| Last update | Jan 2026 |
| Environment | Windows |
| Language | C# |
| Compilers | Microsoft Visual Studio 2022 |
| Prerequisites | DSS login, internet access, having done the previous tutorials |
| Source code | Download .Net SDK Tutorials Code |
Tutorial purpose
This is the seventh tutorial in a series of .Net SDK tutorials. It is assumed that the reader has acquired the knowledge delivered in the previous tutorials before following this one.
In this tutorial we build on the previous two by overcoming the limit on the number of instrument identifiers:
- Manage an instrument list larger than the extraction limit, using loops.
- Like the previous one, this sample also contains 2 extraction requests, one with the ExtractWithNotes endpoint, the other with the ExtractRaw endpoint, to illustrate the differences between the two.
Extraction limits vary depending on the type of requested data, from 500 to 150000 instruments. This code example is for an End of Day request where the limit is 75000 instruments (150000 after chain expansion). Refer to the DataScope User Guide for all the details on the limits that apply by extraction type, or see them online.
In the tutorial we do not actually use such a large list of instruments; instead we simulate a lower limit, to avoid consuming too much (billable) data. For more information, refer to section: Important warning on data usage.
Table of contents
- Getting ready
- Important warning on data usage
- Understanding the code
- DssClient.cs
- Program.cs
- Member declarations
- Creating the instrument list by reading an input file
- Creating the field name array
- Creating and running the On Demand extractions, retrieving the data
- Variant 1, using ExtractWithNotes:
- Extract and treat JSON data
- Variant 2, using ExtractRaw::
- Extract and treat compressed data
- Post extraction code
- Code run results
- Understanding the refactored version
- Conclusions
Getting ready
Opening the solution
The code installation was done in Tutorial 1.
Opening the solution is similar to what was done in the previous tutorials:
- Navigate to the \DSS REST API\Tutorial 7\Learning folder.
- Double click on the solution file rest_api_bulk_looping.sln to open it in Microsoft Visual Studio.
Referencing the DSS SDK
Before anything else, you must reference the DSS REST API .Net SDK in the Microsoft Visual Studio project.
Important: this must be done for every single tutorial, for both the learning and refactored versions.
This was explained in the tutorial 2; please refer to it for instructions.
Viewing the C# code
In Microsoft Visual Studio, in the Solution Explorer, double click on Program.cs and on DssClient.cs to display both file contents. Each file will be displayed in a separate tab.
Setting the user account
Before running the code, you must replace YourUserId with your DSS user name, and YourPassword with your DSS password, in these 2 lines of Program.cs:
private static string dssUserName = "YourUserId";
private static string dssUserPassword = "YourPassword";
Important reminder: this must be done for every single tutorial, for both the learning and refactored versions.
Failure to do so will result in an error at run time (see Tutorial 1 for more details).
Important warning on data usage
DSS data request quota
DSS accounts have a quota of instruments that can be requested during a defined time period. The DSS subscription fees are proportional to the size of the quota. If the quota is reached, excess fees will be due. That situation must be avoided !
Data usage can be displayed in the DSS web GUI:
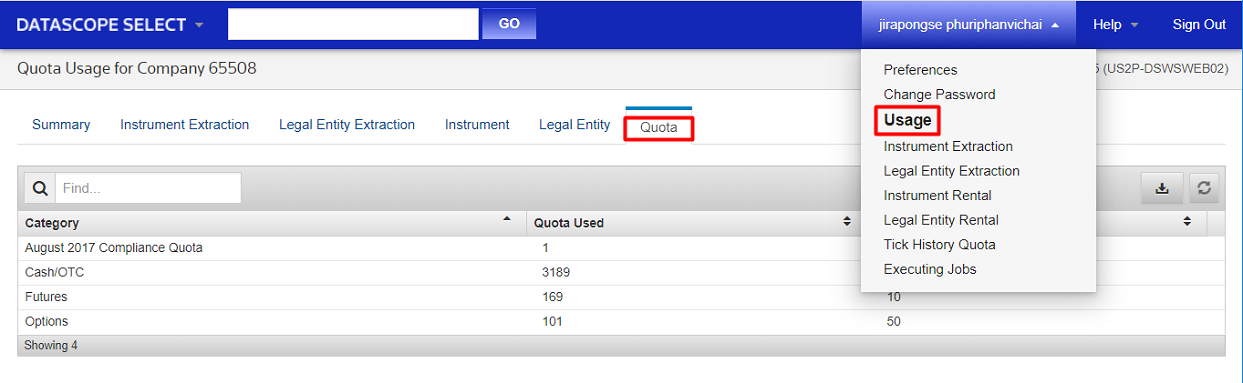
Contact your local account manager or sales specialist if you have queries on your DSS account quota or usage.
Instrument list files delivered with the tutorials
This tutorial (and the previous one) handle large instrument lists, read from a file.
Care must be exercised when running these tutorials, to avoid over consuming data.
For this reason, several files are delivered with the tutorials code:
- DSS_API_1500_input_file.csv
- DSS_API_60_input_file.csv
- DSS_API_10_input_file.csv
The first one contains 1500 valid instrument identifiers, the second one 60, the last one only contains 10.
The text and illustrations that follow use the larger file. To avoid consuming too much data, we recommend you use the smaller file for your own tests, which will deliver similar results.
Understanding the code
We shall only describe what is new versus the previous tutorials.
DssClient.cs
This is the same as the refactored version of Tutorial 6, except for the leading comment.
No additional explanations are required as the rest of the code was described in the previous tutorial.
Program.cs
 Member declarations
Member declarations
We add one declaration, the maximum size of an instrument identifier list DSS can handle in one request:
private static int maxDssIdentifiersListSize = 75000;
Extraction limits vary depending on the type of requested data, from 500 to 150000 instruments. This code example is for an End of Day request where the limit is 75000 instruments (150000 after chain expansion). Refer to the DataScope User Guide for all the details on the limits that apply by extraction type.
As stated in the previous tutorial, to avoid consuming too much data for tests, we recommend you use a small input file:
private static string instrumentIdentifiersInputFile = inputDirectory + "DSS_API_10_input_file.csv";
For an explanation why, refer to the previous section: Important warning on data usage.
The purpose of this tutorial is to manage very large instrument lists. To test the algorithm without consuming huge amounts of data, simulate a lower limit by setting a lower value for maxDssIdentifiersListSize, smaller than the number of instruments in the input file, like:
private static int maxDssIdentifiersListSize = 7;
For production code set the value back to 75000 !
Creating the instrument list by reading an input file
Like in the previous tutorial’s learning version we first create a list for the instrument identifiers, and populate it from the input file. This list will contain all the instrument identifiers, even if there are more than the 75000 DSS can handle in one request:
List<InstrumentIdentifier> instrumentIdentifiersList =
PopulateInstrumentIdentifiersListFromFile(instrumentIdentifiersInputFile, errorOutputFile);
Later in the code we will extract slices of 75000 instrument identifiers from this full list. As in C# it is easier to create sub-lists from a large list than sub-arrays from a large array, we don’t want to convert the list to an array at this stage. That is why our helper method returns a list, contrary to the helper method in the previous tutorial’s refactored version, which returned an array. Apart from this small difference, the methods are the same:
static List<InstrumentIdentifier> PopulateInstrumentIdentifiersListFromFile(
string instrumentIdentifiersInputFile, string errorOutputFile)
{
//Open the input file:
StreamReader sr = new StreamReader(instrumentIdentifiersInputFile);
//Initialise the error output file:
StreamWriter sw = new StreamWriter(errorOutputFile, true);
sw.WriteLine("List of errors found in input file: " + instrumentIdentifiersInputFile + "\n");
//Instead of an array (of defined length), create a list for the instrument identifiers.
//We do this because:
// we don't know how many instruments are in the file,
// we filter the file entries, to only keep the validated ones.
//Create the empty instrument identifiers list:
List<InstrumentIdentifier> instrumentIdentifiersList = new List<InstrumentIdentifier> ();
//Populate the list, reading one line at a time from the file:
int fileLineNumber = 0;
string fileLine = string.Empty;
bool commaExistsInFileLine = false;
string identifierTypeString = string.Empty;
string identifierCodeString = string.Empty;
IdentifierType identifierType;
int i = 0;
//Loop through all lines until we get to the end of the file:
bool endOfFile = false;
while (!endOfFile)
{
Errors errorCode = Errors.NoError;
//Read one line of the file, test if end of file:
fileLine = sr.ReadLine();
endOfFile = (fileLine == null);
if (endOfFile && fileLineNumber == 0) { errorCode = Errors.EmptyFile; };
fileLineNumber++;
//Parse the file line to extract the comma separated instrument type and code:
if (errorCode == Errors.NoError && !endOfFile)
{
commaExistsInFileLine = (fileLine.IndexOf(",") >= 0);
if (commaExistsInFileLine)
{
string[] splitLine = fileLine.Split(new char[] { ',' });
identifierTypeString = splitLine[0];
identifierCodeString = splitLine[1];
}
else
{
errorCode = Errors.BadLineFormat; //Missing comma
identifierTypeString = string.Empty;
identifierCodeString = string.Empty;
}
}
if (identifierTypeString == string.Empty && errorCode == Errors.NoError)
{ errorCode = Errors.EmptyType; }
if (identifierCodeString == string.Empty && errorCode == Errors.NoError)
{ errorCode = Errors.EmptyCode; }
identifierType = IdentifierType.NONE;
if (errorCode == Errors.NoError && !endOfFile)
{
//DSS can handle many types, here we only handle a subset:
switch (identifierTypeString)
{
case "CHR": identifierType = IdentifierType.ChainRIC; break;
case "CIN": identifierType = IdentifierType.Cin; break;
case "COM": identifierType = IdentifierType.CommonCode; break;
case "CSP": identifierType = IdentifierType.Cusip; break;
case "ISN": identifierType = IdentifierType.Isin; break;
case "RIC": identifierType = IdentifierType.Ric; break;
case "SED": identifierType = IdentifierType.Sedol; break;
case "VAL": identifierType = IdentifierType.Valoren; break;
case "WPK": identifierType = IdentifierType.Wertpapier; break;
default: errorCode = Errors.UnknownIdentifier; break;
}
}
if (errorCode == Errors.NoError && !endOfFile)
{
//Add validated instrument identifier into our list:
instrumentIdentifiersList.Add(new InstrumentIdentifier
{
IdentifierType = identifierType,
Identifier = identifierCodeString
});
Console.WriteLine("Line " + fileLineNumber + ": " +
identifierTypeString + " " + identifierCodeString + " loaded into array [" + i + "]");
i++;
}
if (errorCode != Errors.NoError)
{
DebugPrintAndWriteToFileErrorMessage(
errorCode, fileLineNumber, fileLine, identifierTypeString, sw);
}
} //End of while loop
sr.Close();
sw.Close();
return instrumentIdentifiersList;
}
The outputs of this method, for successfully added instrument identifiers, are exactly the same as for the previous tutorial:
...
Line 1500: RIC ALVG.DE loaded into array [1497]
Line 1501: RIC IBM.N loaded into array [1498]
Line 1502: RIC 0001.HK loaded into array [1499]
...
The outputs of this method, for invalid lines in the input file, are exactly the same as for the previous tutorial:
...
ERROR line 1506: unknown identifier type: Junk
ERROR line 1507: missing identifier type in line: ,Junk
ERROR line 1508: missing identifier code in line: Junk,
ERROR line 1509: bad line format: Junk
ERROR line 1510: missing identifier type in line: ,
ERROR line 1511: missing identifier code in line: CSP,,
...
Same goes for the error file which contains all the ERROR messages.
Similarly to the previous tutorial, this is followed with a check on the number of valid instrument identifiers:
int validIdentifiersCount = instrumentIdentifiersList.Count();
if (validIdentifiersCount == 0)
{
DebugPrintAndWaitForEnter("Exit program due to no identifiers in the list.");
return; //Exit main program
}
Console.WriteLine("\n" + validIdentifiersCount +
" valid instruments were loaded into an array, outside of DSS,\n" +
"for use in the extraction.");
Result:
...
1500 valid instruments were loaded into an array, outside of DSS,
for use in the extraction.
...
Creating the field name array
To create the field name array we proceed just like in the previous tutorials, calling the helper method we created in Tutorial 2:
string[] requestedFieldNames = CreateRequestedFieldNames();
We will use this array when we define the extraction.
No report template or schedule creation
Like in the previous tutorial, we do not create a:
- Report template, because the On Demand extraction calls implicitly define it.
- Schedule, because an On Demand extraction is on the fly.
Creating and running the On Demand extractions, retrieving the data
This section explains how we code a loop to process all the instruments in several chunks.
We create a big loop, inside which we run one or more On Demand extractions, each immediately followed by whatever data processing or treatment the use case requires. DSS has a limit on the number of instruments in a list. That limit is 75000, we set it in variable maxDssIdentifiersListSize. If the file contains more, we split the list into:
- 1 or more chunks of 75000.
- An eventual remainder.
We run an extraction and process the data for each sub-list, inside a big loop. At each iteration of the loop we:
- Create an instrument identifier sub-list (a subset of the main one).
- Create an on demand EOD extraction for that instrument identifier sub-list.
- Retrieve the data and extraction notes, treat them and save them to file. This is done using 2 code variants, one for JSON formatted data, the other for compressed CSV formatted data.
Let us look at the code ...
Determine the number of loops of 75000 instruments:
int loopsToRun = validIdentifiersCount / maxDssIdentifiersListSize;
Determine the number of instruments in the remainder loop:
int sizeOfInstrumentIdentifiersRemainder = validIdentifiersCount % maxDssIdentifiersListSize;
Add a loop for the eventual remainder:
if (sizeOfInstrumentIdentifiersRemainder > 0) { loopsToRun++; }
For testing purposes, display the calculated numbers:
Console.WriteLine("Next we will launch " + loopsToRun +
" on demand EOD pricing extraction(s),\n" +
"each followed by data treatment.\n" +
"The " + loopsToRun + " iteration(s) take into account the " +
maxDssIdentifiersListSize + " instruments limit.");
if (sizeOfInstrumentIdentifiersRemainder > 0)
{
DebugPrintAndWaitForEnter("The last iteration has " + sizeOfInstrumentIdentifiersRemainder +
" instruments.\n");
}
else
{
DebugPrintAndWaitForEnter("The last iteration has " + maxDssIdentifiersListSize + " instruments.\n");
}
As our sample instrument lists have less than 75000 instruments, there will only be 1 iteration of the loop.
To test this part of the code without using an instrument identifier list of more than 75000 instruments, we can change the value of maxDssIdentifiersListSize (do not do this in production).
Setting it to 1000, with an input file of 1500 instruments, we get:
...
1500 valid instruments were loaded into a list, outside of DSS,
for use in the extraction.
We also created an array of field names, outside of DSS.
Next we will launch 2 on demand EOD pricing extraction(s),
each followed by data treatment.
The 2 iteration(s) take into account the 1000 instruments limit.
The last iteration has 500 instruments.
Setting it to 7, with an input file of 10 instruments, we get:
...
10 valid instruments were loaded into a list, outside of DSS,
for use in the extraction.
We also created an array of field names, outside of DSS.
Next we will launch 2 on demand EOD pricing extraction(s),
each followed by data treatment.
The 2 iteration(s) take into account the 7 instruments limit.
The last iteration has 3 instruments.
Before the loop, declare some helper variables:
IDssEnumerable<ExtractionRow> extractionDataRows;
int bigLoopIteration = 1;
int firstListElementIndex = 0;
int numberOfListElements = 0;
To extract slices of 75000 instrument identifiers from our full list we use 2 variables:
- firstListElementIndex: index (in the full list) of the first instrument identifier of the current slice (starts at 0).
- numberOfListElements: number of instrument identifiers in the current slice (75000 or the remainder).
At the start of the loop, determine the values of these 2 variables for the current iteration:
while (bigLoopIteration <= loopsToRun)
{
//Fill the instrument identifiers subset array with a set of instruments,
//either 75000, or less if it is the remainder:
firstListElementIndex = (bigLoopIteration - 1) * maxDssIdentifiersListSize;
if (bigLoopIteration < loopsToRun || sizeOfInstrumentIdentifiersRemainder == 0)
{ numberOfListElements = maxDssIdentifiersListSize; }
else
{ numberOfListElements = sizeOfInstrumentIdentifiersRemainder; }
Extract the sub-list of instrument indentifiers from the full list (this is much easier using lists than arrays):
List<InstrumentIdentifier> instrumentIdentifiersSubList =
instrumentIdentifiersList.GetRange(firstListElementIndex, numberOfListElements);
Convert this list to an array, as this is what the On Demand extraction API call requires:
InstrumentIdentifier[] instrumentIdentifiersSubArray = instrumentIdentifiersSubList.ToArray();
For testing purposes, display the relevant numbers:
Console.WriteLine("Loaded identifiers into a sub array, iteration number: " + bigLoopIteration +
"\nFirst element index: " + firstListElementIndex + " - Number of elements: " +
numberOfListElements);
Going back to the test with a value of 1000 for maxDssIdentifiersListSize, we get a first iteration:
...
Loaded identifiers into a sub array, iteration number: 1
First element index: 0 - Number of elements: 1000
Please be patient and wait for the extraction to complete ...
And at second iteration:
...
Loaded identifiers into a sub array, iteration number: 2
First element index: 1000 - Number of elements: 500
Please be patient and wait for the extraction to complete ...
Extract and treat JSON data
Like in the previous tutorial, we shall run 2 extraction variants:
- The first one uses the ExtractWithNotes endpoint, which delivers the data in JSON format.
- The second one uses the ExtractRaw endpoint, which delivers compressed CSV formatted data.
In real life you would only run one of these, chosen depending on your use case.
To run the extraction we call our helper method, like in the previous tutorial:
ExtractionResult extractionResult =
dssClient.CreateAndRunEodPricingExtraction(instrumentIdentifiersSubArray, requestedFieldNames);
extractionDataRows = extractionResult.Contents;
Finally we process the data from this extraction, using the helper method from the previous tutorial:
if (bigLoopIteration == 1)
{ DisplayAndLogExtractedDataFieldNames(dataOutputFile, extractionDataRows); }
DisplayAndLogExtractedDataFieldValues(dataOutputFile, extractionDataRows);
Note we only display the field names at the first iteration, as they will always be the same.
The results on screen are the same as in the previous tutorial (except that they may come in one or several iterations, depending on the instrument identifier list size, and the value of maxDssIdentifiersListSize).
Extract and treat compressed data
To run the extraction for compressed CSV data, we call our helper method, like in the previous tutorial:
RawExtractionResult rawExtractionResult =
dssClient.CreateAndRunEodPricingRawExtraction(instrumentIdentifiersSubArray, requestedFieldNames);
Then we process the data from this extraction, using the helper method from the previous tutorial:
dssClient.SaveCompressedData(rawExtractionResult, gzipDataOutputFile);
DisplayAndLogAndAnalyzeRawExtractionNotes(gzipNotesOutputFile, errorOutputFile, rawExtractionResult);
Post extraction code
After the extractions, the loop ends:
//Increment the big while loop to process the next set of identifiers:
bigLoopIteration++;
}
A final message signals that all extractions were completed:
DebugPrintAndWaitForEnter("All extractions completed.");
...
All extractions completed.
Press Enter to continue
No cleaning up
As stated in the 2 previous tutorials, cleanup on the DSS server is not required, as there is nothing to delete in this case.
Full code
The full code can be displayed by opening the appropriate solution file in Microsoft Visual Studio.
Summary
List of the main steps in the code:
- Authenticate by creating an extraction context.
- Check input file and output directory existence, clear output files.
- Create an array of financial instrument identifiers, populate it from a file. Manage and log errors.
- Create an array of field names.
- Inside a big loop:
- Create a sub-list of financial instrument identifiers, convert it to an array.
- Create an extraction.
- Run the extraction, wait for it to complete. Retrieve the extracted data and extraction notes, display them and write them to files.
- Variant of step 5.3, for compressed data.
We do not create a report template or schedule, and there is no need to cleanup.
Code run results
Build and run
Don’t forget to reference the DSS SDK, and to set your user account in Program.cs !
Successful run
The following is a run using the largest input file, with maxDssIdentifiersListSize set to 1000. Remember this is only for testing, in production maxDssIdentifiersListSize would be set to its real value of 75000. Remember: 75000 is the limit for End of Day requests. Refer to the DataScope User Guide for all the details on the limits that apply by extraction type.
After running the program, and pressing the Enter key when prompted, the final result should look like this:
Returned session token: <token>
Press Enter to continue
Cleared data output file C:\DSS REST API\DSS_API_tutorial_7l_output.txt
Cleared notes output file C:\DSS REST API\DSS_API_tutorial_7l_notes.txt
Cleared error output file C:\DSS REST API\DSS_API_tutorial_7l_errors.txt
Cleared compressed data output file C:\DSS REST API\DSS_API_tutorial_7l_gzipOutput.csv.gz
Cleared compressed data notes output file C:\DSS REST API\DSS_API_tutorial_7l_gzipNotes.txt
Press Enter to continue
ERROR line 1: unknown identifier type: Identifier Type
Line 2: CSP 911760HW9 loaded into array [0]
Line 3: CSP 911760JQ0 loaded into array [1]
Line 4: CSP 911760JR8 loaded into array [2]
Line 5: CSP 911760HP4 loaded into array [3]
Line 6: CSP 31359KUL9 loaded into array [4]
Line 7: CSP 31359KUJ4 loaded into array [5]
Line 8: CSP 31359KUK1 loaded into array [6]
Line 9: CSP 232928AE1 loaded into array [7]
Line 10: CSP 79548KHM3 loaded into array [8]
Line 11: CSP 911760JT4 loaded into array [9]
Line 12: CSP 911760KF2 loaded into array [10]
Line 13: CSP 911760KG0 loaded into array [11]
Line 14: CSP 92260MAP8 loaded into array [12]
Line 15: CSP 31359KGH4 loaded into array [13]
Line 16: CSP 31359KGJ0 loaded into array [14]
Line 17: CSP 31359KGK7 loaded into array [15]
Line 18: CSP 911760KT2 loaded into array [16]
Line 19: CSP 911760KU9 loaded into array [17]
Line 20: CSP 911760LB0 loaded into array [18]
...
This goes on with the next instruments of the file ...
The instrument identifiers import messages end like this, with quite a few errors generated by the wrongly formatted lines we included in the input file to test the error handling:
...
Line 1495: CSP 31352DCM0 loaded into array [1493]
Line 1496: CSP 31352DCN8 loaded into array [1494]
Line 1497: CSP 31352DCR9 loaded into array [1495]
Line 1498: CSP 31352JRV1 loaded into array [1496]
ERROR line 1499: bad line format: #RICs:
Line 1500: RIC ALVG.DE loaded into array [1497]
Line 1501: RIC IBM.N loaded into array [1498]
Line 1502: RIC 0001.HK loaded into array [1499]
ERROR line 1503: bad line format:
ERROR line 1504: bad line format: #Lines for error handling tests:
ERROR line 1505: unknown identifier type: Junk
ERROR line 1506: unknown identifier type: Junk
ERROR line 1507: missing identifier type in line: ,Junk
ERROR line 1508: missing identifier code in line: Junk,
ERROR line 1509: bad line format: Junk
ERROR line 1510: missing identifier type in line: ,
ERROR line 1511: missing identifier code in line: CSP,,
ERROR line 1512: missing identifier code in line: CSP,
ERROR line 1513: missing identifier type in line: ,CSP
ERROR line 1514: bad line format: CSP
ERROR line 1515: unknown identifier type: Junk
ERROR line 1516: unknown identifier type: Junk
ERROR line 1517: missing identifier code in line: RIC,,
ERROR line 1518: missing identifier code in line: RIC,
ERROR line 1519: missing identifier type in line: ,RIC
ERROR line 1520: bad line format: RIC
ERROR line 1521: unknown identifier type: Junk
ERROR line 1522: unknown identifier type: Junk
1500 valid instruments were loaded into a list, outside of DSS,
for use in the extraction.
We also created an array of field names, outside of DSS.
...
This is followed by the first iteration of the big loop, and the display of the returned field names:
...
Next we will launch 2 on demand EOD pricing extraction(s),
each followed by data treatment.
The 2 iteration(s) take into account the 1000 instruments limit.
The last iteration has 500 instruments.
Press Enter to continue
Loaded identifiers into a sub array, iteration number: 1
First element index: 0 - Number of elements: 1000
Please be patient and wait for the extraction to complete ...
Returned list of field names:
Instrument ID,Security Description,Universal Close Price Date,Universal Close Price,
Press Enter to continue
...
Next come the data values for this first set of 1000 instruments:
...
Returned field values:
======================
911760HW9, VNDE 963 1Z Z Fix, 6/8/2022 12:00:00 AM, 102.929810999
911760JQ0, VNDE 963 3 Vari, 6/8/2022 12:00:00 AM, 103.652327784
911760JR8, VNDE 963 4 Vari, ,
911760HP4, VNDE 963 IO Excess Vari IONtl, ,
31359KUL9, FN 96W3 X Excess Vari IONtl, ,
31359KUJ4, FN 96W3 A6 Seq Vari, ,
31359KUK1, FN 96W3 AL Seq Vari, ,
232928AE1, DRFC 94K1 A3 Fix, ,
79548KHM3, SBMSI7 936A B2 Sub Vari, 6/8/2022 12:00:00 AM, 99.227791996
911760JT4, VNDE 971A 1A Vari, 6/8/2022 12:00:00 AM, 102.071886385
...
This goes on with all the returned data for the first iteration, followed by the statistics and messages for this first slice:
...
31358H5N1, FN 91115 MM Supp Lottery Fix, ,
31358H5P6, FN 91115 N Strip Fix Ioette, ,
31358JRQ6, FN 91116 E PAC Fix, ,
31358JSJ1, FN 91116 V Supp Fix Ioette, ,
31358JCH2, FN 91118 LL Supp Lottery Fix C, ,
31358JCJ8, FN 91118 M Supp PO Cmpnt, ,
31358JBP5, FN 91119 N Strip Fix Ioette, ,
31358JBJ9, FN 91119 Z Supp Z Fix, ,
31358FM55, FN 9112 H PAC1 Fix, ,
31358FM63, FN 9112 J PAC1 Fix Ioette, ,
Extraction completed.
Number of data rows: 1000
Number of valid (non empty) data rows: 987
Output was also written to file.
Press Enter to continue
...
After that, the extraction notes for this extraction are displayed, followed by their analysis results.
The second extraction is then performed, and the compressed data saved to file. After that, the extraction notes for the second extraction are displayed, followed by their analysis results.
This is followed by the next iteration of the big loop, and the display of the data values (field names are not displayed):
...
Loaded identifiers into a sub array, iteration number: 2
First element index: 1000 - Number of elements: 500
Please be patient and wait for the extraction to complete ...
Returned field values:
======================
31358JDZ1, FN 91120 K Strip Fix Ioette, ,
31358JEA5, FN 91120 Z Supp Z Fix, ,
31358JEQ0, FN 91122 N PAC1 Fix, ,
31358JER8, FN 91122 O PAC1 Fix Ioette, ,
31358JSN2, FN 91123 EB PAC1 Fix, ,
31358JGN5, FN 91123 G PAC1 Fix Ioette, ,
31358JGY1, FN 91123 Q Strip Fix Ioette, ,
...
This goes on with all the returned data for that iteration, followed by the statistics, messages and notes for that slice.
The program ends after the last slice.
We can then check out the output files; their contents reflect what was displayed on screen, and is the same as what was generated by the previous tutorial (except that data values will have changed if you ran it on a different day).
Potential errors and solutions
If the user name and password were not set properly, an error will be returned. See Tutorial 1 for details.
Understanding the refactored version
Explanations
DSS client helper class file: DssClient.cs
The maxDssIdentifiersListSize declaration has been moved here (from Program.cs), as it is specific to DSS, and not likely to change:
public int maxDssIdentifiersListSize = 75000;
There are no other changes.
Main program file: Program.cs
As the maxDssIdentifiersListSize declaration has been moved to the DssClient.cs class, we expose it here:
int maxDssIdentifiersListSize = dssClient.maxDssIdentifiersListSize;
Comments that explicitly mentioned the number 75000 (for readability) were modified to mention the variable name maxDssIdentifiersListSize.
Inside the big loop, we call a helper method to populate the instrument identifiers sub-array:
InstrumentIdentifier[] instrumentIdentifiersSubArray =
PopulateInstrumentIdentifiersSubArray(
bigLoopIteration, loopsToRun,
maxDssIdentifiersListSize, sizeOfInstrumentIdentifiersRemainder,
instrumentIdentifiersList);
This helper method is declared in Program.cs, after the main code:
static InstrumentIdentifier[] PopulateInstrumentIdentifiersSubArray(
int bigLoopIteration, int loopsToRun,
int maxDssIdentifiersListSize, int sizeOfInstrumentIdentifiersRemainder,
List<InstrumentIdentifier> instrumentIdentifiersList)
{
//Fill the instrument identifiers subset array with a set of instruments,
//either maxDssIdentifiersListSize, or less if it is the remainder:
int firstListElementIndex = (bigLoopIteration - 1) * maxDssIdentifiersListSize;
int numberOfListElements = 0;
if (bigLoopIteration < loopsToRun || sizeOfInstrumentIdentifiersRemainder == 0)
{ numberOfListElements = maxDssIdentifiersListSize; }
else
{ numberOfListElements = sizeOfInstrumentIdentifiersRemainder; }
List<InstrumentIdentifier> instrumentIdentifiersSubList =
instrumentIdentifiersList.GetRange(firstListElementIndex, numberOfListElements);
Console.WriteLine("Loaded identifiers into a sub array, iteration number: " + bigLoopIteration +
"\nFirst element index: " + firstListElementIndex +
" - Number of elements: " + numberOfListElements);
//Convert the sublist to an array, as that is what the API needs.
InstrumentIdentifier[] instrumentIdentifiersSubArray = instrumentIdentifiersSubList.ToArray();
return instrumentIdentifiersSubArray;
}
Note also that this helper method includes the list conversion to an array.
Full code
The full code can be displayed by opening the appropriate solution file in Microsoft Visual Studio.
Build and run
Don’t forget to reference the DSS SDK, and to set your user account in Program.cs !
Conclusions
This tutorial showed how very large instrument identifiers lists can be easily handled inside a loop, to manage the maximum extraction size supported by the DSS servers.
Extraction limits vary depending on the type of requested data, from 500 to 150000 instruments. This code example is for an End of Day request where the limit is 75000 instruments (150000 after chain expansion). Refer to the DataScope User Guide for all the details on the limits that apply by extraction type.
For large instrument lists, using an endpoint that delivers compressed data, like was illustrated in the second extraction in this sample, can be an advantage.