the bond recommended as the replacement.
replacement_candidates
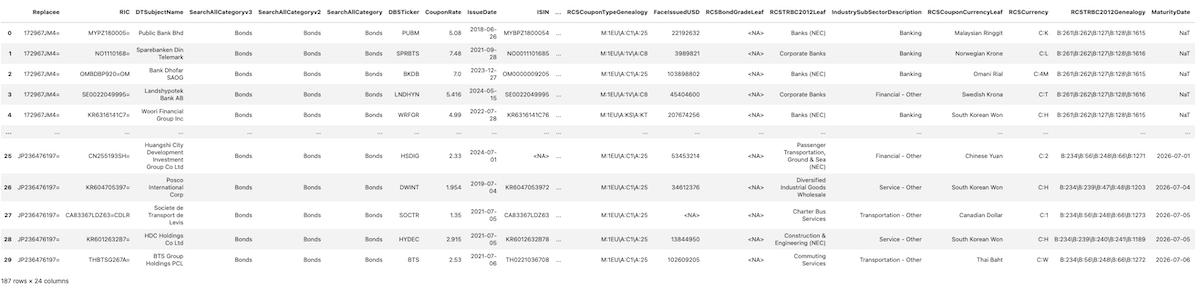
Traversing Replacement Candidates' Supply Chains
To optimize the selection of replacement bonds, it is essential to evaluate their supply chains in the same manner as the original bonds. The following code block performs this by traversing the suppliers of each candidate bond to generate its supply chain structure. This process ensures that the chosen replacement bonds will minimize conflicts with the existing portfolio.
replacement_orgs_chained = [[org] for org in replacement_candidates['Organization PermID'].tolist()]
replacement_supply_chains = traverse_value_chains(Suppliers, replacement_orgs_chained, max_depth)
Processing 84 heads...
Processing 78 heads...
Finished layer 0 Traversal
Processing 61 heads...
Finished layer 1 Traversal
Create Dictionary of Replacement Bonds
To facilitate efficient conflict testing and portfolio optimization, the replacement bonds are organized into a dictionary based on the 'replacee' RIC (Reference Identification Code) of the original bonds. This approach enables easy management and analysis of replacement options for each bond in the original portfolio.
def form_dict(row, temp_dict):
temp_dict[row['Organization PermID']] = copy.deepcopy(replacement_supply_chains[row['Organization PermID']])
def instantiate_candidate_dicts(replacement_candidates):
if replacement_candidates.empty:
return {}
candidate_dicts = {}
for replacee in replacement_candidates['Replacee'].unique():
temp_dict = {}
subset_df = replacement_candidates[replacement_candidates['Replacee'] == replacee]
subset_df.apply(lambda row: form_dict(row, temp_dict), axis=1)
candidate_dicts[replacee] = temp_dict
return candidate_dicts
candidate_dicts = instantiate_candidate_dicts(replacement_candidates)
Greedy Portfolio Optimisation Function Definitions
Here I provide a Greedy Portfolio Optimisation method. Individual solutions for different common ancestor depth categories are generated in decreasing order of risk (and therefore priority) - thereby ensuring that higher priority risks are resolved first. A greedy algorithm performs admirably in this context due to the limited scope of the search space (shallow supplier traversal depth). You could explore alternative optimisation methods - however, after trialling a genetic generation method, generated solutions severely underperformed in both generation time and risk reduction performance.
def fitness(sub_dict, supply_chains, default_probabilities):
# Combine the original supply chains with the current subset
trial_dict = {**supply_chains, **sub_dict}
# Find conflict present in specific replacement trial
trial_loop_dict = loop_identification(trial_dict)
trial_pruned_loop_dict = {k: v for k, v in trial_loop_dict.items() if len(v) >= significant_conflict_size}
# Evaluate performance with risk_calc function
total_risk, individual_offender_scores, conflict_scores = risk_calc(trial_dict, trial_pruned_loop_dict, default_probabilities)
return total_risk
def greedy_generation(candidate_dicts, supply_chains, order, default_probabilities):
choices = []
for ric in order:
sub_dict = candidate_dicts[ric]
# make new supply chains dict with all replacement candidate orgs so all possible conflict default probabilities can be found in one batch call
default_prob_dict = copy.deepcopy(supply_chains)
for org in sub_dict.keys():
default_prob_dict[org] = sub_dict[org]
# Identify loops and prune based on conflict size
loop_dict = loop_identification(default_prob_dict)
trial_pruned_loop_dict = {k: v for k, v in loop_dict.items() if len(v) >= significant_conflict_size}
# Update global default probabilities for conflicts with unknown default probability
unknown_default_probs = [key for key in list(trial_pruned_loop_dict.keys()) if key not in default_probabilities]
if len(unknown_default_probs) != 0:
default_probabilities.update(find_default_probabilities(unknown_default_probs))
# Find the organization with the minimum risk score
min_org = min(sub_dict.keys(), key=lambda org: fitness({org: sub_dict[org]}, supply_chains, default_probabilities))
# Select the organization with the highest fitness (minimum risk) and fold into dictionary for next iteration
choices.append(min_org)
supply_chains[min_org] = sub_dict[min_org]
return choices
Generate the solution
# Generate solution in order of highest offending portfolio constituent
order = [portfolio_keys[val] for val in diversified_permIDs]
best_solution = greedy_generation(candidate_dicts, supply_chains, order, default_probabilities)
Generate New Portfolio
Once the solution is generated using either the Greedy or Genetic Algorithm, it is used to update the portfolio. The generated replacement bonds are mapped to the previously created 'diversified' DataFrame, which uses the Perm OrganizationID as the index. This approach ensures that the replacement bonds are efficiently integrated into the new portfolio without the need to re-query the API.
replacements = replacement_candidates[replacement_candidates['Organization PermID'].isin(best_solution)]
nPortfolio = pd.concat([remaining, replacements])
nPortfolio
Portfolio
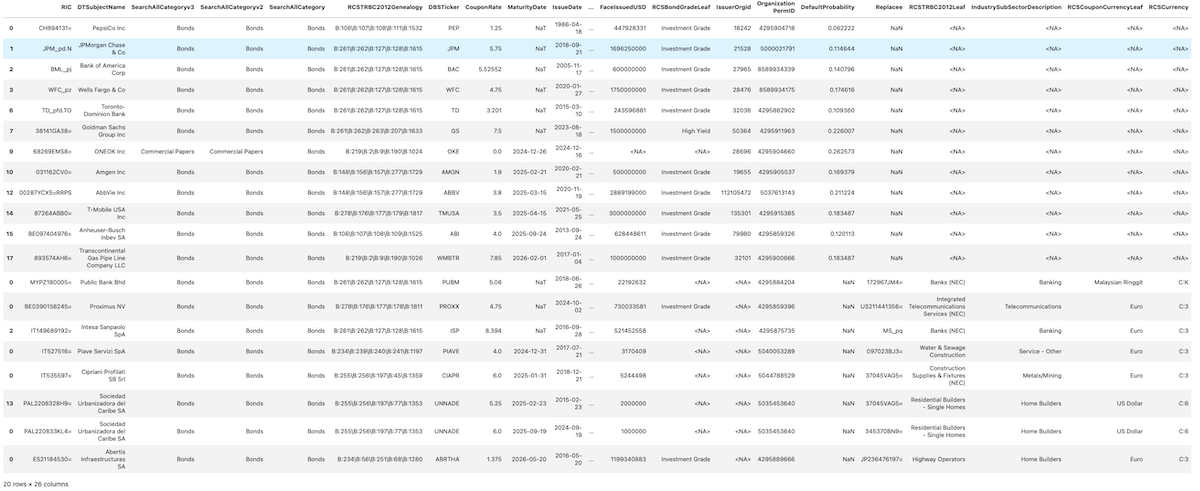
Test Conflicts
Here we evaluate our diversified portfolio and compare to the original portfolio.
# Generate evaluation metrics for new portfolio
new_loop_dict = loop_identification(supply_chains)
# Remove non-Point-of-Failure Value Chain Constituents
new_pruned_loop_dict = {k: v for k, v in new_loop_dict.items() if (lambda x: len(x) >= significant_conflict_size)(v)}
# Update global default probabilities with found conflicts
unknown_default_probs = [key for key in list(new_pruned_loop_dict.keys()) if key not in default_probabilities]
if len(unknown_default_probs) != 0:
default_probabilities.update(find_default_probabilities(unknown_default_probs))
# Calculate risk
new_total_risk, new_individual_offender_scores, new_conflict_scores = risk_calc(supply_chains, new_pruned_loop_dict, default_probabilities)
print(f"Old Portfolio Risk {total_risk}")
print(f"New Portfolio Risk: {new_total_risk}")
Old Portfolio Risk 1358.2636037941552
New Portfolio Risk: 41.808608505143695
- Register or Log in to applaud this article
- Let the author know how much this article helped you