
Last Updated: May 2025
Introduction
The goal of this article is to demonstrate the LSEG Data Library for Python with the focus on the news retrieval in a Jupyter Notebook environment. So, for that purpose we are going to look at new issue news from International Financial Review (IFR), a global capital markets intelligence provider, that is a part of LSEG.
We will capture the PRICED or DEAL notifications that contain structured text that we will extract.
Before we start, let's make sure that:
- LSEG Workspace desktop application is up and running;
- LSEG Data Library for Python is installed;
- You have created an application ID for this script.
If you have not yet done this, have a look at the quick start section for this API.
A general note on the Jupyter Notebook usage: in order to execute the code in the cell, press Shift+Enter. While notebook is busy running your code, the cell will look like this: In [*]. When its finished, you will see it change to the sequence number of the task and the output, if any.
For more info on the Jupyter Notebook, check out Project Jupyter site http://jupyter.org or 'How to set up a Python development environment for Workspace' tutorial on the Developer Community portal.
Getting started
Let's start with referencing LSEG Data Library for Python and pandas:
import lseg.data as ld
import pandas as pd
import os
app_key = os.getenv("APP_KEY")
Paste your application ID in to this line:
ld.open_session(app_key=app_key)
We are going to request emerging market new issue (ISU) Eurobond (EUB) news from International Financial Review Emerging EMEA service (IFREM), focusing on the notifications of the already priced issues. You can replicate this request in the News Monitor app with the following query:
- Product:IFREM AND Topic:ISU AND Topic:EUB AND ("PRICED" OR "DEAL")
from datetime import date
start_date, end_date = date(2024, 1, 1), date.today()
q = 'Product:IFREM AND Topic:ISU AND Topic:EUB AND (\"PRICED:\" OR \"DEAL:\")'
headlines = ld.news.get_headlines(q,start=start_date,end=end_date, count = 100)
headlines.head()
| headline | storyId | sourceCode | |
|---|---|---|---|
| versionCreated | |||
| 2025-04-24 13:46:03.012 | PRICED: LHV Group €50m PNC5 AT1 | urn:newsml:reuters.com:20250424:nIfp7mMCSV:1 | NS:IFR |
| 2025-04-24 12:03:55.000 | UPDATE PRICED: OCP 750m 5yr &750m 5yr &1bn long 10yr | urn:newsml:reuters.com:20250424:nIfp6SWcZk:1 | NS:IFR |
| 2025-04-24 12:03:55.000 | UPDATE PRICED: OCP 750m 5yr &750m 5yr &1bn long 10yr | urn:newsml:reuters.com:20250424:nIfp4fJ3xZ:1 | NS:IFR |
| 2025-04-24 07:10:00.000 | UPDATE PRICED: OCP 750m 5yr &750m 5yr &1bn long 10yr | urn:newsml:reuters.com:20250424:nIfp401Bg9:1 | NS:IFR |
| 2025-04-24 07:10:00.000 | UPDATE PRICED: OCP 750m 5yr &750m 5yr &1bn long 10yr | urn:newsml:reuters.com:20250424:nIfp2kcCRd:1 | NS:IFR |
from IPython.core.display import HTML
html_doc = ld.news.get_story(headlines['storyId'][1])
HTML(html_doc)
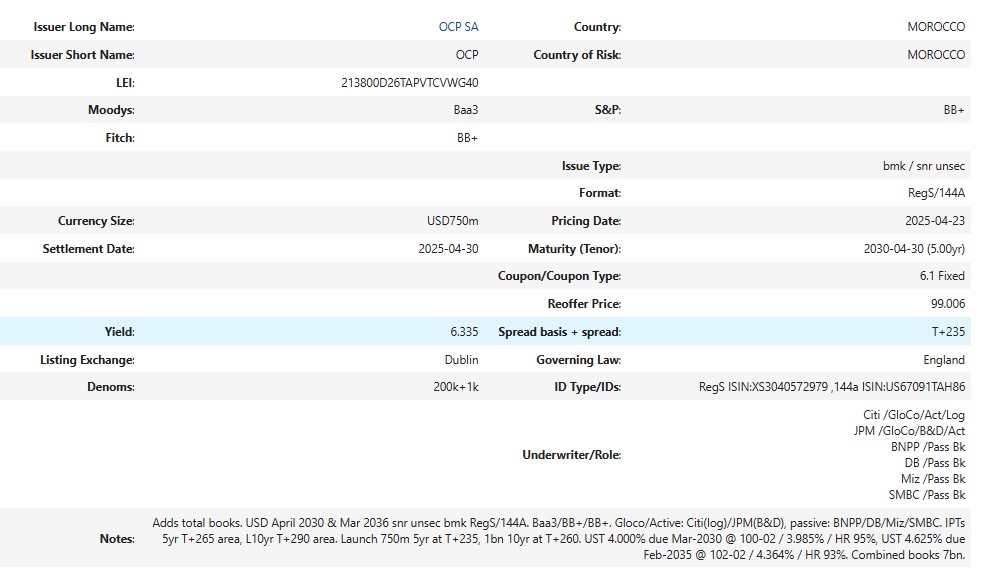
Now we can parse the data using a BeautifulSoup module. Let's create a function that is going to return a dictionary from the this type of article.
from bs4 import BeautifulSoup
def termsheet_to_dict(html_doc):
clean_matches = {}
soup = BeautifulSoup(html_doc, 'html.parser')
for tr in soup.find_all('tr'):
all_td =tr.find_all('td')
key = all_td[0].get_text().split(':')[0]
value = all_td[1].get_text()
if key != '\xa0':
clean_matches[key]=value
if(len(all_td)>2):
key = all_td[2].get_text().split(':')[0]
value = all_td[3].get_text()
if key != '\xa0':
clean_matches[key]=value
return clean_matches
Let's test it and see if it works:
termsheet_to_dict(html_doc)['Notes']
'Adds total books. USD April 2030 & Mar 2036 snr unsec bmk RegS/144A. Baa3/BB+/BB+. Gloco/Active: Citi(log)/JPM(B&D), passive: BNPP/DB/Miz/SMBC. IPTs 5yr T+265 area, L10yr T+290 area. Launch 750m 5yr at T+235, 1bn 10yr at T+260. UST 4.000% due Mar-2030 @ 100-02 / 3.985% / HR 95%, UST 4.625% due Feb-2035 @ 102-02 / 4.364% / HR 93%. Combined books 7bn.\n'
Let's extract all data for all headlines:
result = []
index = pd.DataFrame(headlines, columns=['storyId']).values.tolist()
for i, storyId in enumerate(index):
story = ld.news.get_story(storyId[0])
x = termsheet_to_dict(story)
if x:
result.append(x)
df = pd.DataFrame(result)
df.head()
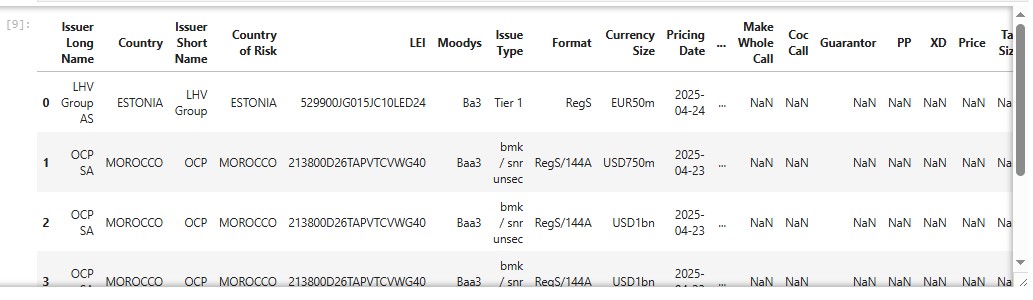
df['Issue Type'].value_counts()
Issue Type
bmk / snr unsec 38
bmk / snr unsec 12
bmk 11
snr unsec 9
bmk / snr unsec / sukuk 8
bmk / Tier 2 4
snr unsec / sukuk 3
Tier 1 2
hybrid / bmk 2
bmk / sukuk 2
bmk / Tier 1 1
bmk / snr sec 1
covered 1
bmk / covered 1
snr unsec 1
bmk / snr unsec / sukuk 1
bmk / sukuk / Tier 1 1
Name: count, dtype: int64What about a specific country?
df[df['Country']=='MOROCCO']['Issue Type'].value_counts()
Issue Type
bmk / snr unsec 6
bmk 4
snr unsec 2
Name: count, dtype: int64
Conclusion
You can experiment further by changing the original headline search query, for example, by including the RIC into your request.