
AUTHOR:


Introduction
The Refinitiv Data Library (RD Library) Search API extends its capabilities to LSEG desktop users, enabling them to programmatically explore an expansive repository of high-quality financial content, spanning various asset classes such as bonds, equities, FX, organizations, individuals, and more. A comprehensive tutorial on utilizing the RD Library Search API has been meticulously crafted by Nick Zincone, available here.
Large Language Models (LLMs) such as OpenAI's GPT, Meta's Llama2, and Google's Bard are sophisticated AI models that have been extensively trained on vast textual datasets. They possess the ability to discern patterns in natural language, generate coherent text, and provide insights across a wide spectrum of subjects.
LangChain emerges as an open-source integration framework designed to seamlessly connect LLM models with external data sources and environments. It facilitates the interaction between LLMs and their surroundings, enhancing their versatility.
The Copilot concept, pioneered by Microsoft in the age of Large Language Models, seeks to create a harmonious and collaborative interplay between human and machine intelligence. It aspires to forge a fluid synergy where both entities complement each other's strengths.
In this article, we embark on an exploration of a Bond Copilot solution powered by an integration of RD Library Search API, LLM, and Langchain, which provides a conversational bond consulting service that can potentially help financial professionals unlocking productivity.
Disclaimer
The source presented here as well as the example code provided has been written by Refinitiv, an LSEG business for the only purpose of illustrating an article published on the Developer Community. They have not been tested for usage in production environments. Refinitiv cannot be held responsible for any issues that may happen if these objects or the related source code is used in production or any other customer's environment.
Prerequisites
- LSEG Workspace application with an access for RD library desktop session, or RDP account for platform session
- An API key generated by App Key application in Workspace.
- Select an LLM from Hugging Face or request access to the OpenAI API
- As we're using ChatGPT, an AI-powered language model developed by OpenAI in this article, follow steps below to get an Open AI API key
1 ) In Open API Platform, click on your profile (Personal) > View API keys
2) Click "Create new secret key" button
3) Enter an API key name then click "Create secret key" button
4) Copy the API key generated to be used (Do not share the API key with others and please note that they don't display your secret API key again after you generate it)
- As we're using ChatGPT, an AI-powered language model developed by OpenAI in this article, follow steps below to get an Open AI API key
- Python 3.9 or above
- Python libraries
Architecture
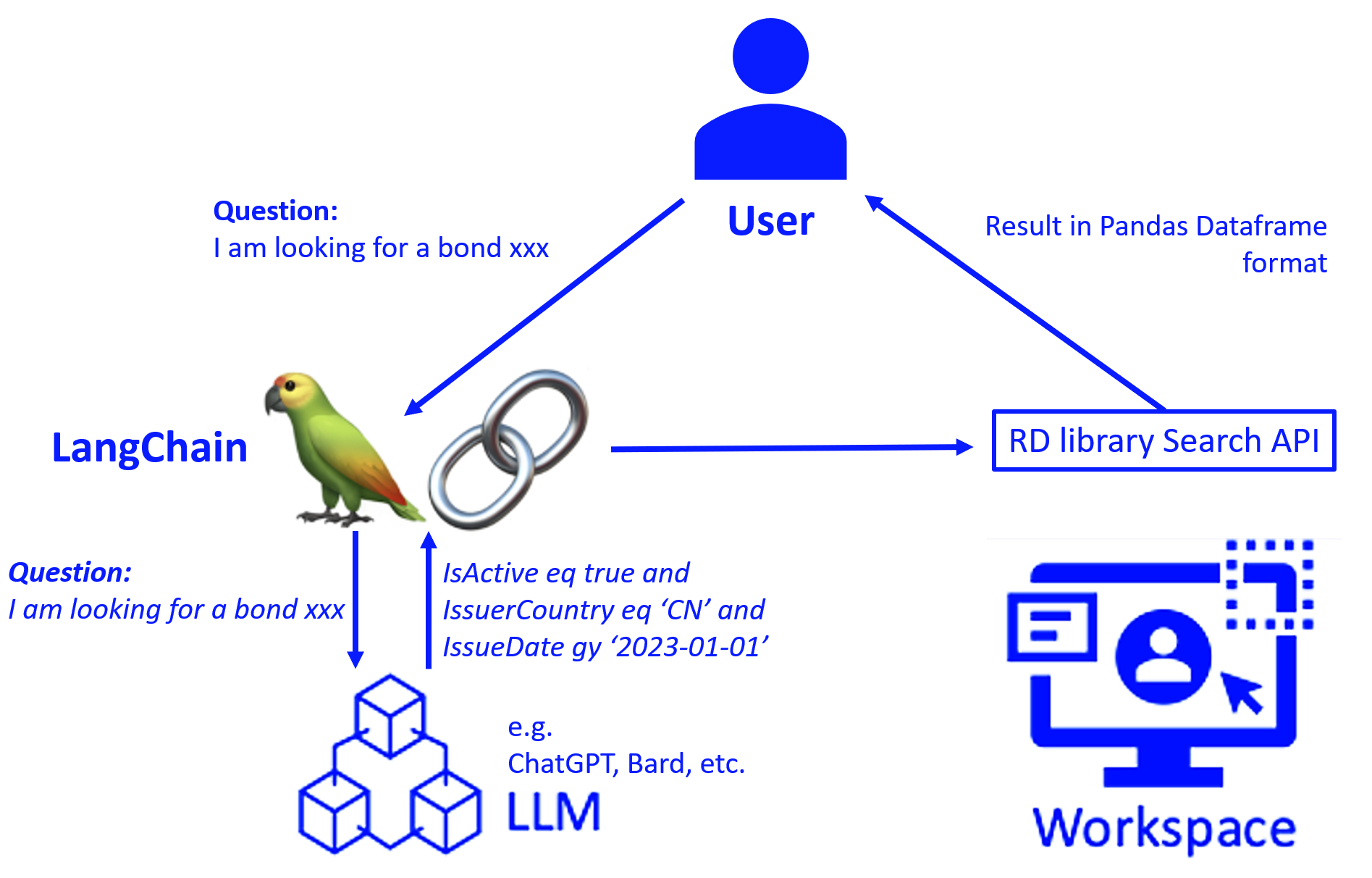
LangChain Coordination
To smoothly handle multi-turn conversations, Bond Copilot incorporates Langchain to coordinate the interaction between the front-end nature language query and LLM, maintaining context and directing prompts to large language models. Langchain removes the complexity of conversing with AI, making the technology more practical and scalable.
Large Language Model
Under the hood, Bond Copilot leverages large language models to understand the context and intent and convert nature language query into RD Library Search API.
RD Library Search API
To enable robust AI insights, Bond Copilot connects to LSEG's RD Library Search API. This provides direct access to LSEG's vast fixed income information including real-time pricing, reference data and more. By leveraging comprehensive, timely data, the quality of Copilot's analytics is significantly enhanced.
Conversational Search
Define you bond search function
To begin, it is imperative to craft a bond search function named 'ws_bond_search,' harnessing the capabilities of the RD Library Search API. We could potentially employ the function outlined in the subsequent comments to acquire bond metadata, an essential step in formulating the API search function. The variable 'query' assumes a pivotal role, serving as the conduit for stipulating the criteria for retrieving bond-related information.
For more detail regarding RD library and how to configure it, please check the Getting started with Refinitiv Data Library for Python guide
# Imports the RD library
import refinitiv.data as rd
from refinitiv.data.content import search
# Initialize the session with the RD library, using a configuration file to set up the connection.
rd.open_session(config_name="path/to/your/config/file/refinitiv-data.config.json")
"""
Search function: The code below It can be used to retrieve metadata about government and corporate bonds
to help construct your search queries by defining 'filter' and 'select' parameters in your search query
response = search.metadata.Definition(
view = search.Views.GOV_CORP_INSTRUMENTS
).get_data()
response.data.df
"""
# The function below is designed to search for bonds based on a query input.
# It will return a dataframe with information about bonds that match the criteria specified in the query.
def ws_bond_search(query):
df = rd.discovery.search(
# Specifies the database view we are searching in.
view = search.Views.GOV_CORP_INSTRUMENTS,
# Limits the results to the top 10,000 matches.
top = 10000,
# Applies the query filters to narrow down the search results.
filter = query,
# Selects specific data columns to be included in the output.
select = '''
RIC,
ISIN,
IssueDate,
FaceIssuedTotal,
EOMAmountOutstanding,
CouponRate,
CouponCurrency,
CouponFrequency,
CurrentYield,
EOMPrice,
IssuePrice,
MaturityAverageLife,
MaturityAverageLifeDate,
ISOCountryName,
IssuerLegalName,
IssuerCountry,
MaturityDate,
AssetStatus,
IsActive,
IsGreenBond
''',
order_by = "IssueDate"
)
# Returns the data frame with the search results.
return df
Define Few-Shot prompt template
Moving forward, the subsequent stride involves the creation of a function named 'bond_copilot.' This function assumes the task of translating a query presented in natural language into a filter suitable for the RD Library Search API, facilitated by the Few-Shot Prompt Template. This resulting filter subsequently serves as a parameter for the 'ws_bond_search' function.
The concept of 'Few-shot' denotes a remarkable capability conferred by LLMs. It enables tasks to be accomplished using merely a limited number of examples or data "shots" and natural Language is becoming a programming language to preform prompt engineering tasks
In the code below, replace YOUR OPENAI API KEY with your valid OpenAI API key
# Import several modules that help us in generating queries using natural language processing.
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
#from langchain.llms import LlamaCpp
from langchain.chat_models import ChatOpenAI
# This function takes a user's question as a input and generates a query filter for searching bonds with the RD library.
def bond_copilot(question):
# The template below guides the construction of the query based on the user's input.
template = """
This is a tool to generate the filter in RD Library search api, for example:
Question: I'm looking for all US Corporate Bonds that have a minimum outstanding amount of 1,000,000 in the Biotechnology Industry and are maturing no earlier than 10 years"
Answer: RCSTRBC2012Name eq 'Biotechnology & Medical Research' and MaturityDate gt 2030-01-01 and IssuerCountry eq 'US' and EOMAmountOutstanding gt 1000000
Comments:
1) IssuerCountry is Country Code: Unite State - US; China - CN; Europe - EU
2) RCSTRBC2012Name is industry classification code: Biotechnology & Medical Research, Software & IT Services, Real Estate Operations(Chinese is 房地产) etc.
3) Green Bond: IsGreenBond eq true
Here is the list of all query fields and datatype:
RIC string[python]
ISIN string[python]
IssueDate datetime64[ns]
FaceIssuedTotal Int64
EOMAmountOutstanding Int64
CouponRate Float64
CouponCurrency string[python]
CouponFrequency Int64
CurrentYield Float64
EOMPrice Float64
IssuePrice Float64
MaturityAverageLife Float64
MaturityAverageLifeDate datetime64[ns]
IssuerLegalName string[python]
IssuerCountry string[python]
MaturityDate datetime64[ns]
AssetStatus string[python]
IsActive boolean
IsGreenBond boolean
Reference grammar: = is eq; > is gt, < is lt
Please output answer directly without any comments
QUESTION: {question}
ANSWER:
"""
prompt = PromptTemplate(input_variables=["question"], template=template)
# Initialize the language model that will help in generating the query.
llm = ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo', openai_api_key='YOUR OPENAI API KEY')
# Creates a chain of processes to generate the query using the language model.
llm_chain = LLMChain(llm=llm, prompt=prompt)
# This block generates the query filter based on the user's input and then uses it to search for bonds.
my_filter = llm_chain(question)
print(my_filter['text'])
# Uses the generated query to search for bonds and returns the results.
return ws_bond_search(my_filter['text'])
Begin the journey of “bond copilot”
We are now poised to embark on the "Bond Copilot" journey across a vast expanse of more than 12 million global corporate and government bond entries.
Question One: “I am looking for a bond whose Isin is XS2404581527”
Query generated by the model is ISIN eq 'XS2404581527', the result of the Search API in Pandas dataframe is shown below

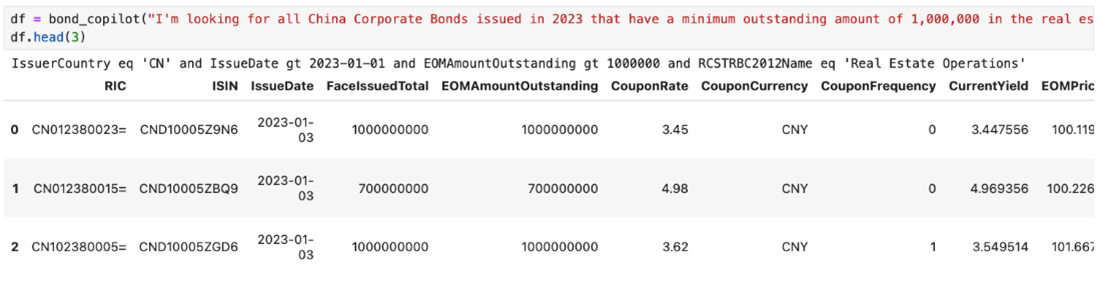
Question Two: “I am looking for all China Corporate Bonds issued in 2023 that have a minimum outstanding amount of 1,000,000 in the real estate”
Query generated is IssuerCountry eq 'CN' and IssueDate gt 2023-01-01 and EOMAmountOutstanding gt 1000000 and RCSTRBC2012Name eq 'Real Estate Operations', and got the result as below
Multi-Language Support
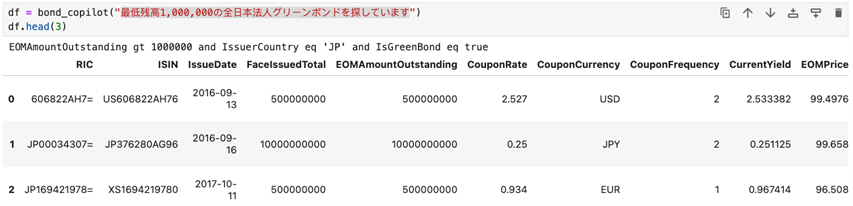
Chinese query of “List green bonds issued by US real estate companies”

Japanese query of “Looking for green bonds issued by Japanese corporations with a minimum balance of 1,000,000 yen”
Summary and Outlook
Within the context of this article, we present a groundbreaking solution - the Bond Copilot - and illustrate how it harnesses the immense potential of large language models in conjunction with the LangChain framework. The objective is to empower users with the ability to seamlessly navigate a vast array of over 12 million trust bond instruments data using natural language. Furthermore, we showcase the utilization of the LangChain Agent for meticulous bond data analysis. Despite the strides made, the realm of complex bond markets remains rife with challenges.
Relying upon the outputs of large language models within the financial sector is not without its intricacies. Delays in data updates, the limited financial domain acumen of these models, and the difficulty in verifying responses - as these models invariably generate an answer, even if erroneous - all contribute to the complexity.
Consequently, the provision of high-quality financial data by LSEG (London Stock Exchange Group) is pivotal in rendering LLM (large language model) services to financial professionals. The RD Library Search API emerges as a robust avenue for accessing an expansive repository of fixed income data, encompassing real-time prices, reference data, and furnishing AI-driven analyses with precise, up-to-the-minute data.
The solution detailed within this article underscores the LLM's specialization in natural language processing tasks, thereby harnessing its inherent proficiency. The insights, derived from the LSEG's trusted data repository via the RD Library Search API, fortify the responses generated.
Utilizing a conversational interface rather than a traditional search user interface allows customers to directly manipulate data through natural language. This avoids complex UI operations and makes it easier and more efficient for customers to use data.
It is imperative to acknowledge that larger LLM isn't invariably synonymous with better, as considerations regarding the associated costs necessitate prudence. For instance, small models with 6 or 7 billion parameters, through fine-tuning, can still be utilized to address specific business challenges at a lower cost and tried both GPT 3.5 and Llama 7B in this case.
The ascent of large language models has indubitably revolutionized our interaction with financial data. The fusion of natural language comprehension with these models has simplified the information acquisition process for analysts. By enabling them to pose inquiries and receive intricate insights into financial markets, the advent of advanced AI tools grounded in LLM technology is dynamically reshaping the roles of financial analysts, investors, and risk managers. This paradigm shift enhances their capacity to navigate complex information with heightened efficiency and efficacy.
Reference
For any questions related to the RD library usage, feel free to visit or ask you question in the Developers Community Q&A Forum.
- Register or Log in to applaud this article
- Let the author know how much this article helped you